 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Vision to Assistance: Gaze and Vision-Enabled Adaptive Control for a Back-Support Exoskeleton
Feb 04, 2026Back-support exoskeletons have been proposed to mitigate spinal loading in industrial handling, yet their effectiveness critically depends on timely and context-aware assistance. Most existing approaches rely either on load-estimation techniques (e.g., EMG, IMU) or on vision systems that do not directly inform control. In this work, we present a vision-gated control framework for an active lumbar occupational exoskeleton that leverages egocentric vision with wearable gaze tracking. The proposed system integrates real-time grasp detection from a first-person YOLO-based perception system, a finite-state machine (FSM) for task progression, and a variable admittance controller to adapt torque delivery to both posture and object state. A user study with 15 participants performing stooping load lifting trials under three conditions (no exoskeleton, exoskeleton without vision, exoskeleton with vision) shows that vision-gated assistance significantly reduces perceived physical demand and improves fluency, trust, and comfort. Quantitative analysis reveals earlier and stronger assistance when vision is enabled, while questionnaire results confirm user preference for the vision-gated mode. These findings highlight the potential of egocentric vision to enhance the responsiveness, ergonomics, safety, and acceptance of back-support exoskeletons.
Augmenting Neural Networks-based Model Approximators in Robotic Force-tracking Tasks
Sep 10, 2025As robotics gains popularity, interaction control becomes crucial for ensuring force tracking in manipulator-based tasks. Typically, traditional interaction controllers either require extensive tuning, or demand expert knowledge of the environment, which is often impractical in real-world applications. This work proposes a novel control strategy leveraging Neural Networks (NNs) to enhance the force-tracking behavior of a Direct Force Controller (DFC). Unlike similar previous approaches, it accounts for the manipulator's tangential velocity, a critical factor in force exertion, especially during fast motions. The method employs an ensemble of feedforward NNs to predict contact forces, then exploits the prediction to solve an optimization problem and generate an optimal residual action, which is added to the DFC output and applied to an impedance controller. The proposed Velocity-augmented Artificial intelligence Interaction Controller for Ambiguous Models (VAICAM) is validated in the Gazebo simulator on a Franka Emika Panda robot. Against a vast set of trajectories, VAICAM achieves superior performance compared to two baseline controllers.
Robot Drummer: Learning Rhythmic Skills for Humanoid Drumming
Jul 16, 2025
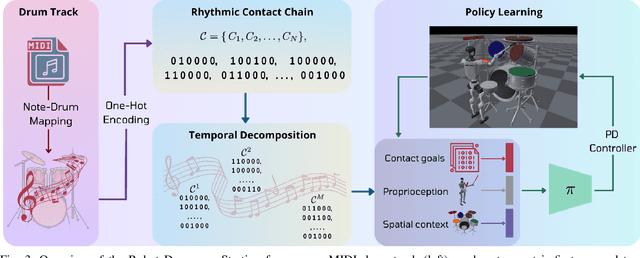

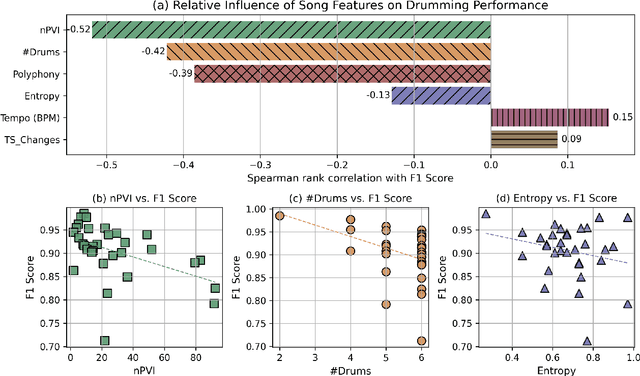
Humanoid robots have seen remarkable advances in dexterity, balance, and locomotion, yet their role in expressive domains such as music performance remains largely unexplored. Musical tasks, like drumming, present unique challenges, including split-second timing, rapid contacts, and multi-limb coordination over performances lasting minutes. In this paper, we introduce Robot Drummer, a humanoid capable of expressive, high-precision drumming across a diverse repertoire of songs. We formulate humanoid drumming as sequential fulfillment of timed contacts and transform drum scores into a Rhythmic Contact Chain. To handle the long-horizon nature of musical performance, we decompose each piece into fixed-length segments and train a single policy across all segments in parallel using reinforcement learning. Through extensive experiments on over thirty popular rock, metal, and jazz tracks, our results demonstrate that Robot Drummer consistently achieves high F1 scores. The learned behaviors exhibit emergent human-like drumming strategies, such as cross-arm strikes, and adaptive stick assignments, demonstrating the potential of reinforcement learning to bring humanoid robots into the domain of creative musical performance. Project page: robotdrummer.github.io
Integrating Reinforcement Learning with Foundation Models for Autonomous Robotics: Methods and Perspectives
Oct 21, 2024



Foundation models (FMs), large deep learning models pre-trained on vast, unlabeled datasets, exhibit powerful capabilities in understanding complex patterns and generating sophisticated outputs. However, they often struggle to adapt to specific tasks. Reinforcement learning (RL), which allows agents to learn through interaction and feedback, offers a compelling solution. Integrating RL with FMs enables these models to achieve desired outcomes and excel at particular tasks. Additionally, RL can be enhanced by leveraging the reasoning and generalization capabilities of FMs. This synergy is revolutionizing various fields, including robotics. FMs, rich in knowledge and generalization, provide robots with valuable information, while RL facilitates learning and adaptation through real-world interactions. This survey paper comprehensively explores this exciting intersection, examining how these paradigms can be integrated to advance robotic intelligence. We analyze the use of foundation models as action planners, the development of robotics-specific foundation models, and the mutual benefits of combining FMs with RL. Furthermore, we present a taxonomy of integration approaches, including large language models, vision-language models, diffusion models, and transformer-based RL models. We also explore how RL can utilize world representations learned from FMs to enhance robotic task execution. Our survey aims to synthesize current research and highlight key challenges in robotic reasoning and control, particularly in the context of integrating FMs and RL--two rapidly evolving technologies. By doing so, we seek to spark future research and emphasize critical areas that require further investigation to enhance robotics. We provide an updated collection of papers based on our taxonomy, accessible on our open-source project website at: https://github.com/clmoro/Robotics-RL-FMs-Integration.
RoboMorph: In-Context Meta-Learning for Robot Dynamics Modeling
Sep 18, 2024



The landscape of Deep Learning has experienced a major shift with the pervasive adoption of Transformer-based architectures, particularly in Natural Language Processing (NLP). Novel avenues for physical applications, such as solving Partial Differential Equations and Image Vision, have been explored. However, in challenging domains like robotics, where high non-linearity poses significant challenges, Transformer-based applications are scarce. While Transformers have been used to provide robots with knowledge about high-level tasks, few efforts have been made to perform system identification. This paper proposes a novel methodology to learn a meta-dynamical model of a high-dimensional physical system, such as the Franka robotic arm, using a Transformer-based architecture without prior knowledge of the system's physical parameters. The objective is to predict quantities of interest (end-effector pose and joint positions) given the torque signals for each joint. This prediction can be useful as a component for Deep Model Predictive Control frameworks in robotics. The meta-model establishes the correlation between torques and positions and predicts the output for the complete trajectory. This work provides empirical evidence of the efficacy of the in-context learning paradigm, suggesting future improvements in learning the dynamics of robotic systems without explicit knowledge of physical parameters. Code, videos, and supplementary materials can be found at project website. See https://sites.google.com/view/robomorph/
Scaling Population-Based Reinforcement Learning with GPU Accelerated Simulation
Apr 08, 2024
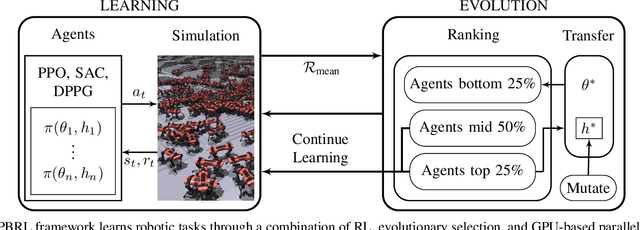
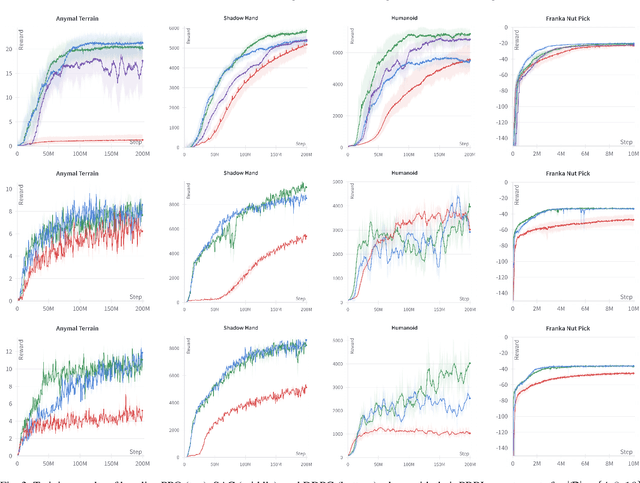
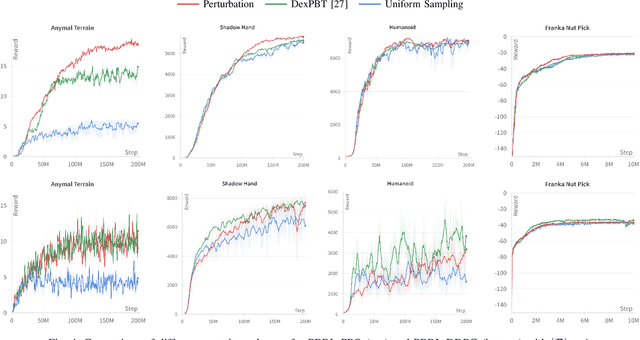
In recent years, deep reinforcement learning (RL) has shown its effectiveness in solving complex continuous control tasks like locomotion and dexterous manipulation. However, this comes at the cost of an enormous amount of experience required for training, exacerbated by the sensitivity of learning efficiency and the policy performance to hyperparameter selection, which often requires numerous trials of time-consuming experiments. This work introduces a Population-Based Reinforcement Learning (PBRL) approach that exploits a GPU-accelerated physics simulator to enhance the exploration capabilities of RL by concurrently training multiple policies in parallel. The PBRL framework is applied to three state-of-the-art RL algorithms -- PPO, SAC, and DDPG -- dynamically adjusting hyperparameters based on the performance of learning agents. The experiments are performed on four challenging tasks in Isaac Gym -- Anymal Terrain, Shadow Hand, Humanoid, Franka Nut Pick -- by analyzing the effect of population size and mutation mechanisms for hyperparameters. The results show that PBRL agents achieve superior performance, in terms of cumulative reward, compared to non-evolutionary baseline agents. The trained agents are finally deployed in the real world for a Franka Nut Pick task, demonstrating successful sim-to-real transfer. Code and videos of the learned policies are available on our project website.
Combining Sampling- and Gradient-based Planning for Contact-rich Manipulation
Oct 07, 2023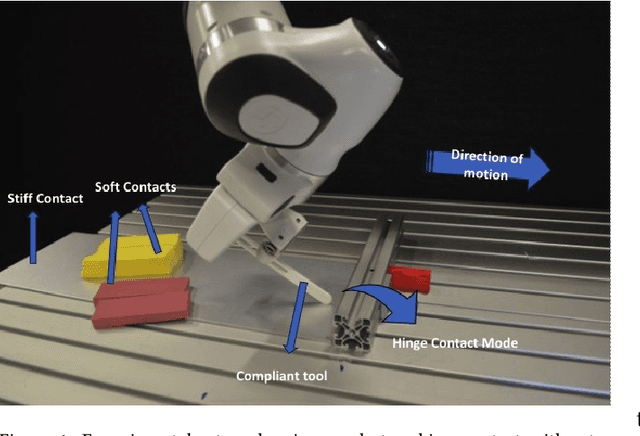
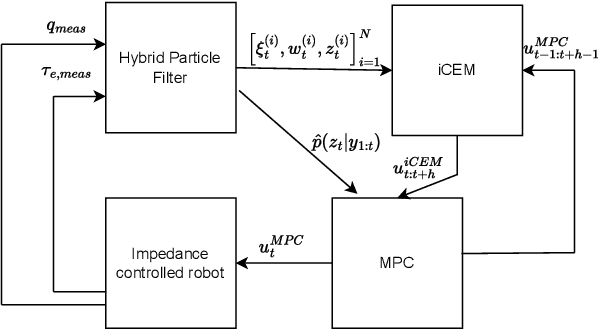
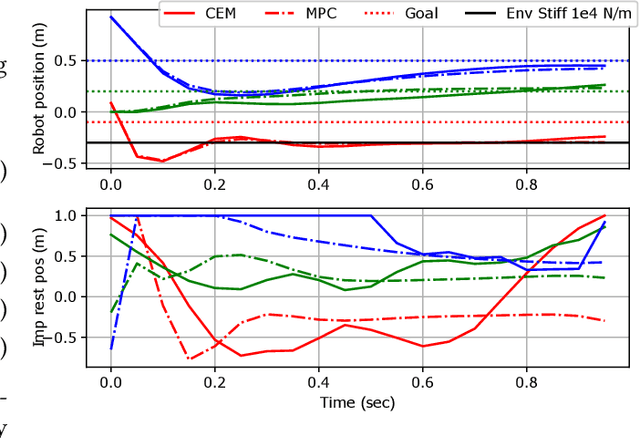
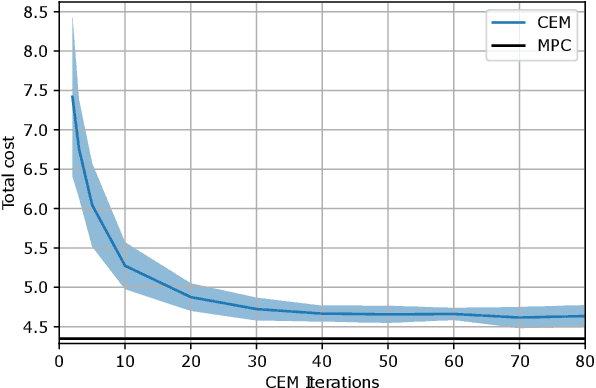
Planning over discontinuous dynamics is needed for robotics tasks like contact-rich manipulation, which presents challenges in the numerical stability and speed of planning methods when either neural network or analytical models are used. On the one hand, sampling-based planners require higher sample complexity in high-dimensional problems and cannot describe safety constraints such as force limits. On the other hand, gradient-based solvers can suffer from local optima and convergence issues when the Hessian is poorly conditioned. We propose a planning method with both sampling- and gradient-based elements, using the Cross-entropy Method to initialize a gradient-based solver, providing better search over local minima and the ability to handle explicit constraints. We show the approach allows smooth, stable contact-rich planning for an impedance-controlled robot making contact with a stiff environment, benchmarking against gradient-only MPC and CEM.
Imitation Learning-based Visual Servoing for Tracking Moving Objects
Sep 14, 2023
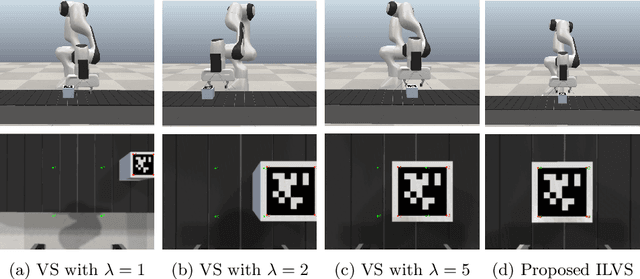
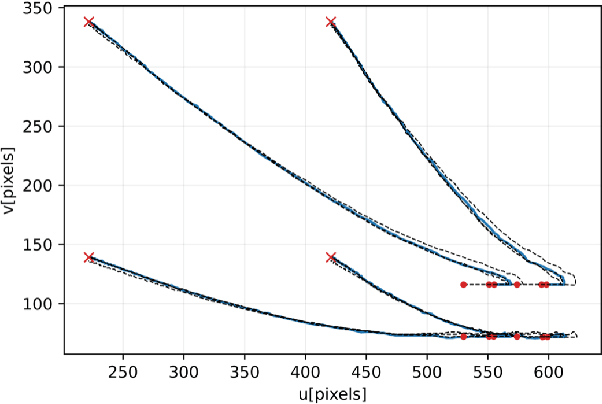
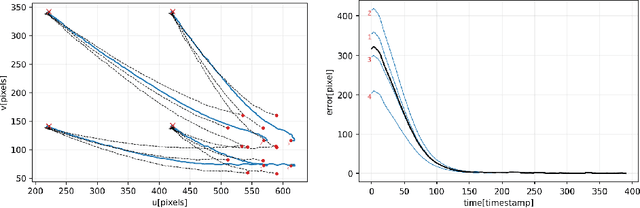
In everyday life collaboration tasks between human operators and robots, the former necessitate simple ways for programming new skills, the latter have to show adaptive capabilities to cope with environmental changes. The joint use of visual servoing and imitation learning allows us to pursue the objective of realizing friendly robotic interfaces that (i) are able to adapt to the environment thanks to the use of visual perception and (ii) avoid explicit programming thanks to the emulation of previous demonstrations. This work aims to exploit imitation learning for the visual servoing paradigm to address the specific problem of tracking moving objects. In particular, we show that it is possible to infer from data the compensation term required for realizing the tracking controller, avoiding the explicit implementation of estimators or observers. The effectiveness of the proposed method has been validated through simulations with a robotic manipulator.
Predicting human motion intention for pHRI assistive control
Jul 20, 2023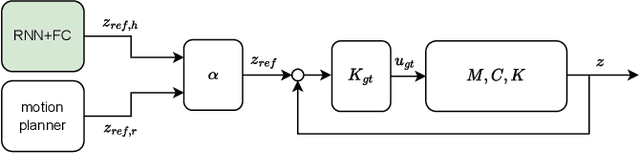



This work addresses human intention identification during physical Human-Robot Interaction (pHRI) tasks to include this information in an assistive controller. To this purpose, human intention is defined as the desired trajectory that the human wants to follow over a finite rolling prediction horizon so that the robot can assist in pursuing it. This work investigates a Recurrent Neural Network (RNN), specifically, Long-Short Term Memory (LSTM) cascaded with a Fully Connected layer. In particular, we propose an iterative training procedure to adapt the model. Such an iterative procedure is powerful in reducing the prediction error. Still, it has the drawback that it is time-consuming and does not generalize to different users or different co-manipulated objects. To overcome this issue, Transfer Learning (TL) adapts the pre-trained model to new trajectories, users, and co-manipulated objects by freezing the LSTM layer and fine-tuning the last FC layer, which makes the procedure faster. Experiments show that the iterative procedure adapts the model and reduces prediction error. Experiments also show that TL adapts to different users and to the co-manipulation of a large object. Finally, to check the utility of adopting the proposed method, we compare the proposed controller enhanced by the intention prediction with the other two standard controllers of pHRI.
Teaching contact-rich tasks from visual demonstrations by constraint extraction
Apr 03, 2023


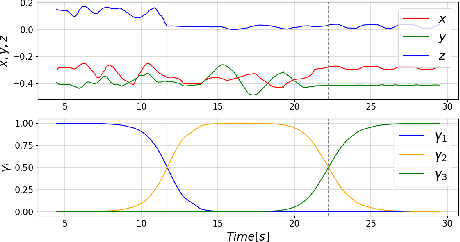
Contact-rich manipulation involves kinematic constraints on the task motion, typically with discrete transitions between these constraints during the task. Allowing the robot to detect and reason about these contact constraints can support robust and dynamic manipulation, but how can these contact models be efficiently learned? Purely visual observations are an attractive data source, allowing passive task demonstrations with unmodified objects. Existing approaches for vision-only learning from demonstration are effective in pick-and-place applications and planar tasks. Nevertheless, accuracy/occlusions and unobserved task dynamics can limit their robustness in contact-rich manipulation. To use visual demonstrations for contact-rich robotic tasks, we consider the demonstration of pose trajectories with transitions between holonomic kinematic constraints, first clustering the trajectories into discrete contact modes, then fitting kinematic constraints per each mode. The fit constraints are then used to (i) detect contact online with force/torque measurements and (ii) plan the robot policy with respect to the active constraint. We demonstrate the approach with real experiments, on cabling and rake tasks, showing the approach gives robust manipulation through contact transitions.