 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe impact of Compositionality in Zero-shot Multi-label action recognition for Object-based tasks
May 14, 2024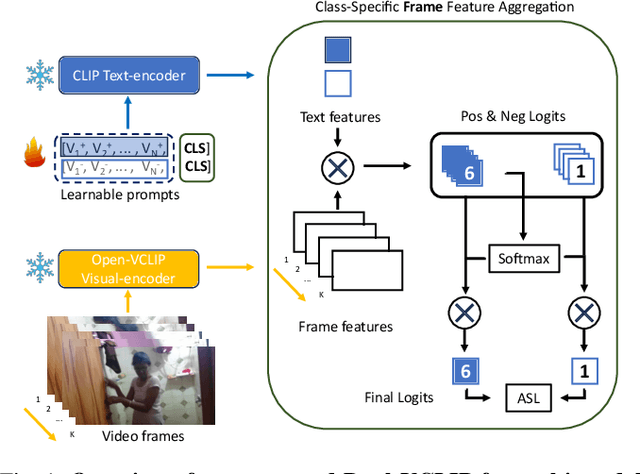

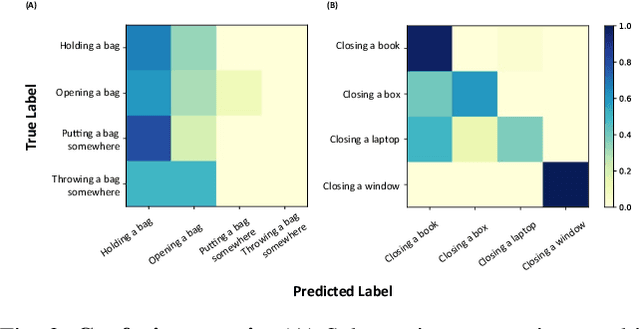
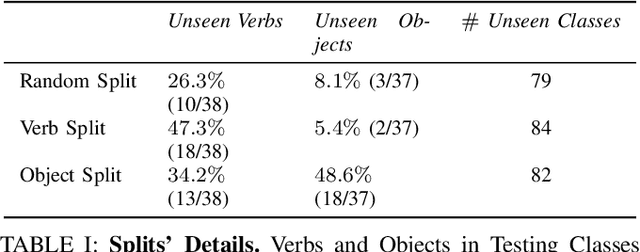
Addressing multi-label action recognition in videos represents a significant challenge for robotic applications in dynamic environments, especially when the robot is required to cooperate with humans in tasks that involve objects. Existing methods still struggle to recognize unseen actions or require extensive training data. To overcome these problems, we propose Dual-VCLIP, a unified approach for zero-shot multi-label action recognition. Dual-VCLIP enhances VCLIP, a zero-shot action recognition method, with the DualCoOp method for multi-label image classification. The strength of our method is that at training time it only learns two prompts, and it is therefore much simpler than other methods. We validate our method on the Charades dataset that includes a majority of object-based actions, demonstrating that -- despite its simplicity -- our method performs favorably with respect to existing methods on the complete dataset, and promising performance when tested on unseen actions. Our contribution emphasizes the impact of verb-object class-splits during robots' training for new cooperative tasks, highlighting the influence on the performance and giving insights into mitigating biases.