 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Reinforcement Learning with Foundation Models for Autonomous Robotics: Methods and Perspectives
Oct 21, 2024



Foundation models (FMs), large deep learning models pre-trained on vast, unlabeled datasets, exhibit powerful capabilities in understanding complex patterns and generating sophisticated outputs. However, they often struggle to adapt to specific tasks. Reinforcement learning (RL), which allows agents to learn through interaction and feedback, offers a compelling solution. Integrating RL with FMs enables these models to achieve desired outcomes and excel at particular tasks. Additionally, RL can be enhanced by leveraging the reasoning and generalization capabilities of FMs. This synergy is revolutionizing various fields, including robotics. FMs, rich in knowledge and generalization, provide robots with valuable information, while RL facilitates learning and adaptation through real-world interactions. This survey paper comprehensively explores this exciting intersection, examining how these paradigms can be integrated to advance robotic intelligence. We analyze the use of foundation models as action planners, the development of robotics-specific foundation models, and the mutual benefits of combining FMs with RL. Furthermore, we present a taxonomy of integration approaches, including large language models, vision-language models, diffusion models, and transformer-based RL models. We also explore how RL can utilize world representations learned from FMs to enhance robotic task execution. Our survey aims to synthesize current research and highlight key challenges in robotic reasoning and control, particularly in the context of integrating FMs and RL--two rapidly evolving technologies. By doing so, we seek to spark future research and emphasize critical areas that require further investigation to enhance robotics. We provide an updated collection of papers based on our taxonomy, accessible on our open-source project website at: https://github.com/clmoro/Robotics-RL-FMs-Integration.
Experience in Engineering Complex Systems: Active Preference Learning with Multiple Outcomes and Certainty Levels
Feb 27, 2023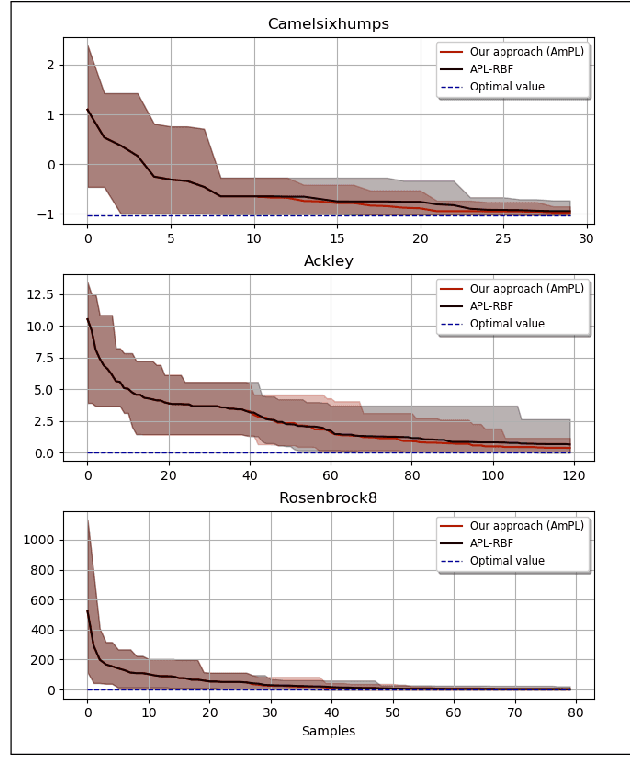
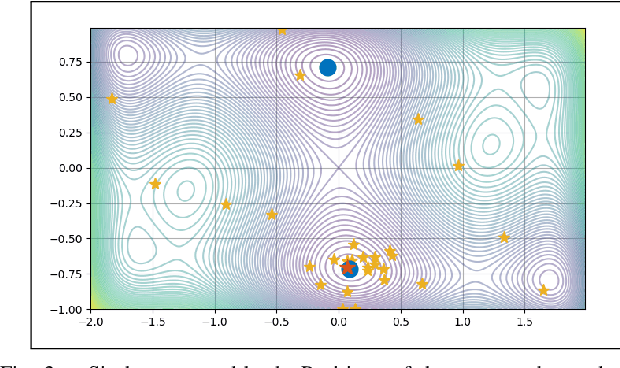
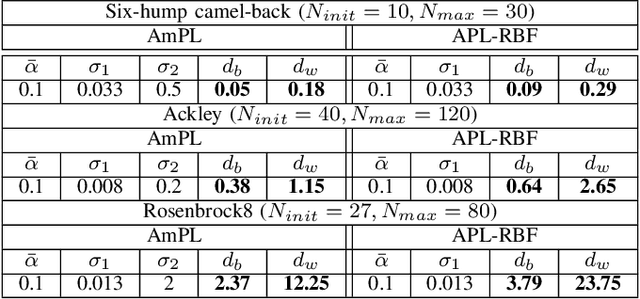
Black-box optimization refers to the optimization problem whose objective function and/or constraint sets are either unknown, inaccessible, or non-existent. In many applications, especially with the involvement of humans, the only way to access the optimization problem is through performing physical experiments with the available outcomes being the preference of one candidate with respect to one or many others. Accordingly, the algorithm so-called Active Preference Learning has been developed to exploit this specific information in constructing a surrogate function based on standard radial basis functions, and then forming an easy-to-solve acquisition function which repetitively suggests new decision vectors to search for the optimal solution. Based on this idea, our approach aims to extend the algorithm in such a way that can exploit further information effectively, which can be obtained in reality such as: 5-point Likert type scale for the outcomes of the preference query (i.e., the preference can be described in not only "this is better than that" but also "this is much better than that" level), or multiple outcomes for a single preference query with possible additive information on how certain the outcomes are. The validation of the proposed algorithm is done through some standard benchmark functions, showing a promising improvement with respect to the state-of-the-art algorithm.