 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIMusicGuru: Music Assisted Human Pose Correction
Mar 24, 2022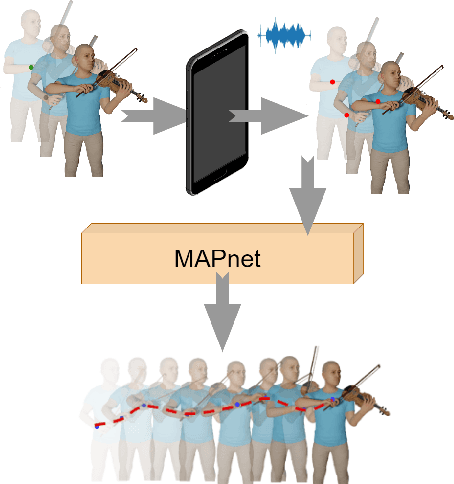
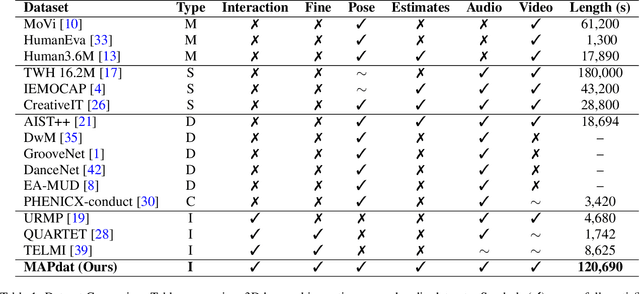
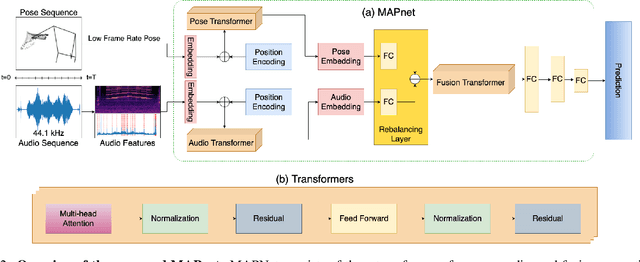
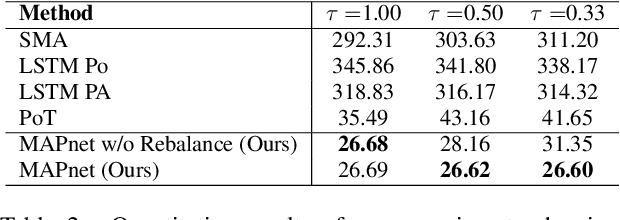
Pose Estimation techniques rely on visual cues available through observations represented in the form of pixels. But the performance is bounded by the frame rate of the video and struggles from motion blur, occlusions, and temporal coherence. This issue is magnified when people are interacting with objects and instruments, for example playing the violin. Standard approaches for postprocessing use interpolation and smoothing functions to filter noise and fill gaps, but they cannot model highly non-linear motion. We present a method that leverages our understanding of the high degree of a causal relationship between the sound produced and the motion that produces them. We use the audio signature to refine and predict accurate human body pose motion models. We propose MAPnet (Music Assisted Pose network) for generating a fine grain motion model from sparse input pose sequences but continuous audio. To accelerate further research in this domain, we also open-source MAPdat, a new multi-modal dataset of 3D violin playing motion with music. We perform a comparison of different standard machine learning models and perform analysis on input modalities, sampling techniques, and audio and motion features. Experiments on MAPdat suggest multi-modal approaches like ours as a promising direction for tasks previously approached with visual methods only. Our results show both qualitatively and quantitatively how audio can be combined with visual observation to help improve any pose estimation methods.