 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaelstrom Networks
Paper and Code
Aug 29, 2024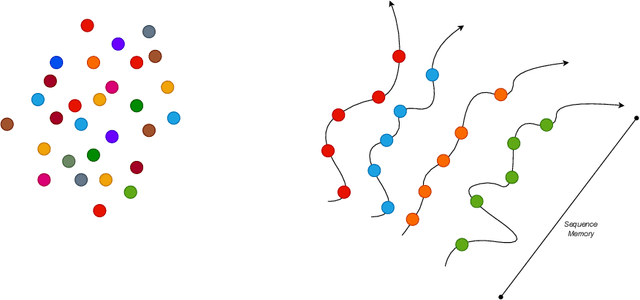
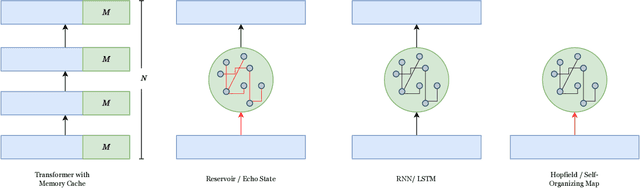
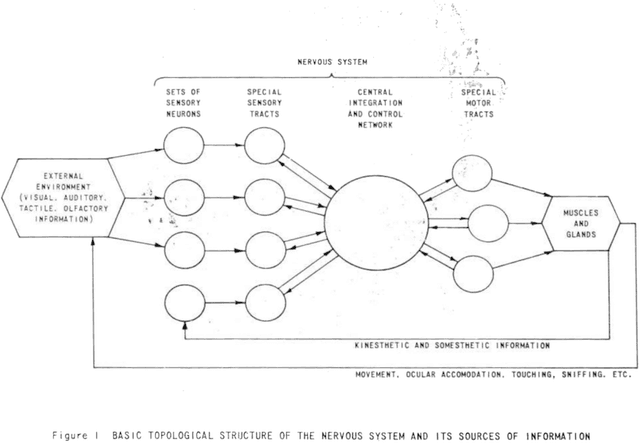
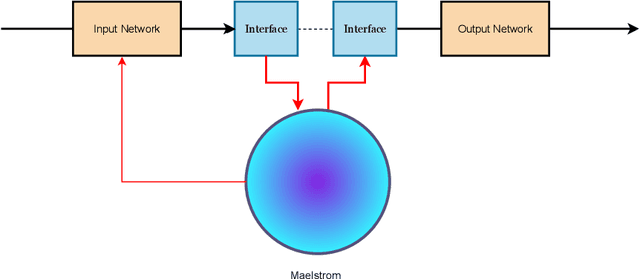
Artificial Neural Networks has struggled to devise a way to incorporate working memory into neural networks. While the ``long term'' memory can be seen as the learned weights, the working memory consists likely more of dynamical activity, that is missing from feed-forward models. Current state of the art models such as transformers tend to ``solve'' this by ignoring working memory entirely and simply process the sequence as an entire piece of data; however this means the network cannot process the sequence in an online fashion, and leads to an immense explosion in memory requirements. Here, inspired by a combination of controls, reservoir computing, deep learning, and recurrent neural networks, we offer an alternative paradigm that combines the strength of recurrent networks, with the pattern matching capability of feed-forward neural networks, which we call the \textit{Maelstrom Networks} paradigm. This paradigm leaves the recurrent component - the \textit{Maelstrom} - unlearned, and offloads the learning to a powerful feed-forward network. This allows the network to leverage the strength of feed-forward training without unrolling the network, and allows for the memory to be implemented in new neuromorphic hardware. It endows a neural network with a sequential memory that takes advantage of the inductive bias that data is organized causally in the temporal domain, and imbues the network with a state that represents the agent's ``self'', moving through the environment. This could also lead the way to continual learning, with the network modularized and ``'protected'' from overwrites that come with new data. In addition to aiding in solving these performance problems that plague current non-temporal deep networks, this also could finally lead towards endowing artificial networks with a sense of ``self''.