 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Object Segmentation Learning with Kernel-based Methods for Robotics
Paper and Code
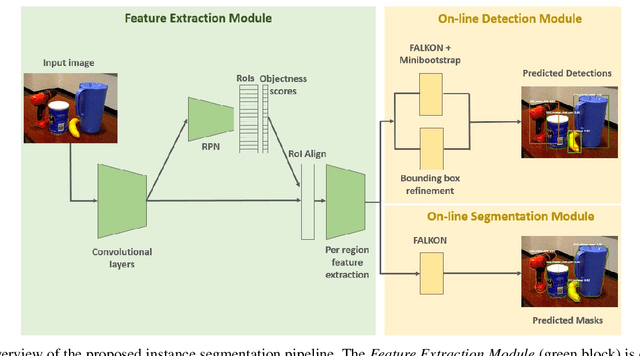

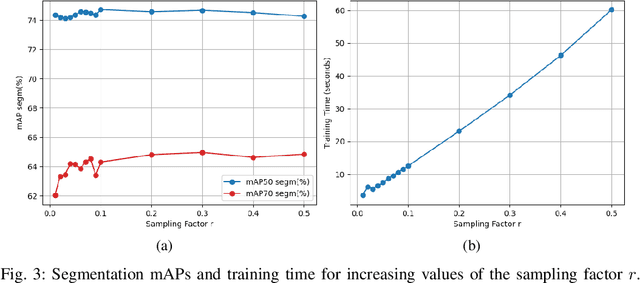

Object segmentation is a key component in the visual system of a robot that performs tasks like grasping and object manipulation, especially in presence of occlusions. Like many other Computer Vision tasks, the adoption of deep architectures has made available algorithms that perform this task with remarkable performance. However, adoption of such algorithms in robotics is hampered by the fact that training requires large amount of computing time and it cannot be performed on-line. In this work, we propose a novel architecture for object segmentation, that overcomes this problem and provides comparable performance in a fraction of the time required by the state-of-the-art methods. Our approach is based on a pre-trained Mask R-CNN, in which various layers have been replaced with a set of classifiers and regressors that are retrained for a new task. We employ an efficient Kernel-based method that allows for fast training on large scale problems. Our approach is validated on the YCB-Video dataset which is widely adopted in the Computer Vision and Robotics community, demonstrating that we can achieve and even surpass performance of the state-of-the-art, with a significant reduction (${\sim}6\times$) of the training time. The code will be released upon acceptance.