 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance Space Analysis for the Car Sequencing Problem
Paper and Code
Dec 18, 2020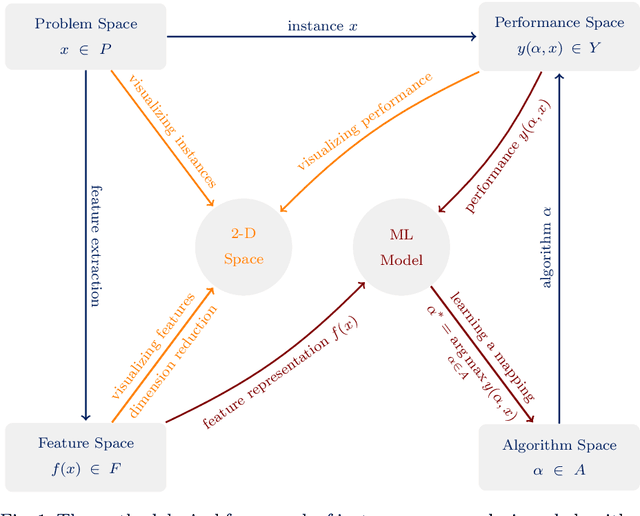
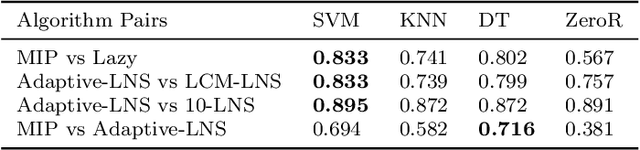

In this paper, we investigate an important research question in the car sequencing problem, that is, what characteristics make an instance hard to solve? To do so, we carry out an Instance Space Analysis for the car sequencing problem, by extracting a vector of problem features to characterize an instance and projecting feature vectors onto a two-dimensional space using principal component analysis. The resulting two dimensional visualizations provide insights into both the characteristics of the instances used for testing and to compare how these affect different optimisation algorithms. This guides us in constructing a new set of benchmark instances with a range of instance properties. These are shown to be both more diverse than the previous benchmarks and include many hard to solve instances. We systematically compare the performance of six algorithms for solving the car sequencing problem. The methods tested include three existing algorithms from the literature and three new ones. Importantly, we build machine learning models to identify the niche in the instance space that an algorithm is expected to perform well on. Our results show that the new algorithms are state-of-the-art. This analysis helps to understand problem hardness and select an appropriate algorithm for solving a given car sequencing problem instance.