 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Multi-Objective Optimisation for Fairness-Aware Self Adjusting Memory Classifiers in Data Streams
Apr 18, 2024This paper introduces a novel approach, evolutionary multi-objective optimisation for fairness-aware self-adjusting memory classifiers, designed to enhance fairness in machine learning algorithms applied to data stream classification. With the growing concern over discrimination in algorithmic decision-making, particularly in dynamic data stream environments, there is a need for methods that ensure fair treatment of individuals across sensitive attributes like race or gender. The proposed approach addresses this challenge by integrating the strengths of the self-adjusting memory K-Nearest-Neighbour algorithm with evolutionary multi-objective optimisation. This combination allows the new approach to efficiently manage concept drift in streaming data and leverage the flexibility of evolutionary multi-objective optimisation to maximise accuracy and minimise discrimination simultaneously. We demonstrate the effectiveness of the proposed approach through extensive experiments on various datasets, comparing its performance against several baseline methods in terms of accuracy and fairness metrics. Our results show that the proposed approach maintains competitive accuracy and significantly reduces discrimination, highlighting its potential as a robust solution for fairness-aware data stream classification. Further analyses also confirm the effectiveness of the strategies to trigger evolutionary multi-objective optimisation and adapt classifiers in the proposed approach.
AI-Copilot for Business Optimisation: A Framework and A Case Study in Production Scheduling
Sep 29, 2023



Business optimisation is the process of finding and implementing efficient and cost-effective means of operation to bring a competitive advantage for businesses. Synthesizing problem formulations is an integral part of business optimisation which is centred around human expertise, thus with a high potential of becoming a bottleneck. With the recent advancements in Large Language Models (LLMs), human expertise needed in problem formulation can potentially be minimized using Artificial Intelligence (AI). However, developing a LLM for problem formulation is challenging, due to training data requirements, token limitations, and the lack of appropriate performance metrics in LLMs. To minimize the requirement of large training data, considerable attention has recently been directed towards fine-tuning pre-trained LLMs for downstream tasks, rather than training a LLM from scratch for a specific task. In this paper, we adopt this approach and propose an AI-Copilot for business optimisation by fine-tuning a pre-trained LLM for problem formulation. To address token limitations, we introduce modularization and prompt engineering techniques to synthesize complex problem formulations as modules that fit into the token limits of LLMs. In addition, we design performance evaluation metrics that are more suitable for assessing the accuracy and quality of problem formulations compared to existing evaluation metrics. Experiment results demonstrate that our AI-Copilot can synthesize complex and large problem formulations for a typical business optimisation problem in production scheduling.
HyperSeed: Unsupervised Learning with Vector Symbolic Architectures
Oct 15, 2021
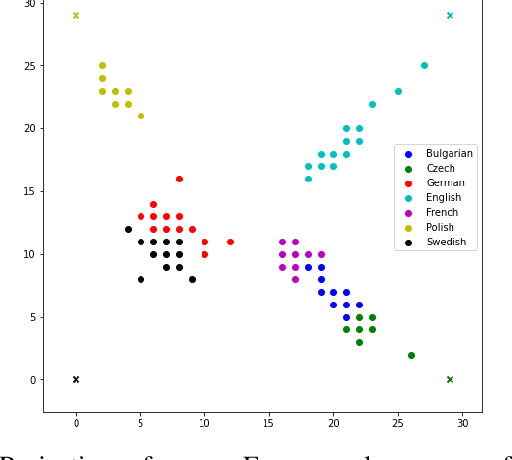
Motivated by recent innovations in biologically-inspired neuromorphic hardware, this paper presents a novel unsupervised machine learning approach named Hyperseed that leverages Vector Symbolic Architectures (VSA) for fast learning a topology preserving feature map of unlabelled data. It relies on two major capabilities of VSAs: the binding operation and computing in superposition. In this paper, we introduce the algorithmic part of Hyperseed expressed within Fourier Holographic Reduced Representations VSA model, which is specifically suited for implementation on spiking neuromorphic hardware. The two distinctive novelties of the Hyperseed algorithm are: 1) Learning from only few input data samples and 2) A learning rule based on a single vector operation. These properties are demonstrated on synthetic datasets as well as on illustrative benchmark use-cases, IRIS classification and a language identification task using n-gram statistics.
Gated Recurrent Neural Network Approach for Multilabel Emotion Detection in Microblogs
Jul 17, 2019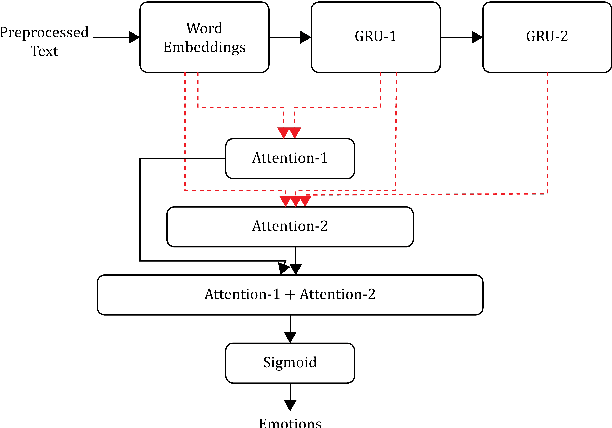
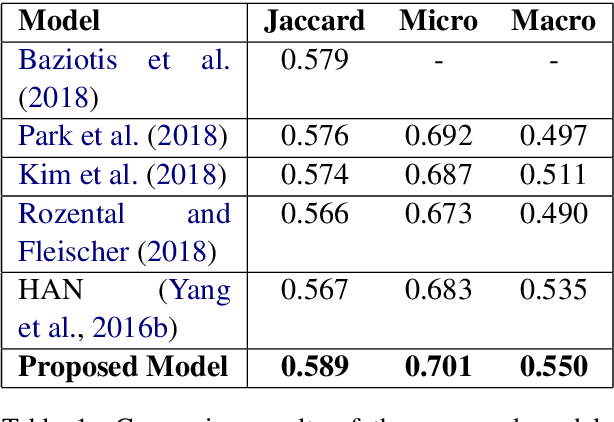
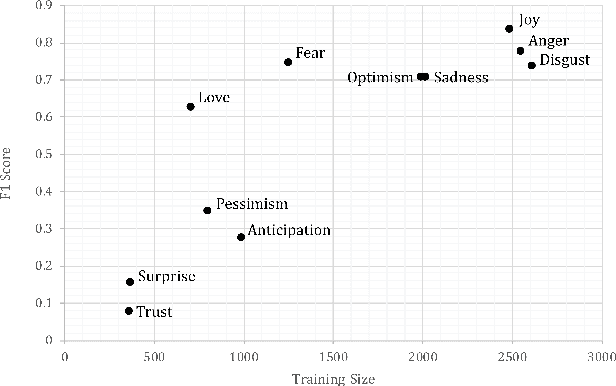
People express their opinions and emotions freely in social media posts and online reviews that contain valuable feedback for multiple stakeholders such as businesses and political campaigns. Manually extracting opinions and emotions from large volumes of such posts is an impossible task. Therefore, automated processing of these posts to extract opinions and emotions is an important research problem. However, human emotion detection is a challenging task due to the complexity and nuanced nature. To overcome these barriers, researchers have extensively used techniques such as deep learning, distant supervision, and transfer learning. In this paper, we propose a novel Pyramid Attention Network (PAN) based model for emotion detection in microblogs. The main advantage of our approach is that PAN has the capability to evaluate sentences in different perspectives to capture multiple emotions existing in a single text. The proposed model was evaluated on a recently released dataset and the results achieved the state-of-the-art accuracy of 58.9%.
Enhancing Decision Making Capacity in Tourism Domain Using Social Media Analytics
Dec 19, 2018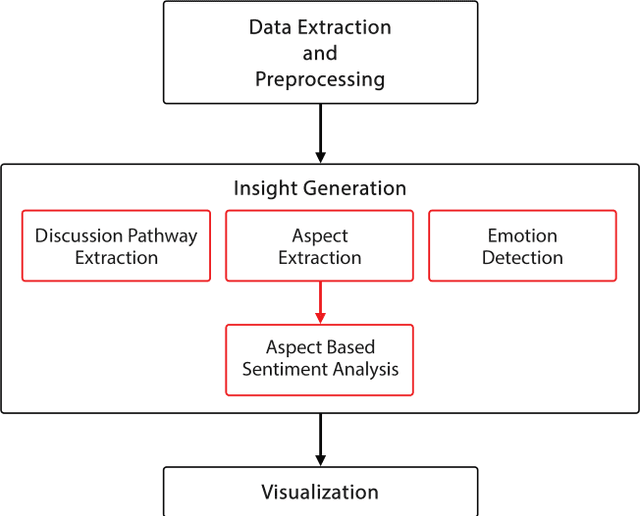
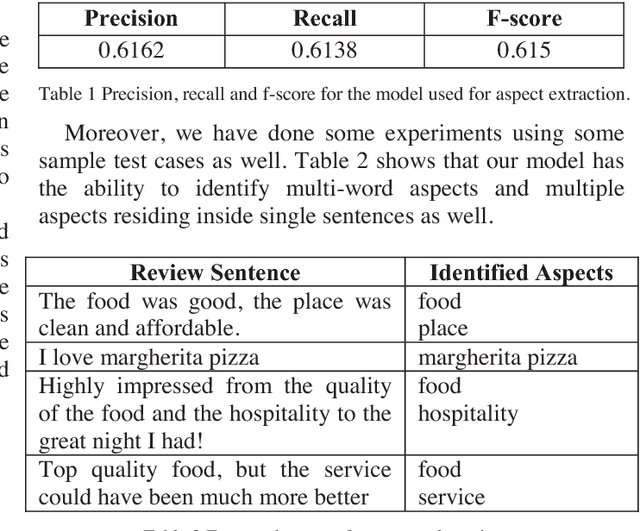
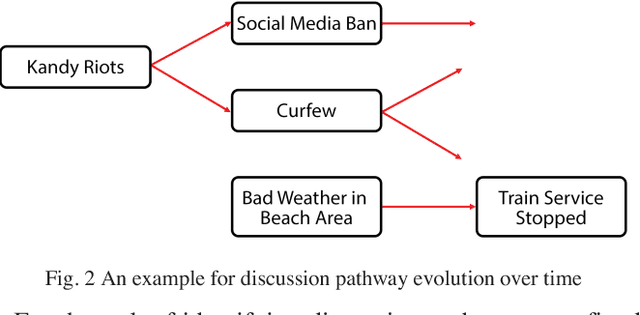

Social media has gained an immense popularity over the last decade. People tend to express opinions about their daily encounters on social media freely. These daily encounters include the places they traveled, hotels or restaurants they have tried and aspects related to tourism in general. Since people usually express their true experiences on social media, the expressed opinions contain valuable information that can be used to generate business value and aid in decision-making processes. Due to the large volume of data, it is not a feasible task to manually go through each and every item and extract the information. Hence, we propose a social media analytics platform which has the capability to identify discussion pathways and aspects with their corresponding sentiment and deeper emotions using machine learning techniques and a visualization tool which shows the extracted insights in a comprehensible and concise manner. Identified topic pathways and aspects will give a decision maker some insight into what are the most discussed topics about the entity whereas associated sentiments and emotions will help to identify the feedback.