 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCHands: PCA-based Hand Pose Synergy Representation on Manipulators with N-DoF
Aug 11, 2025We consider the problem of learning a common representation for dexterous manipulation across manipulators of different morphologies. To this end, we propose PCHands, a novel approach for extracting hand postural synergies from a large set of manipulators. We define a simplified and unified description format based on anchor positions for manipulators ranging from 2-finger grippers to 5-finger anthropomorphic hands. This enables learning a variable-length latent representation of the manipulator configuration and the alignment of the end-effector frame of all manipulators. We show that it is possible to extract principal components from this latent representation that is universal across manipulators of different structures and degrees of freedom. To evaluate PCHands, we use this compact representation to encode observation and action spaces of control policies for dexterous manipulation tasks learned with RL. In terms of learning efficiency and consistency, the proposed representation outperforms a baseline that learns the same tasks in joint space. We additionally show that PCHands performs robustly in RL from demonstration, when demonstrations are provided from a different manipulator. We further support our results with real-world experiments that involve a 2-finger gripper and a 4-finger anthropomorphic hand. Code and additional material are available at https://hsp-iit.github.io/PCHands/.
RESPRECT: Speeding-up Multi-fingered Grasping with Residual Reinforcement Learning
Jan 26, 2024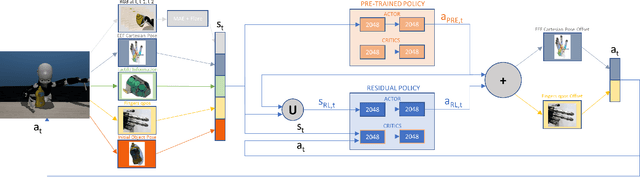

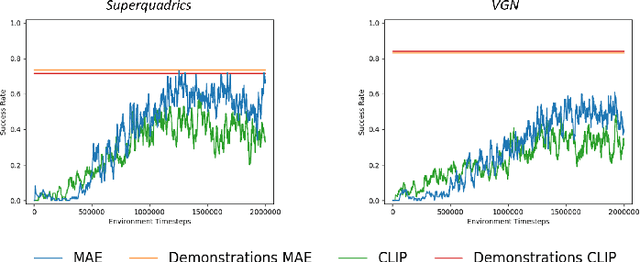

Deep Reinforcement Learning (DRL) has proven effective in learning control policies using robotic grippers, but much less practical for solving the problem of grasping with dexterous hands -- especially on real robotic platforms -- due to the high dimensionality of the problem. In this work, we focus on the multi-fingered grasping task with the anthropomorphic hand of the iCub humanoid. We propose the RESidual learning with PREtrained CriTics (RESPRECT) method that, starting from a policy pre-trained on a large set of objects, can learn a residual policy to grasp a novel object in a fraction ($\sim 5 \times$ faster) of the timesteps required to train a policy from scratch, without requiring any task demonstration. To our knowledge, this is the first Residual Reinforcement Learning (RRL) approach that learns a residual policy on top of another policy pre-trained with DRL. We exploit some components of the pre-trained policy during residual learning that further speed-up the training. We benchmark our results in the iCub simulated environment, and we show that RESPRECT can be effectively used to learn a multi-fingered grasping policy on the real iCub robot. The code to reproduce the experiments is released together with the paper with an open source license.
LHManip: A Dataset for Long-Horizon Language-Grounded Manipulation Tasks in Cluttered Tabletop Environments
Dec 20, 2023
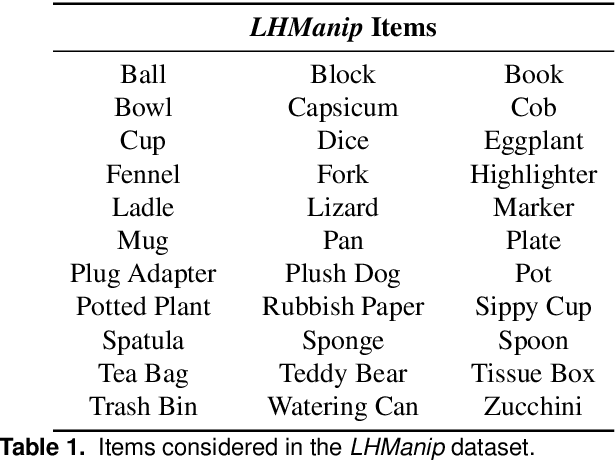

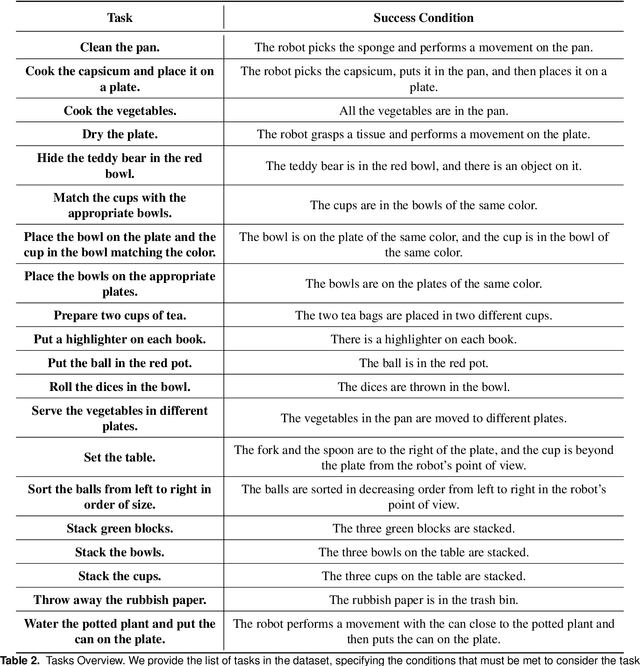
Instructing a robot to complete an everyday task within our homes has been a long-standing challenge for robotics. While recent progress in language-conditioned imitation learning and offline reinforcement learning has demonstrated impressive performance across a wide range of tasks, they are typically limited to short-horizon tasks -- not reflective of those a home robot would be expected to complete. While existing architectures have the potential to learn these desired behaviours, the lack of the necessary long-horizon, multi-step datasets for real robotic systems poses a significant challenge. To this end, we present the Long-Horizon Manipulation (LHManip) dataset comprising 200 episodes, demonstrating 20 different manipulation tasks via real robot teleoperation. The tasks entail multiple sub-tasks, including grasping, pushing, stacking and throwing objects in highly cluttered environments. Each task is paired with a natural language instruction and multi-camera viewpoints for point-cloud or NeRF reconstruction. In total, the dataset comprises 176,278 observation-action pairs which form part of the Open X-Embodiment dataset. The full LHManip dataset is made publicly available at https://github.com/fedeceola/LHManip.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
A Grasp Pose is All You Need: Learning Multi-fingered Grasping with Deep Reinforcement Learning from Vision and Touch
Jun 06, 2023



Multi-fingered robotic hands could enable robots to perform sophisticated manipulation tasks. However, teaching a robot to grasp objects with an anthropomorphic hand is an arduous problem due to the high dimensionality of state and action spaces. Deep Reinforcement Learning (DRL) offers techniques to design control policies for this kind of problems without explicit environment or hand modeling. However, training these policies with state-of-the-art model-free algorithms is greatly challenging for multi-fingered hands. The main problem is that an efficient exploration of the environment is not possible for such high-dimensional problems, thus causing issues in the initial phases of policy optimization. One possibility to address this is to rely on off-line task demonstrations. However, oftentimes this is incredibly demanding in terms of time and computational resources. In this work, we overcome these requirements and propose the A Grasp Pose is All You Need (G-PAYN) method for the anthropomorphic hand of the iCub humanoid. We develop an approach to automatically collect task demonstrations to initialize the training of the policy. The proposed grasping pipeline starts from a grasp pose generated by an external algorithm, used to initiate the movement. Then a control policy (previously trained with the proposed G-PAYN) is used to reach and grab the object. We deployed the iCub into the MuJoCo simulator and use it to test our approach with objects from the YCB-Video dataset. The results show that G-PAYN outperforms current DRL techniques in the considered setting, in terms of success rate and execution time with respect to the baselines. The code to reproduce the experiments will be released upon acceptance.
Learn Fast, Segment Well: Fast Object Segmentation Learning on the iCub Robot
Jun 27, 2022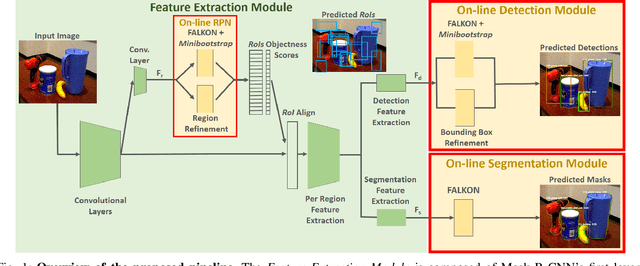

The visual system of a robot has different requirements depending on the application: it may require high accuracy or reliability, be constrained by limited resources or need fast adaptation to dynamically changing environments. In this work, we focus on the instance segmentation task and provide a comprehensive study of different techniques that allow adapting an object segmentation model in presence of novel objects or different domains. We propose a pipeline for fast instance segmentation learning designed for robotic applications where data come in stream. It is based on an hybrid method leveraging on a pre-trained CNN for feature extraction and fast-to-train Kernel-based classifiers. We also propose a training protocol that allows to shorten the training time by performing feature extraction during the data acquisition. We benchmark the proposed pipeline on two robotics datasets and we deploy it on a real robot, i.e. the iCub humanoid. To this aim, we adapt our method to an incremental setting in which novel objects are learned on-line by the robot. The code to reproduce the experiments is publicly available on GitHub.
Fast Object Segmentation Learning with Kernel-based Methods for Robotics
Nov 25, 2020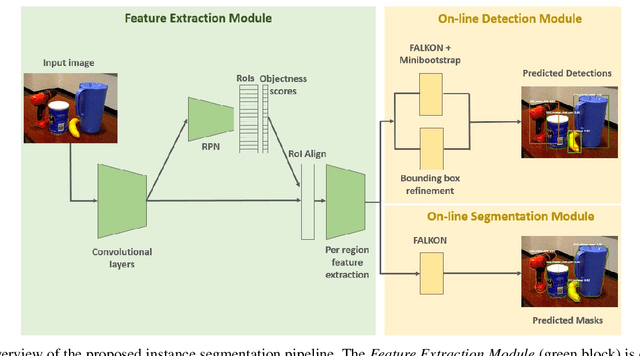

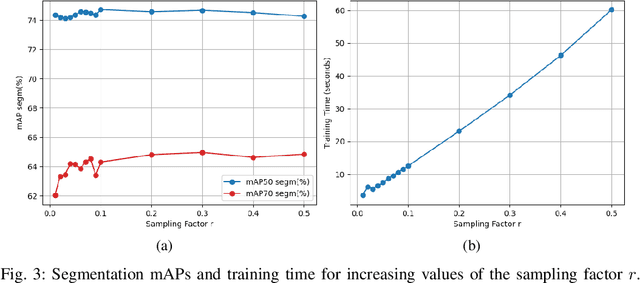

Object segmentation is a key component in the visual system of a robot that performs tasks like grasping and object manipulation, especially in presence of occlusions. Like many other Computer Vision tasks, the adoption of deep architectures has made available algorithms that perform this task with remarkable performance. However, adoption of such algorithms in robotics is hampered by the fact that training requires large amount of computing time and it cannot be performed on-line. In this work, we propose a novel architecture for object segmentation, that overcomes this problem and provides comparable performance in a fraction of the time required by the state-of-the-art methods. Our approach is based on a pre-trained Mask R-CNN, in which various layers have been replaced with a set of classifiers and regressors that are retrained for a new task. We employ an efficient Kernel-based method that allows for fast training on large scale problems. Our approach is validated on the YCB-Video dataset which is widely adopted in the Computer Vision and Robotics community, demonstrating that we can achieve and even surpass performance of the state-of-the-art, with a significant reduction (${\sim}6\times$) of the training time. The code will be released upon acceptance.
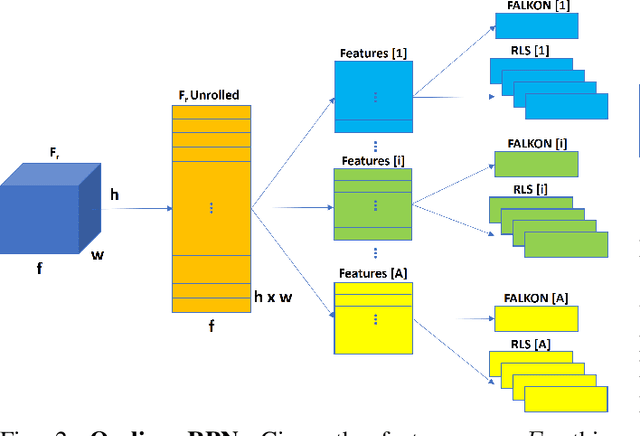
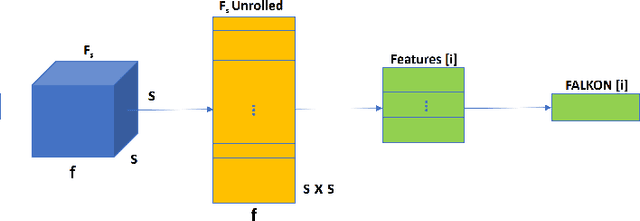
Fast Region Proposal Learning for Object Detection for Robotics
Nov 25, 2020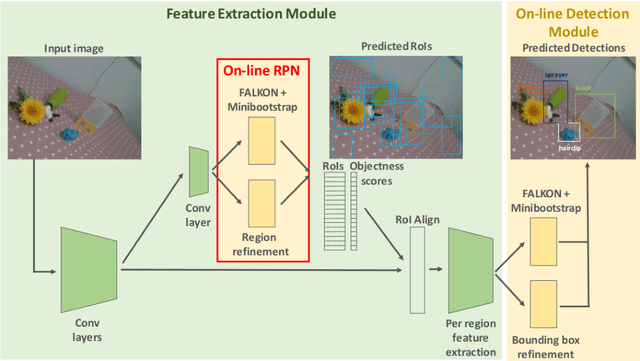
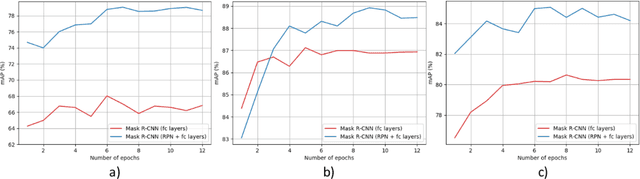
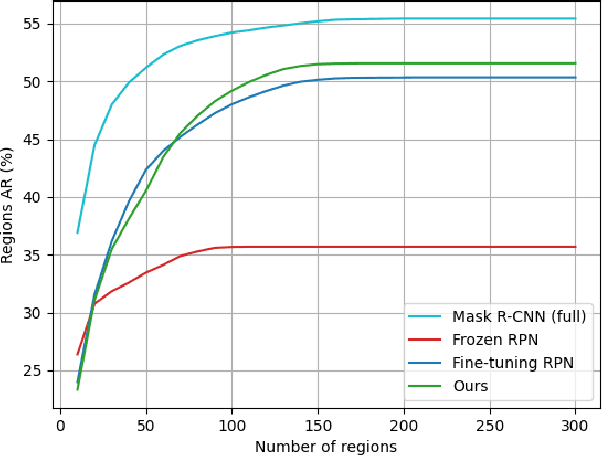
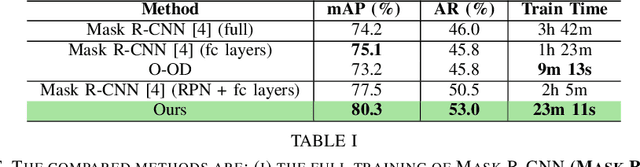
Object detection is a fundamental task for robots to operate in unstructured environments. Today, there are several deep learning algorithms that solve this task with remarkable performance. Unfortunately, training such systems requires several hours of GPU time. For robots, to successfully adapt to changes in the environment or learning new objects, it is also important that object detectors can be re-trained in a short amount of time. A recent method [1] proposes an architecture that leverages on the powerful representation of deep learning descriptors, while permitting fast adaptation time. Leveraging on the natural decomposition of the task in (i) regions candidate generation, (ii) feature extraction and (iii) regions classification, this method performs fast adaptation of the detector, by only re-training the classification layer. This shortens training time while maintaining state-of-the-art performance. In this paper, we firstly demonstrate that a further boost in accuracy can be obtained by adapting, in addition, the regions candidate generation on the task at hand. Secondly, we extend the object detection system presented in [1] with the proposed fast learning approach, showing experimental evidence on the improvement provided in terms of speed and accuracy on two different robotics datasets. The code to reproduce the experiments is publicly available on GitHub.