 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Similarity Based Label Smoothing for Generalized Confidence Calibration
Paper and Code
Jun 24, 2020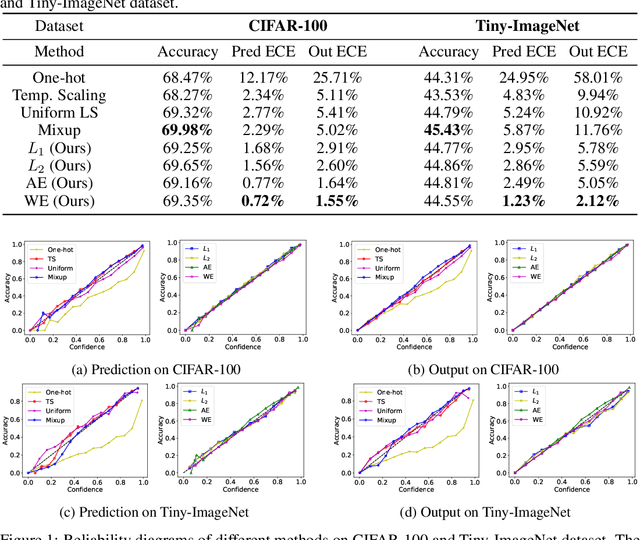
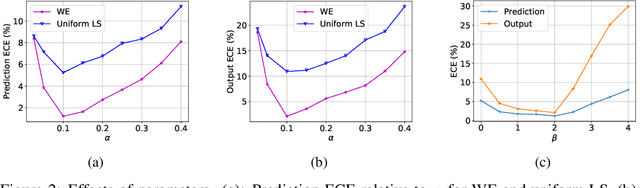
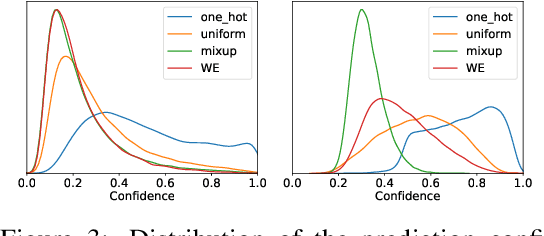
Since modern neural networks are known to be overconfident, several techniques have been recently introduced to address this problem and improve calibration. However, the current notion of calibration is overly simple since only single prediction confidence is considered while the information regarding the rest of the classes is ignored. The output of a neural network is a probability distribution where the scores are estimated confidences of the input belonging to the corresponding classes, and hence they represent a complete estimate of the output likelihood that should be calibrated. In this paper, we first introduce a generalized definition of confidence calibration, which motivates the development of a novel form of label smoothing where the value of each class label is based on its similarity with the reference class. We adopt different similarity measurements, including those that capture semantic similarity, and demonstrate through extensive experiments the advantage of our method over both uniform label smoothing and other techniques.