 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Baseline Study and Benchmark for Few-Shot Open-Set Action Recognition with Feature Residual Discrimination
Mar 04, 2026Few-Shot Action Recognition (FS-AR) has shown promising results but is often limited by a closed-set assumption that fails in real-world open-set scenarios. While Few-Shot Open-Set (FSOS) recognition is well-established for images, its extension to spatio-temporal video data remains underexplored. To address this, we propose an architectural extension based on a Feature-Residual Discriminator (FR-Disc), adapting previous work on skeletal data to the more complex video domain. Extensive experiments on five datasets demonstrate that while common open-set techniques provide only marginal gains, our FR-Disc significantly enhances unknown rejection capabilities without compromising closed-set accuracy, setting a new state-of-the-art for FSOS-AR. The project website, code, and benchmark are available at: https://hsp-iit.github.io/fsosar/.
PCHands: PCA-based Hand Pose Synergy Representation on Manipulators with N-DoF
Aug 11, 2025We consider the problem of learning a common representation for dexterous manipulation across manipulators of different morphologies. To this end, we propose PCHands, a novel approach for extracting hand postural synergies from a large set of manipulators. We define a simplified and unified description format based on anchor positions for manipulators ranging from 2-finger grippers to 5-finger anthropomorphic hands. This enables learning a variable-length latent representation of the manipulator configuration and the alignment of the end-effector frame of all manipulators. We show that it is possible to extract principal components from this latent representation that is universal across manipulators of different structures and degrees of freedom. To evaluate PCHands, we use this compact representation to encode observation and action spaces of control policies for dexterous manipulation tasks learned with RL. In terms of learning efficiency and consistency, the proposed representation outperforms a baseline that learns the same tasks in joint space. We additionally show that PCHands performs robustly in RL from demonstration, when demonstrations are provided from a different manipulator. We further support our results with real-world experiments that involve a 2-finger gripper and a 4-finger anthropomorphic hand. Code and additional material are available at https://hsp-iit.github.io/PCHands/.
Continuous Wrist Control on the Hannes Prosthesis: a Vision-based Shared Autonomy Framework
Feb 24, 2025



Most control techniques for prosthetic grasping focus on dexterous fingers control, but overlook the wrist motion. This forces the user to perform compensatory movements with the elbow, shoulder and hip to adapt the wrist for grasping. We propose a computer vision-based system that leverages the collaboration between the user and an automatic system in a shared autonomy framework, to perform continuous control of the wrist degrees of freedom in a prosthetic arm, promoting a more natural approach-to-grasp motion. Our pipeline allows to seamlessly control the prosthetic wrist to follow the target object and finally orient it for grasping according to the user intent. We assess the effectiveness of each system component through quantitative analysis and finally deploy our method on the Hannes prosthetic arm. Code and videos: https://hsp-iit.github.io/hannes-wrist-control.
The impact of Compositionality in Zero-shot Multi-label action recognition for Object-based tasks
May 14, 2024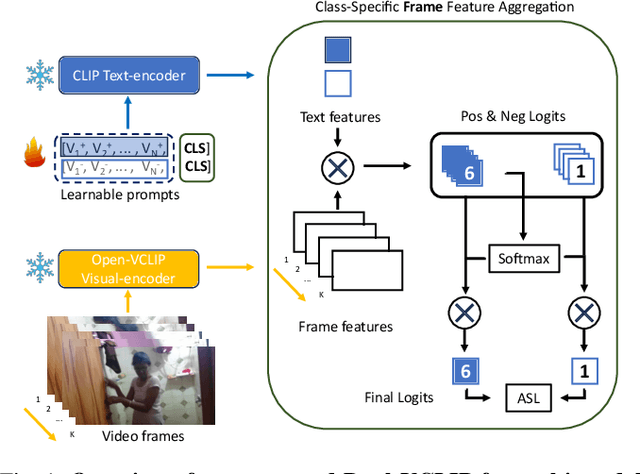

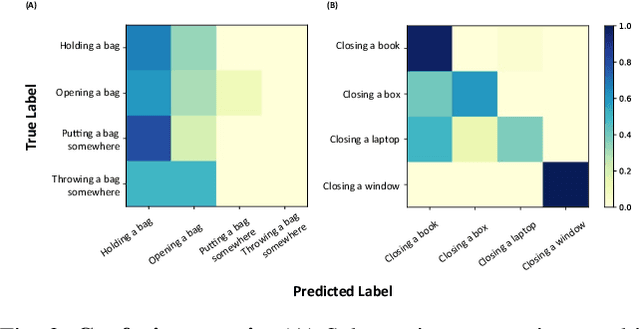
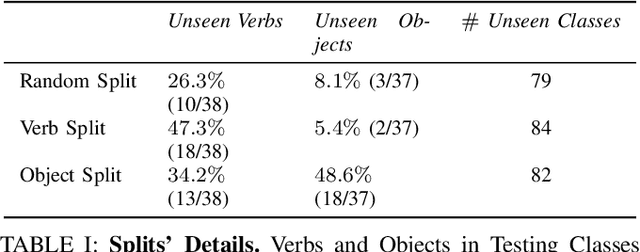
Addressing multi-label action recognition in videos represents a significant challenge for robotic applications in dynamic environments, especially when the robot is required to cooperate with humans in tasks that involve objects. Existing methods still struggle to recognize unseen actions or require extensive training data. To overcome these problems, we propose Dual-VCLIP, a unified approach for zero-shot multi-label action recognition. Dual-VCLIP enhances VCLIP, a zero-shot action recognition method, with the DualCoOp method for multi-label image classification. The strength of our method is that at training time it only learns two prompts, and it is therefore much simpler than other methods. We validate our method on the Charades dataset that includes a majority of object-based actions, demonstrating that -- despite its simplicity -- our method performs favorably with respect to existing methods on the complete dataset, and promising performance when tested on unseen actions. Our contribution emphasizes the impact of verb-object class-splits during robots' training for new cooperative tasks, highlighting the influence on the performance and giving insights into mitigating biases.
Learn Fast, Segment Well: Fast Object Segmentation Learning on the iCub Robot
Jun 27, 2022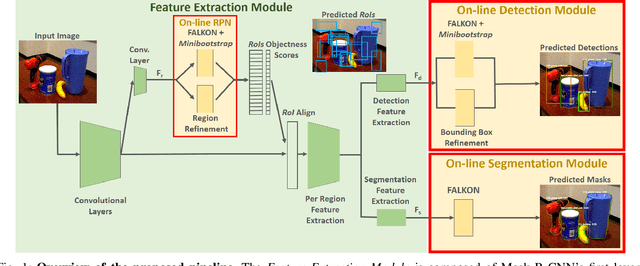

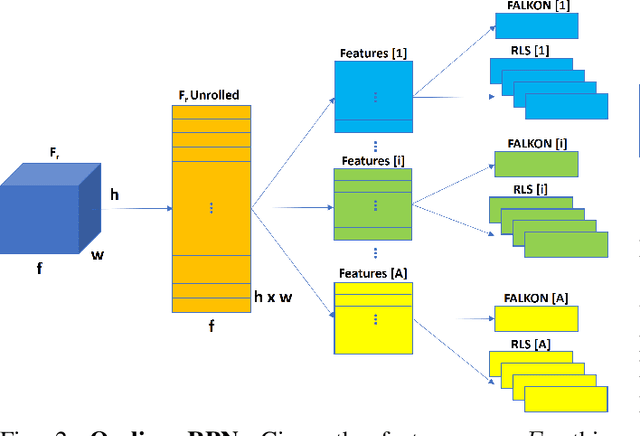
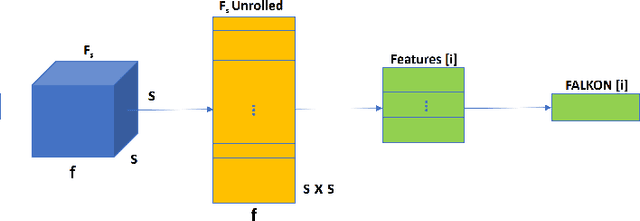
The visual system of a robot has different requirements depending on the application: it may require high accuracy or reliability, be constrained by limited resources or need fast adaptation to dynamically changing environments. In this work, we focus on the instance segmentation task and provide a comprehensive study of different techniques that allow adapting an object segmentation model in presence of novel objects or different domains. We propose a pipeline for fast instance segmentation learning designed for robotic applications where data come in stream. It is based on an hybrid method leveraging on a pre-trained CNN for feature extraction and fast-to-train Kernel-based classifiers. We also propose a training protocol that allows to shorten the training time by performing feature extraction during the data acquisition. We benchmark the proposed pipeline on two robotics datasets and we deploy it on a real robot, i.e. the iCub humanoid. To this aim, we adapt our method to an incremental setting in which novel objects are learned on-line by the robot. The code to reproduce the experiments is publicly available on GitHub.
Grasp Pre-shape Selection by Synthetic Training: Eye-in-hand Shared Control on the Hannes Prosthesis
Mar 18, 2022
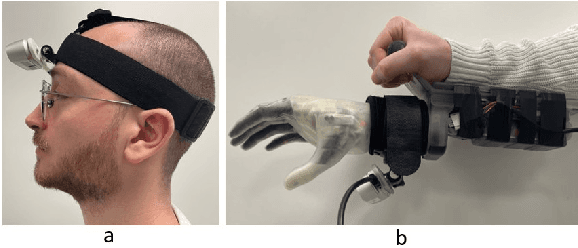

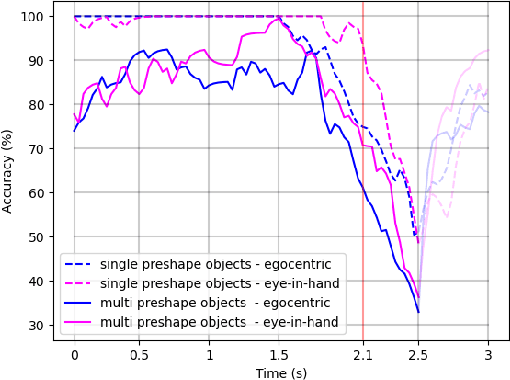
We consider the task of object grasping with a prosthetic hand capable of multiple grasp types. In this setting, communicating the intended grasp type often requires a high user cognitive load which can be reduced adopting shared autonomy frameworks. Among these, so-called eye-in-hand systems automatically control the hand aperture and pre-shaping before the grasp, based on visual input coming from a camera on the wrist. In this work, we present an eye-in-hand learning-based approach for hand pre-shape classification from RGB sequences. In order to reduce the need for tedious data collection sessions for training the system, we devise a pipeline for rendering synthetic visual sequences of hand trajectories for the purpose. We tackle the peculiarity of the eye-in-hand setting by means of a model for the human arm trajectories, with domain randomization over relevant visual elements. We develop a sensorized setup to acquire real human grasping sequences for benchmarking and show that, compared on practical use cases, models trained with our synthetic dataset achieve better generalization performance than models trained on real data. We finally integrate our model on the Hannes prosthetic hand and show its practical effectiveness. Our code, real and synthetic datasets will be released upon acceptance.
ROFT: Real-Time Optical Flow-Aided 6D Object Pose and Velocity Tracking
Nov 06, 2021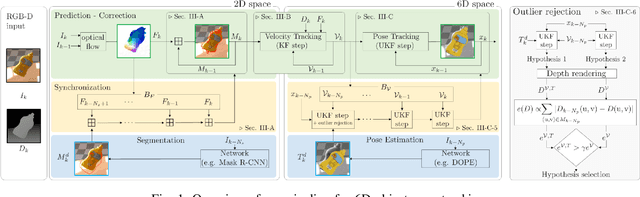

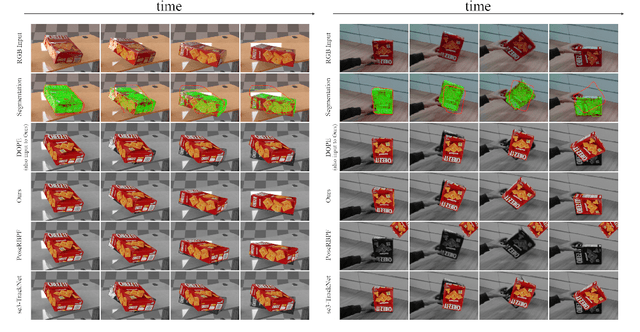

6D object pose tracking has been extensively studied in the robotics and computer vision communities. The most promising solutions, leveraging on deep neural networks and/or filtering and optimization, exhibit notable performance on standard benchmarks. However, to our best knowledge, these have not been tested thoroughly against fast object motions. Tracking performance in this scenario degrades significantly, especially for methods that do not achieve real-time performance and introduce non negligible delays. In this work, we introduce ROFT, a Kalman filtering approach for 6D object pose and velocity tracking from a stream of RGB-D images. By leveraging real-time optical flow, ROFT synchronizes delayed outputs of low frame rate Convolutional Neural Networks for instance segmentation and 6D object pose estimation with the RGB-D input stream to achieve fast and precise 6D object pose and velocity tracking. We test our method on a newly introduced photorealistic dataset, Fast-YCB, which comprises fast moving objects from the YCB model set, and on the dataset for object and hand pose estimation HO-3D. Results demonstrate that our approach outperforms state-of-the-art methods for 6D object pose tracking, while also providing 6D object velocity tracking. A video showing the experiments is provided as supplementary material.
* To cite this work, please refer to the journal reference entry. For more information, code, pictures and video please visit https://github.com/hsp-iit/roft
Data-efficient Weakly-supervised Learning for On-line Object Detection under Domain Shift in Robotics
Dec 28, 2020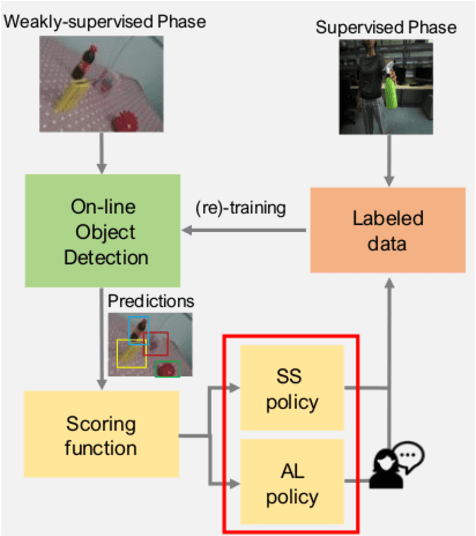
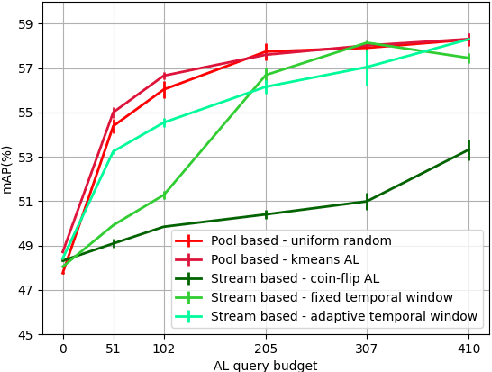

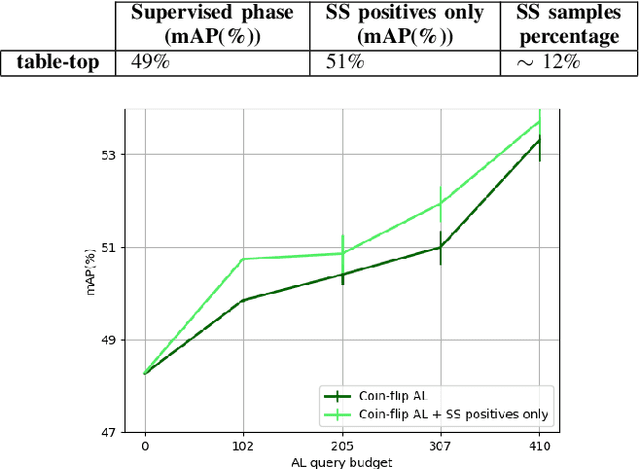
Several object detection methods have recently been proposed in the literature, the vast majority based on Deep Convolutional Neural Networks (DCNNs). Such architectures have been shown to achieve remarkable performance, at the cost of computationally expensive batch training and extensive labeling. These methods have important limitations for robotics: Learning solely on off-line data may introduce biases (the so-called domain shift), and prevents adaptation to novel tasks. In this work, we investigate how weakly-supervised learning can cope with these problems. We compare several techniques for weakly-supervised learning in detection pipelines to reduce model (re)training costs without compromising accuracy. In particular, we show that diversity sampling for constructing active learning queries and strong positives selection for self-supervised learning enable significant annotation savings and improve domain shift adaptation. By integrating our strategies into a hybrid DCNN/FALKON on-line detection pipeline [1], our method is able to be trained and updated efficiently with few labels, overcoming limitations of previous work. We experimentally validate and benchmark our method on challenging robotic object detection tasks under domain shift.
Fast Object Segmentation Learning with Kernel-based Methods for Robotics
Nov 25, 2020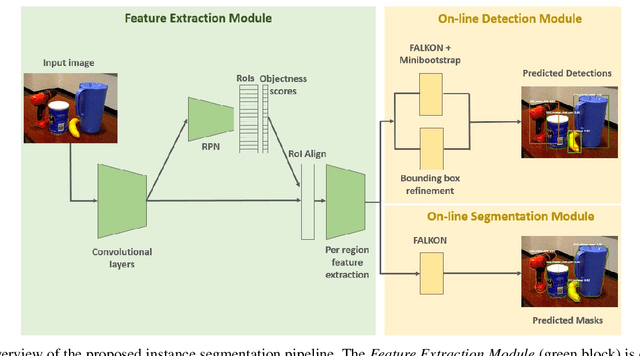

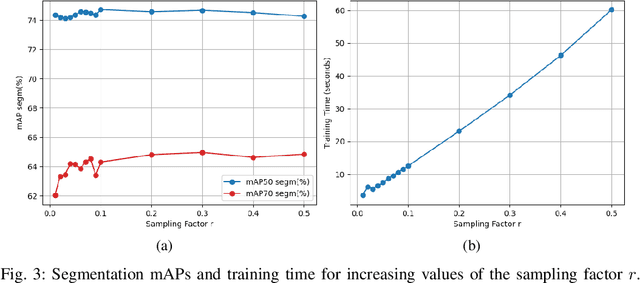

Object segmentation is a key component in the visual system of a robot that performs tasks like grasping and object manipulation, especially in presence of occlusions. Like many other Computer Vision tasks, the adoption of deep architectures has made available algorithms that perform this task with remarkable performance. However, adoption of such algorithms in robotics is hampered by the fact that training requires large amount of computing time and it cannot be performed on-line. In this work, we propose a novel architecture for object segmentation, that overcomes this problem and provides comparable performance in a fraction of the time required by the state-of-the-art methods. Our approach is based on a pre-trained Mask R-CNN, in which various layers have been replaced with a set of classifiers and regressors that are retrained for a new task. We employ an efficient Kernel-based method that allows for fast training on large scale problems. Our approach is validated on the YCB-Video dataset which is widely adopted in the Computer Vision and Robotics community, demonstrating that we can achieve and even surpass performance of the state-of-the-art, with a significant reduction (${\sim}6\times$) of the training time. The code will be released upon acceptance.
Fast Region Proposal Learning for Object Detection for Robotics
Nov 25, 2020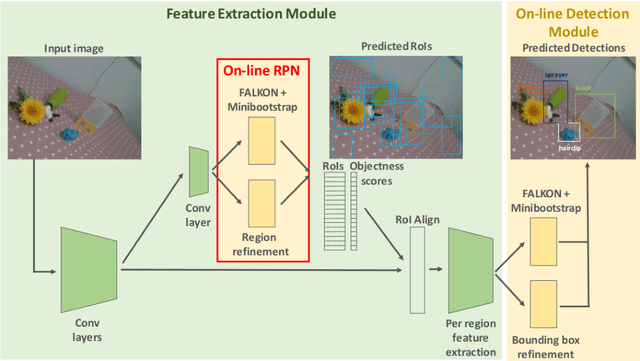
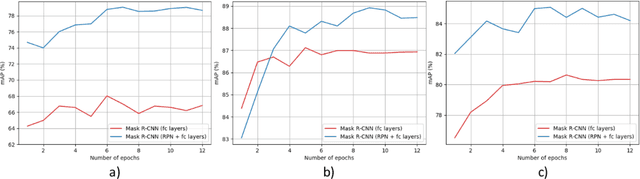
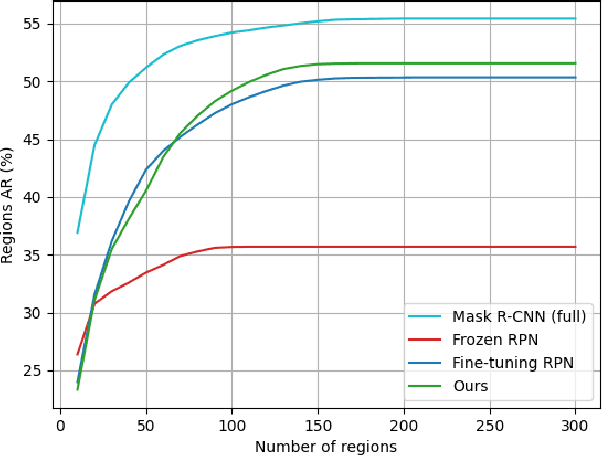
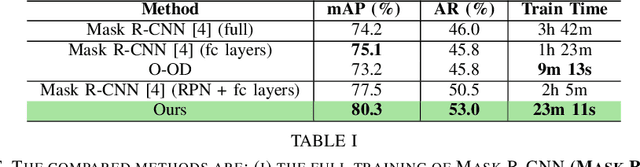
Object detection is a fundamental task for robots to operate in unstructured environments. Today, there are several deep learning algorithms that solve this task with remarkable performance. Unfortunately, training such systems requires several hours of GPU time. For robots, to successfully adapt to changes in the environment or learning new objects, it is also important that object detectors can be re-trained in a short amount of time. A recent method [1] proposes an architecture that leverages on the powerful representation of deep learning descriptors, while permitting fast adaptation time. Leveraging on the natural decomposition of the task in (i) regions candidate generation, (ii) feature extraction and (iii) regions classification, this method performs fast adaptation of the detector, by only re-training the classification layer. This shortens training time while maintaining state-of-the-art performance. In this paper, we firstly demonstrate that a further boost in accuracy can be obtained by adapting, in addition, the regions candidate generation on the task at hand. Secondly, we extend the object detection system presented in [1] with the proposed fast learning approach, showing experimental evidence on the improvement provided in terms of speed and accuracy on two different robotics datasets. The code to reproduce the experiments is publicly available on GitHub.