 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA hybrid deep-learning approach for complex biochemical named entity recognition
Paper and Code
Dec 20, 2020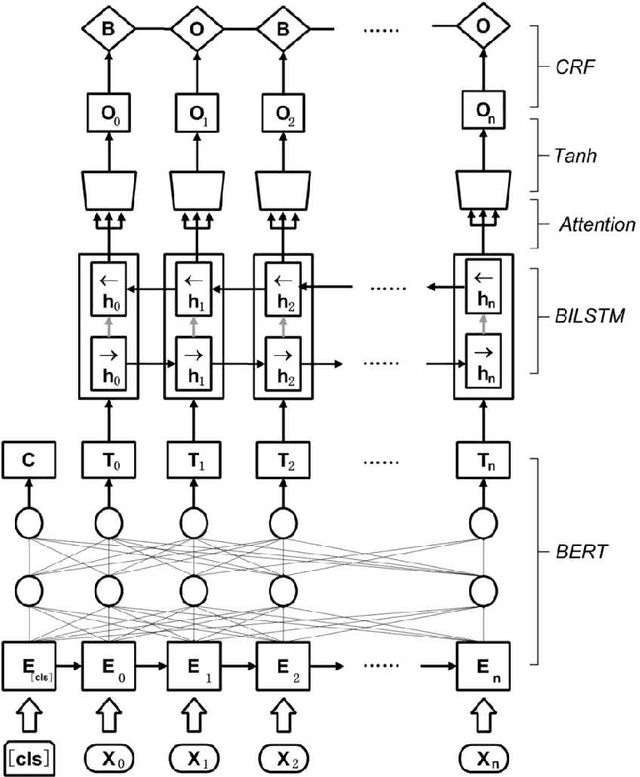
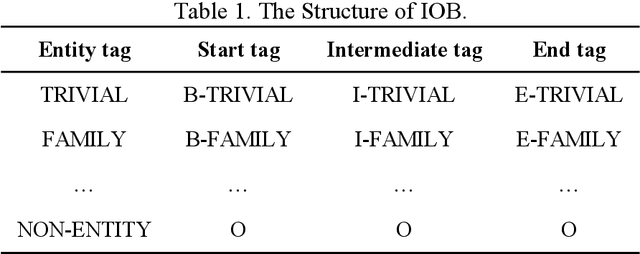
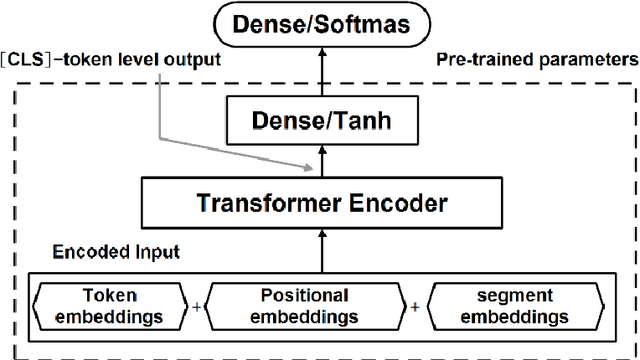
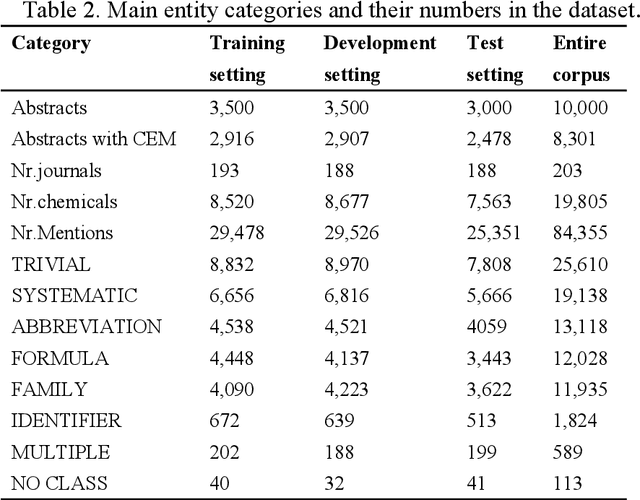
Named entity recognition (NER) of chemicals and drugs is a critical domain of information extraction in biochemical research. NER provides support for text mining in biochemical reactions, including entity relation extraction, attribute extraction, and metabolic response relationship extraction. However, the existence of complex naming characteristics in the biomedical field, such as polysemy and special characters, make the NER task very challenging. Here, we propose a hybrid deep learning approach to improve the recognition accuracy of NER. Specifically, our approach applies the Bidirectional Encoder Representations from Transformers (BERT) model to extract the underlying features of the text, learns a representation of the context of the text through Bi-directional Long Short-Term Memory (BILSTM), and incorporates the multi-head attention (MHATT) mechanism to extract chapter-level features. In this approach, the MHATT mechanism aims to improve the recognition accuracy of abbreviations to efficiently deal with the problem of inconsistency in full-text labels. Moreover, conditional random field (CRF) is used to label sequence tags because this probabilistic method does not need strict independence assumptions and can accommodate arbitrary context information. The experimental evaluation on a publicly-available dataset shows that the proposed hybrid approach achieves the best recognition performance; in particular, it substantially improves performance in recognizing abbreviations, polysemes, and low-frequency entities, compared with the state-of-the-art approaches. For instance, compared with the recognition accuracies for low-frequency entities produced by the BILSTM-CRF algorithm, those produced by the hybrid approach on two entity datasets (MULTIPLE and IDENTIFIER) have been increased by 80% and 21.69%, respectively.