 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Generalizability of a Performance Predictive Model
May 31, 2023



A key component of automated algorithm selection and configuration, which in most cases are performed using supervised machine learning (ML) methods is a good-performing predictive model. The predictive model uses the feature representation of a set of problem instances as input data and predicts the algorithm performance achieved on them. Common machine learning models struggle to make predictions for instances with feature representations not covered by the training data, resulting in poor generalization to unseen problems. In this study, we propose a workflow to estimate the generalizability of a predictive model for algorithm performance, trained on one benchmark suite to another. The workflow has been tested by training predictive models across benchmark suites and the results show that generalizability patterns in the landscape feature space are reflected in the performance space.
SELECTOR: Selecting a Representative Benchmark Suite for Reproducible Statistical Comparison
Apr 25, 2022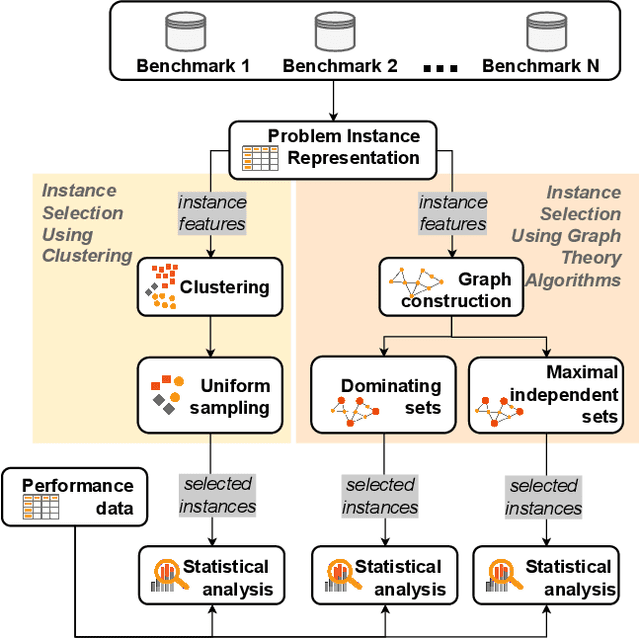

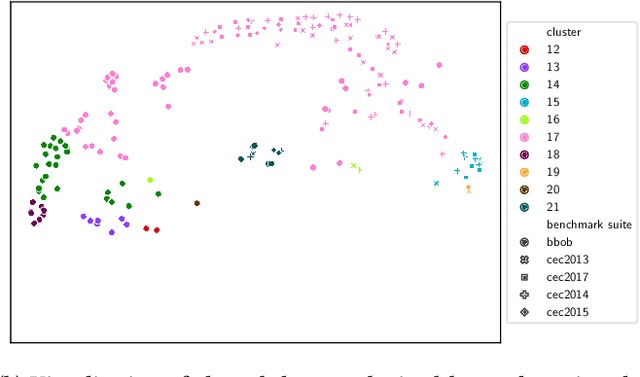
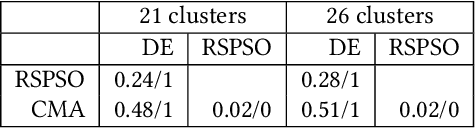
Fair algorithm evaluation is conditioned on the existence of high-quality benchmark datasets that are non-redundant and are representative of typical optimization scenarios. In this paper, we evaluate three heuristics for selecting diverse problem instances which should be involved in the comparison of optimization algorithms in order to ensure robust statistical algorithm performance analysis. The first approach employs clustering to identify similar groups of problem instances and subsequent sampling from each cluster to construct new benchmarks, while the other two approaches use graph algorithms for identifying dominating and maximal independent sets of nodes. We demonstrate the applicability of the proposed heuristics by performing a statistical performance analysis of five portfolios consisting of three optimization algorithms on five of the most commonly used optimization benchmarks. The results indicate that the statistical analyses of the algorithms' performance, conducted on each benchmark separately, produce conflicting outcomes, which can be used to give a false indication of the superiority of one algorithm over another. On the other hand, when the analysis is conducted on the problem instances selected with the proposed heuristics, which uniformly cover the problem landscape, the statistical outcomes are robust and consistent.