 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpret Policies in Deep Reinforcement Learning using SILVER with RL-Guided Labeling: A Model-level Approach to High-dimensional and Multi-action Environments
Oct 22, 2025Deep reinforcement learning (RL) achieves remarkable performance but lacks interpretability, limiting trust in policy behavior. The existing SILVER framework (Li, Siddique, and Cao 2025) explains RL policy via Shapley-based regression but remains restricted to low-dimensional, binary-action domains. We propose SILVER with RL-guided labeling, an enhanced variant that extends SILVER to multi-action and high-dimensional environments by incorporating the RL policy's own action outputs into the boundary points identification. Our method first extracts compact feature representations from image observations, performs SHAP-based feature attribution, and then employs RL-guided labeling to generate behaviorally consistent boundary datasets. Surrogate models, such as decision trees and regression-based functions, are subsequently trained to interpret RL policy's decision structure. We evaluate the proposed framework on two Atari environments using three deep RL algorithms and conduct human-subject study to assess the clarity and trustworthiness of the derived interpretable policy. Results show that our approach maintains competitive task performance while substantially improving transparency and human understanding of agent behavior. This work advances explainable RL by transforming SILVER into a scalable and behavior-aware framework for interpreting deep RL agents in high-dimensional, multi-action settings.
Evolutionary Multi-Objective Optimisation for Fairness-Aware Self Adjusting Memory Classifiers in Data Streams
Apr 18, 2024This paper introduces a novel approach, evolutionary multi-objective optimisation for fairness-aware self-adjusting memory classifiers, designed to enhance fairness in machine learning algorithms applied to data stream classification. With the growing concern over discrimination in algorithmic decision-making, particularly in dynamic data stream environments, there is a need for methods that ensure fair treatment of individuals across sensitive attributes like race or gender. The proposed approach addresses this challenge by integrating the strengths of the self-adjusting memory K-Nearest-Neighbour algorithm with evolutionary multi-objective optimisation. This combination allows the new approach to efficiently manage concept drift in streaming data and leverage the flexibility of evolutionary multi-objective optimisation to maximise accuracy and minimise discrimination simultaneously. We demonstrate the effectiveness of the proposed approach through extensive experiments on various datasets, comparing its performance against several baseline methods in terms of accuracy and fairness metrics. Our results show that the proposed approach maintains competitive accuracy and significantly reduces discrimination, highlighting its potential as a robust solution for fairness-aware data stream classification. Further analyses also confirm the effectiveness of the strategies to trigger evolutionary multi-objective optimisation and adapt classifiers in the proposed approach.
Genetic-based Constraint Programming for Resource Constrained Job Scheduling
Feb 01, 2024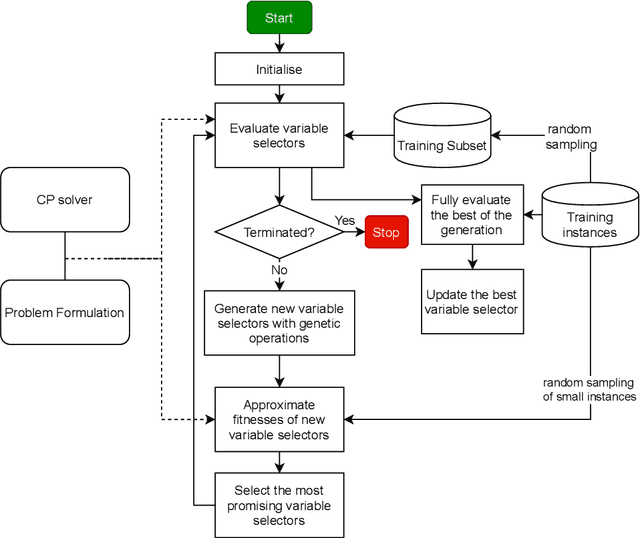


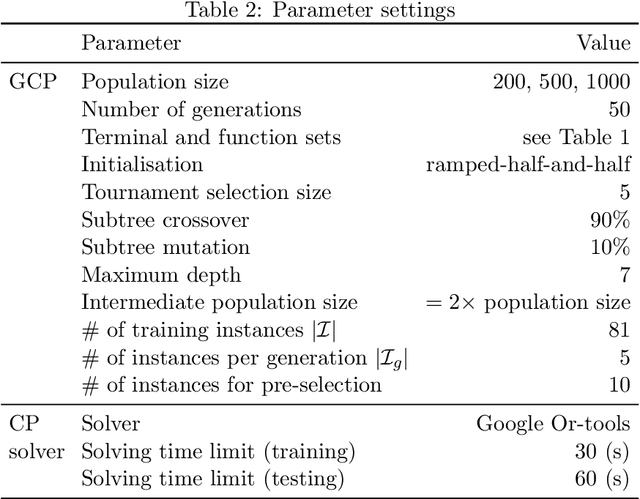
Resource constrained job scheduling is a hard combinatorial optimisation problem that originates in the mining industry. Off-the-shelf solvers cannot solve this problem satisfactorily in reasonable timeframes, while other solution methods such as many evolutionary computation methods and matheuristics cannot guarantee optimality and require low-level customisation and specialised heuristics to be effective. This paper addresses this gap by proposing a genetic programming algorithm to discover efficient search strategies of constraint programming for resource-constrained job scheduling. In the proposed algorithm, evolved programs represent variable selectors to be used in the search process of constraint programming, and their fitness is determined by the quality of solutions obtained for training instances. The novelties of this algorithm are (1) a new representation of variable selectors, (2) a new fitness evaluation scheme, and (3) a pre-selection mechanism. Tests with a large set of random and benchmark instances, the evolved variable selectors can significantly improve the efficiency of constraining programming. Compared to highly customised metaheuristics and hybrid algorithms, evolved variable selectors can help constraint programming identify quality solutions faster and proving optimality is possible if sufficiently large run-times are allowed. The evolved variable selectors are especially helpful when solving instances with large numbers of machines.
AI-Copilot for Business Optimisation: A Framework and A Case Study in Production Scheduling
Sep 29, 2023



Business optimisation is the process of finding and implementing efficient and cost-effective means of operation to bring a competitive advantage for businesses. Synthesizing problem formulations is an integral part of business optimisation which is centred around human expertise, thus with a high potential of becoming a bottleneck. With the recent advancements in Large Language Models (LLMs), human expertise needed in problem formulation can potentially be minimized using Artificial Intelligence (AI). However, developing a LLM for problem formulation is challenging, due to training data requirements, token limitations, and the lack of appropriate performance metrics in LLMs. To minimize the requirement of large training data, considerable attention has recently been directed towards fine-tuning pre-trained LLMs for downstream tasks, rather than training a LLM from scratch for a specific task. In this paper, we adopt this approach and propose an AI-Copilot for business optimisation by fine-tuning a pre-trained LLM for problem formulation. To address token limitations, we introduce modularization and prompt engineering techniques to synthesize complex problem formulations as modules that fit into the token limits of LLMs. In addition, we design performance evaluation metrics that are more suitable for assessing the accuracy and quality of problem formulations compared to existing evaluation metrics. Experiment results demonstrate that our AI-Copilot can synthesize complex and large problem formulations for a typical business optimisation problem in production scheduling.
Enhancing Constraint Programming via Supervised Learning for Job Shop Scheduling
Nov 26, 2022



Constraint programming (CP) is an effective technique for solving constraint satisfaction and optimization problems. CP solvers typically use a variable ordering strategy to select which variable to explore first in the solving process, which has a large impact on the efficacy of the solvers. In this paper, we propose a novel variable ordering strategy based on supervised learning to solve job shop scheduling problems. We develop a classification model and a regression model to predict the optimal solution of a problem instance, and use the predicted solution to order variables for CP solvers. We show that training machine learning models is very efficient and can achieve a high accuracy. Our extensive experiments demonstrate that the learned variable ordering methods perform competitively compared to four existing methods. Finally, we show that hybridising the machine learning-based variable ordering methods with traditional domain-based methods is beneficial.
Adaptive Population-based Simulated Annealing for Uncertain Resource Constrained Job Scheduling
Oct 31, 2022



Transporting ore from mines to ports is of significant interest in mining supply chains. These operations are commonly associated with growing costs and a lack of resources. Large mining companies are interested in optimally allocating their resources to reduce operational costs. This problem has been previously investigated in the literature as resource constrained job scheduling (RCJS). While a number of optimisation methods have been proposed to tackle the deterministic problem, the uncertainty associated with resource availability, an inevitable challenge in mining operations, has received less attention. RCJS with uncertainty is a hard combinatorial optimisation problem that cannot be solved efficiently with existing optimisation methods. This study proposes an adaptive population-based simulated annealing algorithm that can overcome the limitations of existing methods for RCJS with uncertainty including the premature convergence, the excessive number of hyper-parameters, and the inefficiency in coping with different uncertainty levels. This new algorithm is designed to effectively balance exploration and exploitation, by using a population, modifying the cooling schedule in the Metropolis-Hastings algorithm, and using an adaptive mechanism to select perturbation operators. The results show that the proposed algorithm outperforms existing methods across a wide range of benchmark RCJS instances and uncertainty levels. Moreover, new best known solutions are discovered for all but one problem instance across all uncertainty levels.
An Efficient Merge Search Matheuristic for Maximising the Net Present Value of Project Schedules
Oct 20, 2022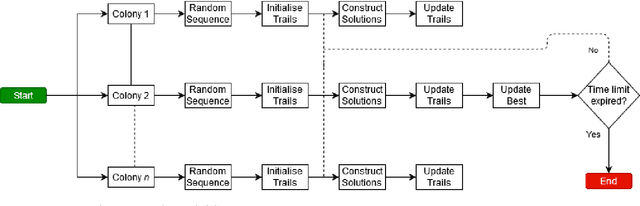

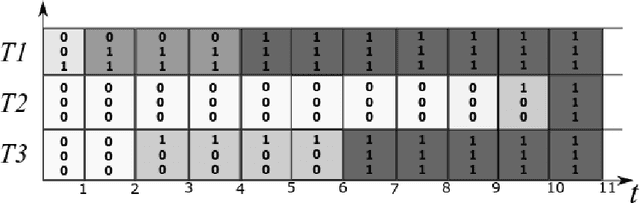

Resource constrained project scheduling is an important combinatorial optimisation problem with many practical applications. With complex requirements such as precedence constraints, limited resources, and finance-based objectives, finding optimal solutions for large problem instances is very challenging even with well-customised meta-heuristics and matheuristics. To address this challenge, we propose a new math-heuristic algorithm based on Merge Search and parallel computing to solve the resource constrained project scheduling with the aim of maximising the net present value. This paper presents a novel matheuristic framework designed for resource constrained project scheduling, Merge search, which is a variable partitioning and merging mechanism to formulate restricted mixed integer programs with the aim of improving an existing pool of solutions. The solution pool is obtained via a customised parallel ant colony optimisation algorithm, which is also capable of generating high quality solutions on its own. The experimental results show that the proposed method outperforms the current state-of-the-art algorithms on known benchmark problem instances. Further analyses also demonstrate that the proposed algorithm is substantially more efficient compared to its counterparts in respect to its convergence properties when considering multiple cores.