 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALFA: A Safe-by-Design Approach to Mitigate Quishing Attacks Launched via Fancy QR Codes
Jan 11, 2026Phishing with Quick Response (QR) codes is termed as Quishing. The attackers exploit this method to manipulate individuals into revealing their confidential data. Recently, we see the colorful and fancy representations of QR codes, the 2D matrix of QR codes which does not reflect a typical mixture of black-white modules anymore. Instead, they become more tempting as an attack vector for adversaries which can evade the state-of-the-art deep learning visual-based and other prevailing countermeasures. We introduce "ALFA", a safe-by-design approach, to mitigate Quishing and prevent everyone from accessing the post-scan harmful payload of fancy QR codes. Our method first converts a fancy QR code into the replica of binary grid and then identify the erroneous representation of modules in that grid. Following that, we present "FAST" method which can conveniently recover erroneous modules from that binary grid. Afterwards, using this binary grid, our solution extracts the structural features of fancy QR code and predicts its legitimacy using a pre-trained model. The effectiveness of our proposal is demonstrated by the experimental evaluation on a synthetic dataset (containing diverse variations of fancy QR codes) and achieve a FNR of 0.06% only. We also develop the mobile app to test the practical feasibility of our solution and provide a performance comparison of the app with the real-world QR readers. This comparison further highlights the classification reliability and detection accuracy of this solution in real-world environments.
Bayesian Network Fusion of Large Language Models for Sentiment Analysis
Oct 30, 2025Large language models (LLMs) continue to advance, with an increasing number of domain-specific variants tailored for specialised tasks. However, these models often lack transparency and explainability, can be costly to fine-tune, require substantial prompt engineering, yield inconsistent results across domains, and impose significant adverse environmental impact due to their high computational demands. To address these challenges, we propose the Bayesian network LLM fusion (BNLF) framework, which integrates predictions from three LLMs, including FinBERT, RoBERTa, and BERTweet, through a probabilistic mechanism for sentiment analysis. BNLF performs late fusion by modelling the sentiment predictions from multiple LLMs as probabilistic nodes within a Bayesian network. Evaluated across three human-annotated financial corpora with distinct linguistic and contextual characteristics, BNLF demonstrates consistent gains of about six percent in accuracy over the baseline LLMs, underscoring its robustness to dataset variability and the effectiveness of probabilistic fusion for interpretable sentiment classification.
Fruit Classification System with Deep Learning and Neural Architecture Search
Jun 04, 2024



The fruit identification process involves analyzing and categorizing different types of fruits based on their visual characteristics. This activity can be achieved using a range of methodologies, encompassing manual examination, conventional computer vision methodologies, and more sophisticated methodologies employing machine learning and deep learning. Our study identified a total of 15 distinct categories of fruit, consisting of class Avocado, Banana, Cherry, Apple Braeburn, Apple golden 1, Apricot, Grape, Kiwi, Mango, Orange, Papaya, Peach, Pineapple, Pomegranate and Strawberry. Neural Architecture Search (NAS) is a technological advancement employed within the realm of deep learning and artificial intelligence, to automate conceptualizing and refining neural network topologies. NAS aims to identify neural network structures that are highly suitable for tasks, such as the detection of fruits. Our suggested model with 99.98% mAP increased the detection performance of the preceding research study that used Fruit datasets. In addition, after the completion of the study, a comparative analysis was carried out to assess the findings in conjunction with those of another research that is connected to the topic. When compared to the findings of earlier studies, the detector that was proposed exhibited higher performance in terms of both its accuracy and its precision.
Genetic-based Constraint Programming for Resource Constrained Job Scheduling
Feb 01, 2024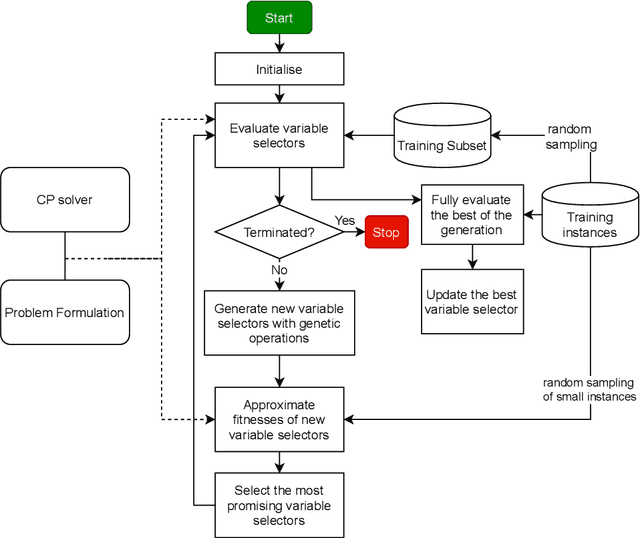


Resource constrained job scheduling is a hard combinatorial optimisation problem that originates in the mining industry. Off-the-shelf solvers cannot solve this problem satisfactorily in reasonable timeframes, while other solution methods such as many evolutionary computation methods and matheuristics cannot guarantee optimality and require low-level customisation and specialised heuristics to be effective. This paper addresses this gap by proposing a genetic programming algorithm to discover efficient search strategies of constraint programming for resource-constrained job scheduling. In the proposed algorithm, evolved programs represent variable selectors to be used in the search process of constraint programming, and their fitness is determined by the quality of solutions obtained for training instances. The novelties of this algorithm are (1) a new representation of variable selectors, (2) a new fitness evaluation scheme, and (3) a pre-selection mechanism. Tests with a large set of random and benchmark instances, the evolved variable selectors can significantly improve the efficiency of constraining programming. Compared to highly customised metaheuristics and hybrid algorithms, evolved variable selectors can help constraint programming identify quality solutions faster and proving optimality is possible if sufficiently large run-times are allowed. The evolved variable selectors are especially helpful when solving instances with large numbers of machines.
A Framework for Empowering Reinforcement Learning Agents with Causal Analysis: Enhancing Automated Cryptocurrency Trading
Oct 14, 2023Despite advances in artificial intelligence-enhanced trading methods, developing a profitable automated trading system remains challenging in the rapidly evolving cryptocurrency market. This study aims to address these challenges by developing a reinforcement learning-based automated trading system for five popular altcoins~(cryptocurrencies other than Bitcoin): Binance Coin, Ethereum, Litecoin, Ripple, and Tether. To this end, we present CausalReinforceNet, a framework framed as a decision support system. Designed as the foundational architecture of the trading system, the CausalReinforceNet framework enhances the capabilities of the reinforcement learning agent through causal analysis. Within this framework, we use Bayesian networks in the feature engineering process to identify the most relevant features with causal relationships that influence cryptocurrency price movements. Additionally, we incorporate probabilistic price direction signals from dynamic Bayesian networks to enhance our reinforcement learning agent's decision-making. Due to the high volatility of the cryptocurrency market, we design our framework to adopt a conservative approach that limits sell and buy position sizes to manage risk. We develop two agents using the CausalReinforceNet framework, each based on distinct reinforcement learning algorithms. The results indicate that our framework substantially surpasses the Buy-and-Hold benchmark strategy in profitability. Additionally, both agents generated notable returns on investment for Binance Coin and Ethereum.
Causal Feature Engineering of Price Directions of Cryptocurrencies using Dynamic Bayesian Networks
Jun 13, 2023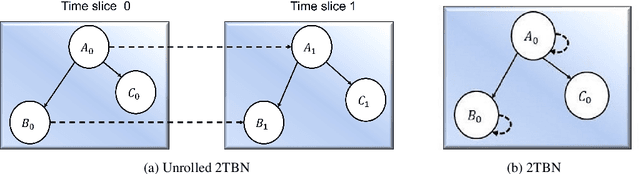

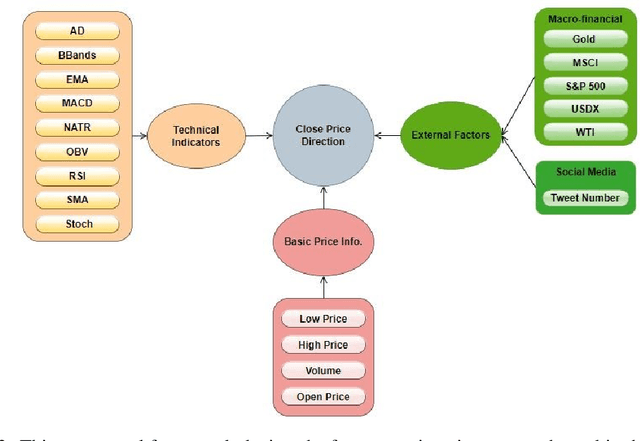
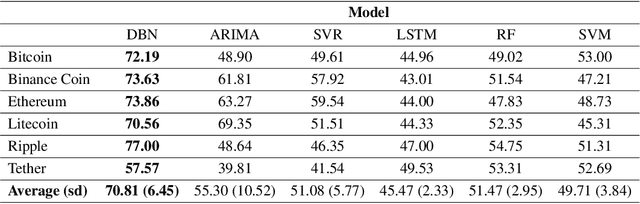
Cryptocurrencies have gained popularity across various sectors, especially in finance and investment. The popularity is partly due to their unique specifications originating from blockchain-related characteristics such as privacy, decentralisation, and untraceability. Despite their growing popularity, cryptocurrencies remain a high-risk investment due to their price volatility and uncertainty. The inherent volatility in cryptocurrency prices, coupled with internal cryptocurrency-related factors and external influential global economic factors makes predicting their prices and price movement directions challenging. Nevertheless, the knowledge obtained from predicting the direction of cryptocurrency prices can provide valuable guidance for investors in making informed investment decisions. To address this issue, this paper proposes a dynamic Bayesian network (DBN) approach, which can model complex systems in multivariate settings, to predict the price movement direction of five popular altcoins (cryptocurrencies other than Bitcoin) in the next trading day. The efficacy of the proposed model in predicting cryptocurrency price directions is evaluated from two perspectives. Firstly, our proposed approach is compared to two baseline models, namely an auto-regressive integrated moving average and support vector regression. Secondly, from a feature engineering point of view, the impact of twenty-three different features, grouped into four categories, on the DBN's prediction performance is investigated. The experimental results demonstrate that the DBN significantly outperforms the baseline models. In addition, among the groups of features, technical indicators are found to be the most effective predictors of cryptocurrency price directions.
Modelling Determinants of Cryptocurrency Prices: A Bayesian Network Approach
Mar 26, 2023The growth of market capitalisation and the number of altcoins (cryptocurrencies other than Bitcoin) provide investment opportunities and complicate the prediction of their price movements. A significant challenge in this volatile and relatively immature market is the problem of predicting cryptocurrency prices which needs to identify the factors influencing these prices. The focus of this study is to investigate the factors influencing altcoin prices, and these factors have been investigated from a causal analysis perspective using Bayesian networks. In particular, studying the nature of interactions between five leading altcoins, traditional financial assets including gold, oil, and S\&P 500, and social media is the research question. To provide an answer to the question, we create causal networks which are built from the historic price data of five traditional financial assets, social media data, and price data of altcoins. The ensuing networks are used for causal reasoning and diagnosis, and the results indicate that social media (in particular Twitter data in this study) is the most significant influencing factor of the prices of altcoins. Furthermore, it is not possible to generalise the coins' reactions against the changes in the factors. Consequently, the coins need to be studied separately for a particular price movement investigation.
Enhancing Constraint Programming via Supervised Learning for Job Shop Scheduling
Nov 26, 2022



Constraint programming (CP) is an effective technique for solving constraint satisfaction and optimization problems. CP solvers typically use a variable ordering strategy to select which variable to explore first in the solving process, which has a large impact on the efficacy of the solvers. In this paper, we propose a novel variable ordering strategy based on supervised learning to solve job shop scheduling problems. We develop a classification model and a regression model to predict the optimal solution of a problem instance, and use the predicted solution to order variables for CP solvers. We show that training machine learning models is very efficient and can achieve a high accuracy. Our extensive experiments demonstrate that the learned variable ordering methods perform competitively compared to four existing methods. Finally, we show that hybridising the machine learning-based variable ordering methods with traditional domain-based methods is beneficial.
Adaptive Population-based Simulated Annealing for Uncertain Resource Constrained Job Scheduling
Oct 31, 2022



Transporting ore from mines to ports is of significant interest in mining supply chains. These operations are commonly associated with growing costs and a lack of resources. Large mining companies are interested in optimally allocating their resources to reduce operational costs. This problem has been previously investigated in the literature as resource constrained job scheduling (RCJS). While a number of optimisation methods have been proposed to tackle the deterministic problem, the uncertainty associated with resource availability, an inevitable challenge in mining operations, has received less attention. RCJS with uncertainty is a hard combinatorial optimisation problem that cannot be solved efficiently with existing optimisation methods. This study proposes an adaptive population-based simulated annealing algorithm that can overcome the limitations of existing methods for RCJS with uncertainty including the premature convergence, the excessive number of hyper-parameters, and the inefficiency in coping with different uncertainty levels. This new algorithm is designed to effectively balance exploration and exploitation, by using a population, modifying the cooling schedule in the Metropolis-Hastings algorithm, and using an adaptive mechanism to select perturbation operators. The results show that the proposed algorithm outperforms existing methods across a wide range of benchmark RCJS instances and uncertainty levels. Moreover, new best known solutions are discovered for all but one problem instance across all uncertainty levels.
A hybrid deep-learning approach for complex biochemical named entity recognition
Dec 20, 2020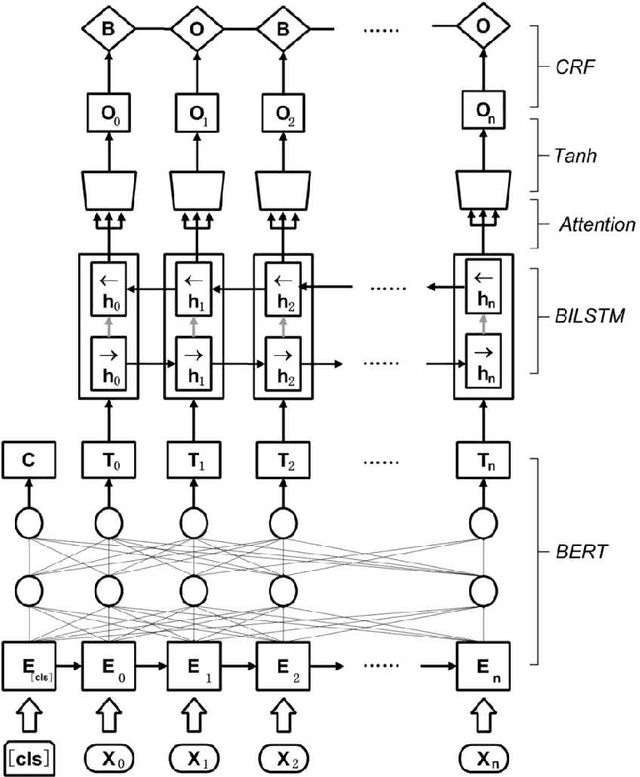
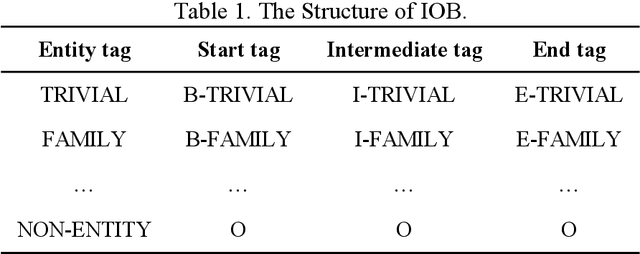
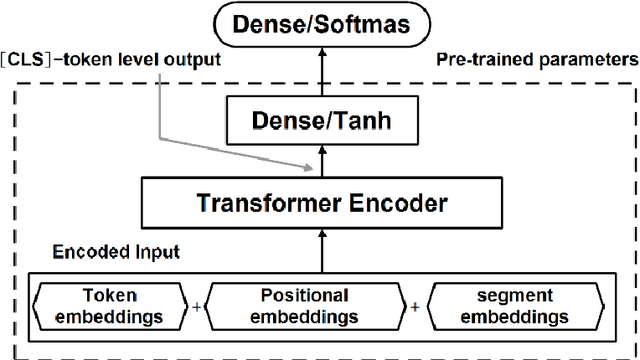
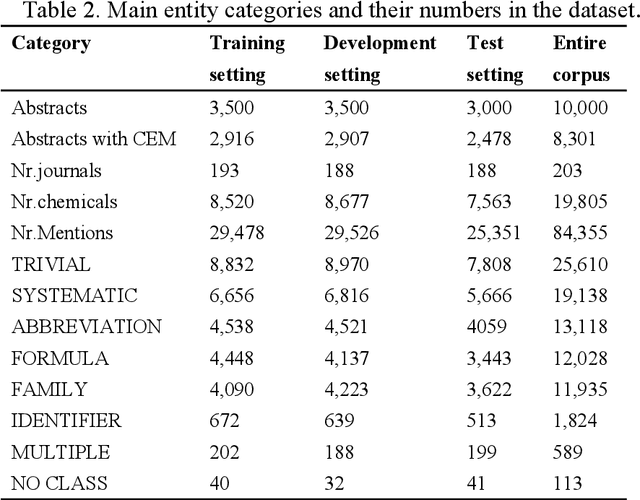
Named entity recognition (NER) of chemicals and drugs is a critical domain of information extraction in biochemical research. NER provides support for text mining in biochemical reactions, including entity relation extraction, attribute extraction, and metabolic response relationship extraction. However, the existence of complex naming characteristics in the biomedical field, such as polysemy and special characters, make the NER task very challenging. Here, we propose a hybrid deep learning approach to improve the recognition accuracy of NER. Specifically, our approach applies the Bidirectional Encoder Representations from Transformers (BERT) model to extract the underlying features of the text, learns a representation of the context of the text through Bi-directional Long Short-Term Memory (BILSTM), and incorporates the multi-head attention (MHATT) mechanism to extract chapter-level features. In this approach, the MHATT mechanism aims to improve the recognition accuracy of abbreviations to efficiently deal with the problem of inconsistency in full-text labels. Moreover, conditional random field (CRF) is used to label sequence tags because this probabilistic method does not need strict independence assumptions and can accommodate arbitrary context information. The experimental evaluation on a publicly-available dataset shows that the proposed hybrid approach achieves the best recognition performance; in particular, it substantially improves performance in recognizing abbreviations, polysemes, and low-frequency entities, compared with the state-of-the-art approaches. For instance, compared with the recognition accuracies for low-frequency entities produced by the BILSTM-CRF algorithm, those produced by the hybrid approach on two entity datasets (MULTIPLE and IDENTIFIER) have been increased by 80% and 21.69%, respectively.