 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity-based anomaly detection using spectral graph filtering
Jan 24, 2022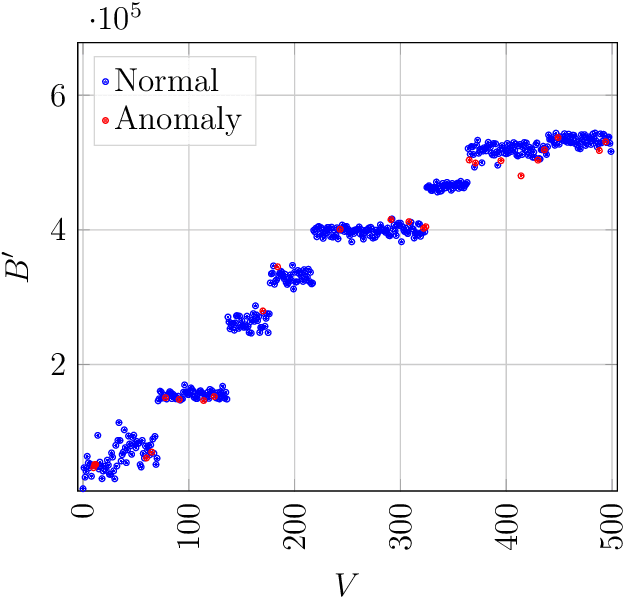

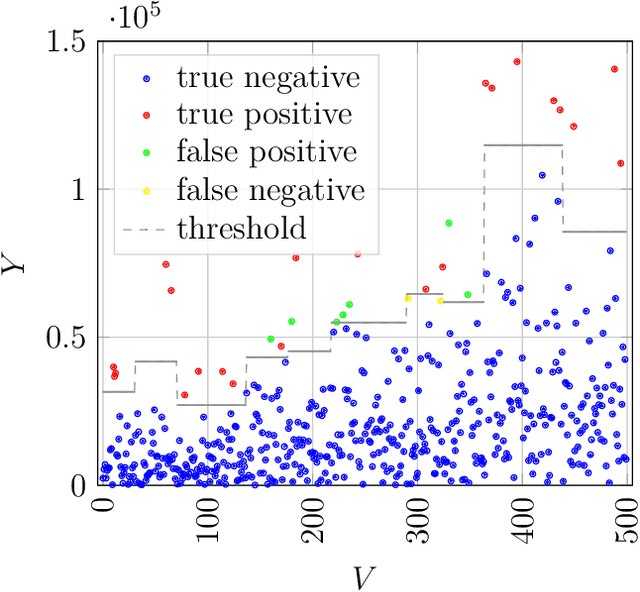
Several applications have a community structure where the nodes of the same community share similar attributes. Anomaly or outlier detection in networks is a relevant and widely studied research topic with applications in various domains. Despite a significant amount of anomaly detection frameworks, there is a dearth on the literature of methods that consider both attributed graphs and the community structure of the networks. This paper proposes a community-based anomaly detection algorithm using a spectral graph-based filter that includes the network community structure into the Laplacian matrix adopted as the basis for the Fourier transform. In addition, the choice of the cutoff frequency of the filter considers the number of communities found. In computational experiments, the proposed strategy, called SpecF, showed an outstanding performance in successfully identifying even discrete anomalies. SpecF is better than a baseline disregarding the community structure, especially for networks with a higher community overlapping. Additionally, we present a case study to validate the proposed method to study the dissemination of COVID-19 in the different districts of S\~ao Jos\'e dos Campos, Brazil.
PyHard: a novel tool for generating hardness embeddings to support data-centric analysis
Sep 29, 2021
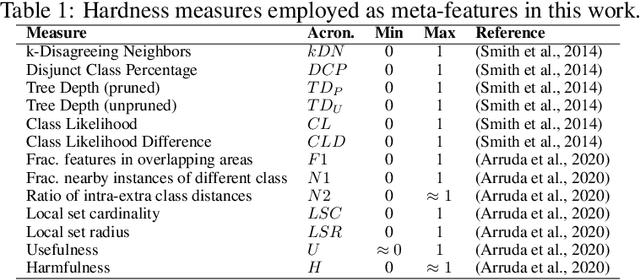

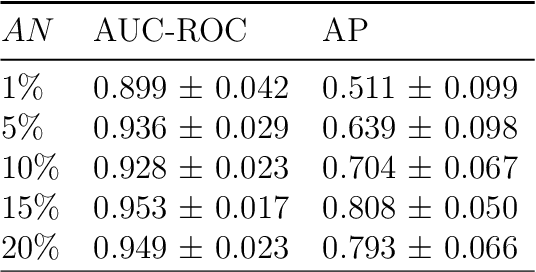
For building successful Machine Learning (ML) systems, it is imperative to have high quality data and well tuned learning models. But how can one assess the quality of a given dataset? And how can the strengths and weaknesses of a model on a dataset be revealed? Our new tool PyHard employs a methodology known as Instance Space Analysis (ISA) to produce a hardness embedding of a dataset relating the predictive performance of multiple ML models to estimated instance hardness meta-features. This space is built so that observations are distributed linearly regarding how hard they are to classify. The user can visually interact with this embedding in multiple ways and obtain useful insights about data and algorithmic performance along the individual observations of the dataset. We show in a COVID prognosis dataset how this analysis supported the identification of pockets of hard observations that challenge ML models and are therefore worth closer inspection, and the delineation of regions of strengths and weaknesses of ML models.