 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings
Oct 10, 2022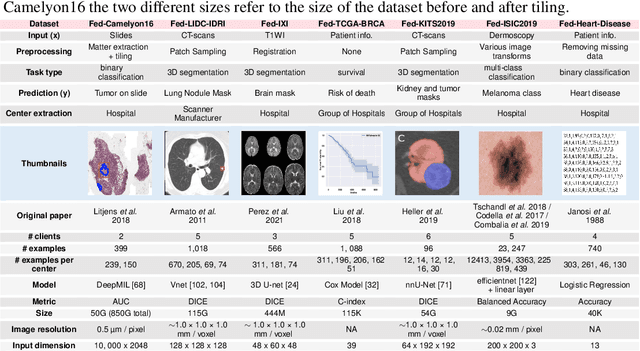
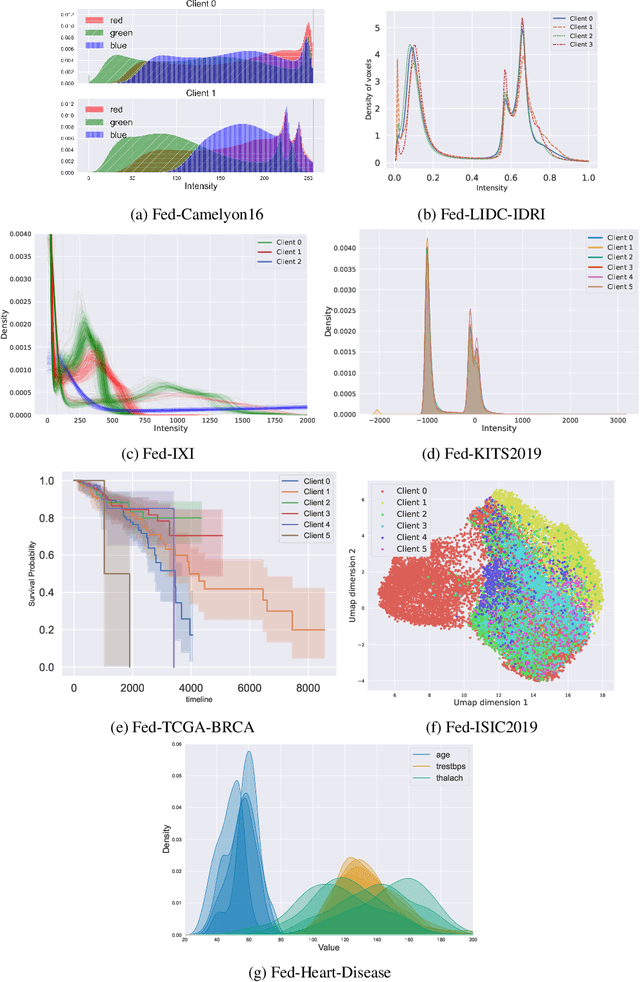
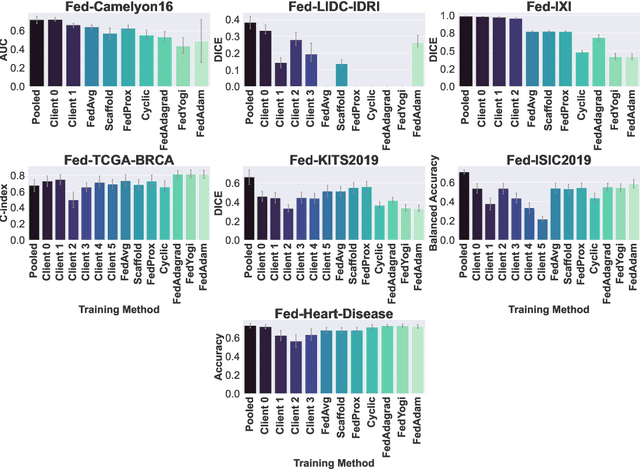

Federated Learning (FL) is a novel approach enabling several clients holding sensitive data to collaboratively train machine learning models, without centralizing data. The cross-silo FL setting corresponds to the case of few ($2$--$50$) reliable clients, each holding medium to large datasets, and is typically found in applications such as healthcare, finance, or industry. While previous works have proposed representative datasets for cross-device FL, few realistic healthcare cross-silo FL datasets exist, thereby slowing algorithmic research in this critical application. In this work, we propose a novel cross-silo dataset suite focused on healthcare, FLamby (Federated Learning AMple Benchmark of Your cross-silo strategies), to bridge the gap between theory and practice of cross-silo FL. FLamby encompasses 7 healthcare datasets with natural splits, covering multiple tasks, modalities, and data volumes, each accompanied with baseline training code. As an illustration, we additionally benchmark standard FL algorithms on all datasets. Our flexible and modular suite allows researchers to easily download datasets, reproduce results and re-use the different components for their research. FLamby is available at~\url{www.github.com/owkin/flamby}.
Optimal Model Averaging: Towards Personalized Collaborative Learning
Oct 25, 2021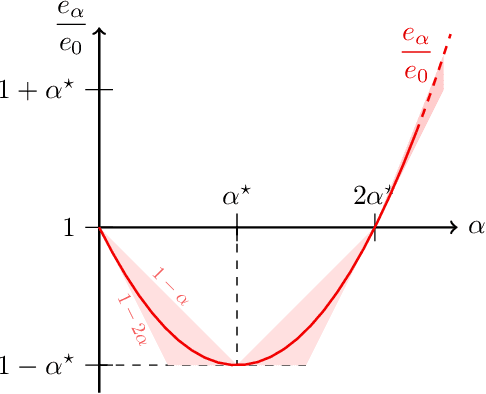
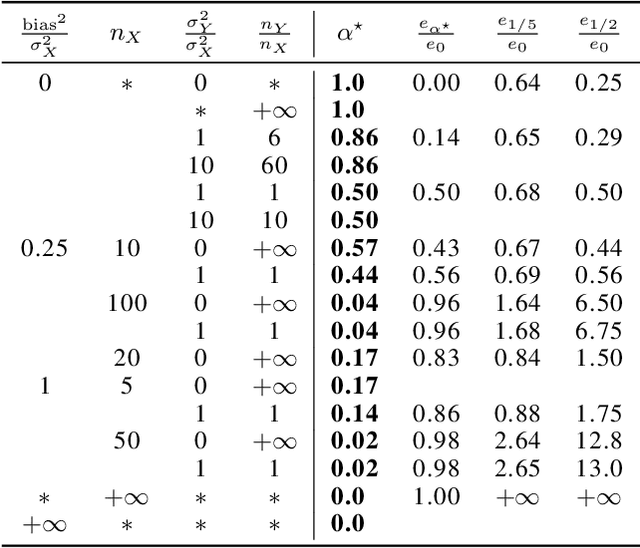
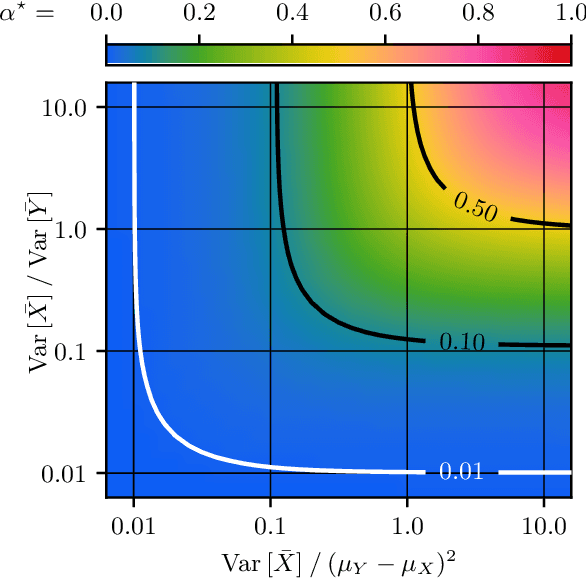
In federated learning, differences in the data or objectives between the participating nodes motivate approaches to train a personalized machine learning model for each node. One such approach is weighted averaging between a locally trained model and the global model. In this theoretical work, we study weighted model averaging for arbitrary scalar mean estimation problems under minimal assumptions on the distributions. In a variant of the bias-variance trade-off, we find that there is always some positive amount of model averaging that reduces the expected squared error compared to the local model, provided only that the local model has a non-zero variance. Further, we quantify the (possibly negative) benefit of weighted model averaging as a function of the weight used and the optimal weight. Taken together, this work formalizes an approach to quantify the value of personalization in collaborative learning and provides a framework for future research to test the findings in multivariate parameter estimation and under a range of assumptions.
WAFFLE: Weighted Averaging for Personalized Federated Learning
Oct 13, 2021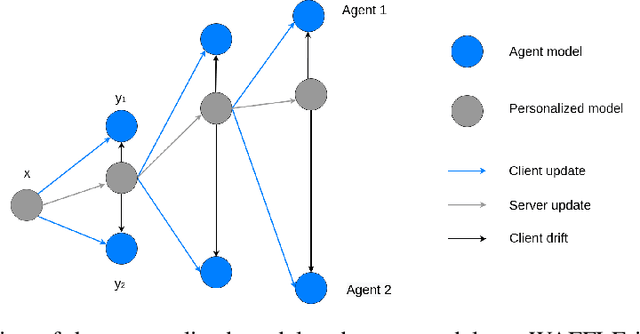
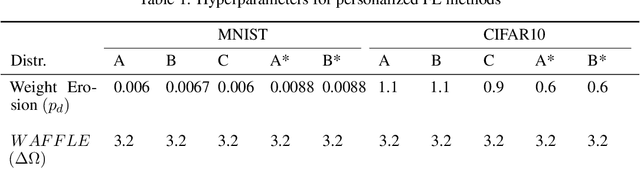

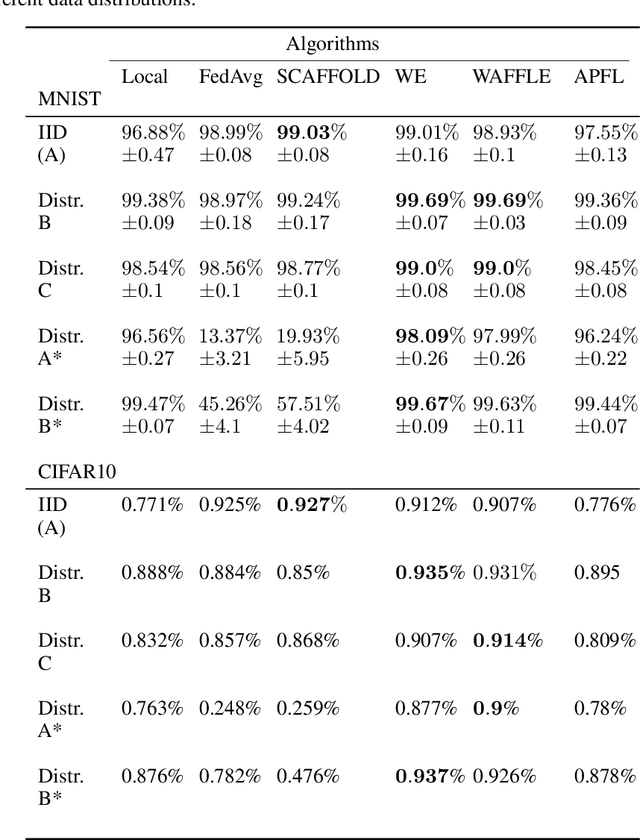
In collaborative or federated learning, model personalization can be a very effective strategy to deal with heterogeneous training data across clients. We introduce WAFFLE (Weighted Averaging For Federated LEarning), a personalized collaborative machine learning algorithm based on SCAFFOLD. SCAFFOLD uses stochastic control variates to converge towards a model close to the globally optimal model even in tasks where the distribution of data and labels across clients is highly skewed. In contrast, WAFFLE uses the Euclidean distance between clients' updates to weigh their individual contributions and thus minimize the trained personalized model loss on the specific agent of interest. Through a series of experiments, we compare our proposed new method to two recent personalized federated learning methods, Weight Erosion and APFL, as well as two global learning methods, federated averaging and SCAFFOLD. We evaluate our method using two categories of non-identical client data distributions (concept shift and label skew) on two benchmark image data sets, MNIST and CIFAR10. Our experiments demonstrate the effectiveness of WAFFLE compared with other methods, as it achieves or improves accuracy with faster convergence.