 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoVAE: Prototypical Networks for Unsupervised Disentanglement
May 16, 2023Generative modeling and self-supervised learning have in recent years made great strides towards learning from data in a completely unsupervised way. There is still however an open area of investigation into guiding a neural network to encode the data into representations that are interpretable or explainable. The problem of unsupervised disentanglement is of particular importance as it proposes to discover the different latent factors of variation or semantic concepts from the data alone, without labeled examples, and encode them into structurally disjoint latent representations. Without additional constraints or inductive biases placed in the network, a generative model may learn the data distribution and encode the factors, but not necessarily in a disentangled way. Here, we introduce a novel deep generative VAE-based model, ProtoVAE, that leverages a deep metric learning Prototypical network trained using self-supervision to impose these constraints. The prototypical network constrains the mapping of the representation space to data space to ensure that controlled changes in the representation space are mapped to changes in the factors of variations in the data space. Our model is completely unsupervised and requires no a priori knowledge of the dataset, including the number of factors. We evaluate our proposed model on the benchmark dSprites, 3DShapes, and MPI3D disentanglement datasets, showing state of the art results against previous methods via qualitative traversals in the latent space, as well as quantitative disentanglement metrics. We further qualitatively demonstrate the effectiveness of our model on the real-world CelebA dataset.
Class-Similarity Based Label Smoothing for Generalized Confidence Calibration
Jun 24, 2020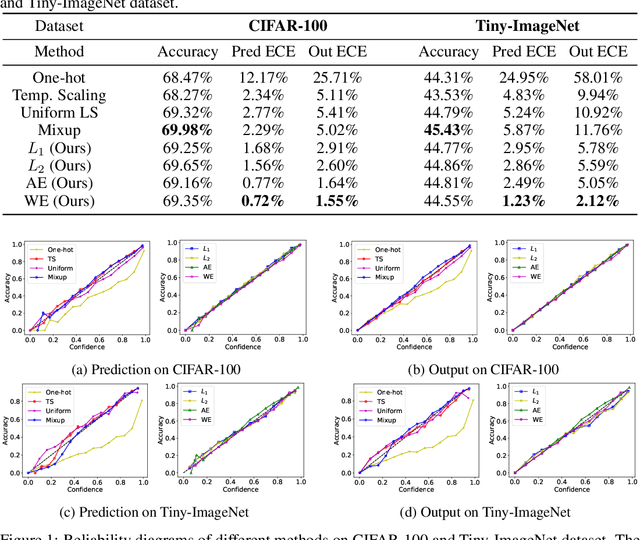
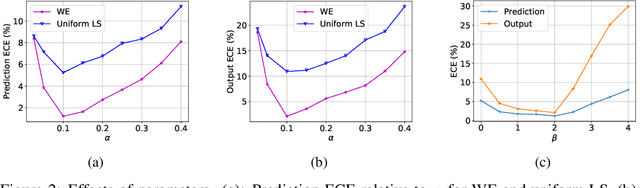
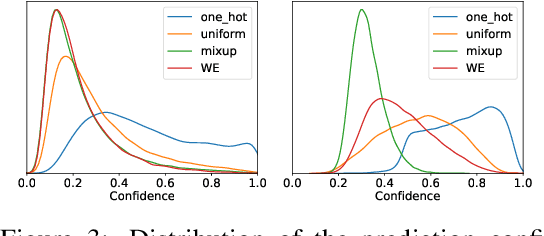
Since modern neural networks are known to be overconfident, several techniques have been recently introduced to address this problem and improve calibration. However, the current notion of calibration is overly simple since only single prediction confidence is considered while the information regarding the rest of the classes is ignored. The output of a neural network is a probability distribution where the scores are estimated confidences of the input belonging to the corresponding classes, and hence they represent a complete estimate of the output likelihood that should be calibrated. In this paper, we first introduce a generalized definition of confidence calibration, which motivates the development of a novel form of label smoothing where the value of each class label is based on its similarity with the reference class. We adopt different similarity measurements, including those that capture semantic similarity, and demonstrate through extensive experiments the advantage of our method over both uniform label smoothing and other techniques.
From Maxout to Channel-Out: Encoding Information on Sparse Pathways
Nov 18, 2013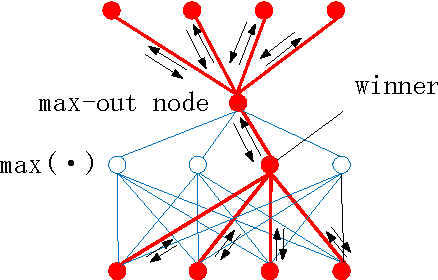
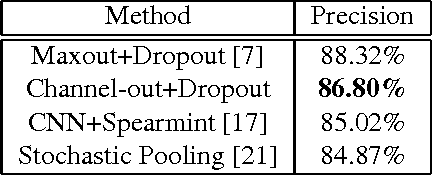
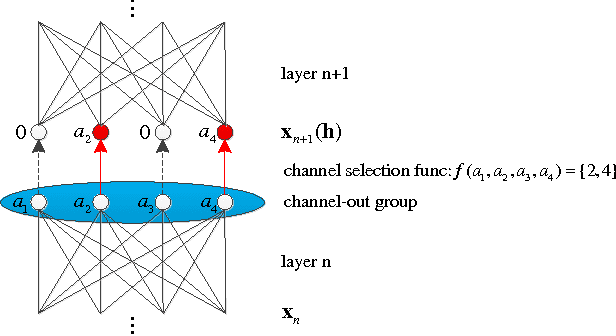

Motivated by an important insight from neural science, we propose a new framework for understanding the success of the recently proposed "maxout" networks. The framework is based on encoding information on sparse pathways and recognizing the correct pathway at inference time. Elaborating further on this insight, we propose a novel deep network architecture, called "channel-out" network, which takes a much better advantage of sparse pathway encoding. In channel-out networks, pathways are not only formed a posteriori, but they are also actively selected according to the inference outputs from the lower layers. From a mathematical perspective, channel-out networks can represent a wider class of piece-wise continuous functions, thereby endowing the network with more expressive power than that of maxout networks. We test our channel-out networks on several well-known image classification benchmarks, setting new state-of-the-art performance on CIFAR-100 and STL-10, which represent some of the "harder" image classification benchmarks.