 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRANS: Automatic Feature Extraction for Time Series Forecasting
Sep 15, 2022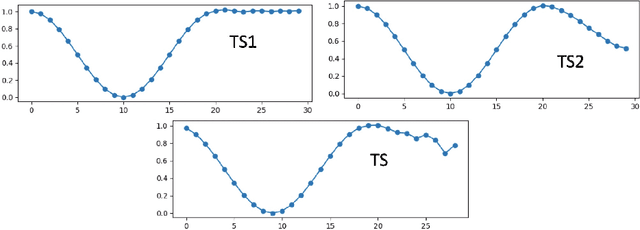
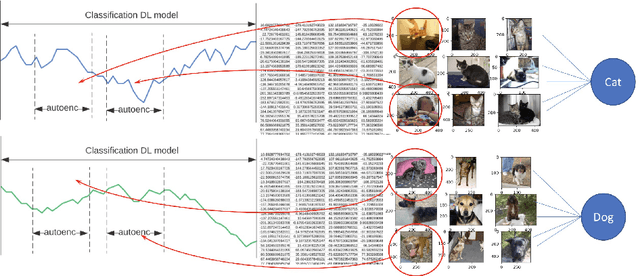
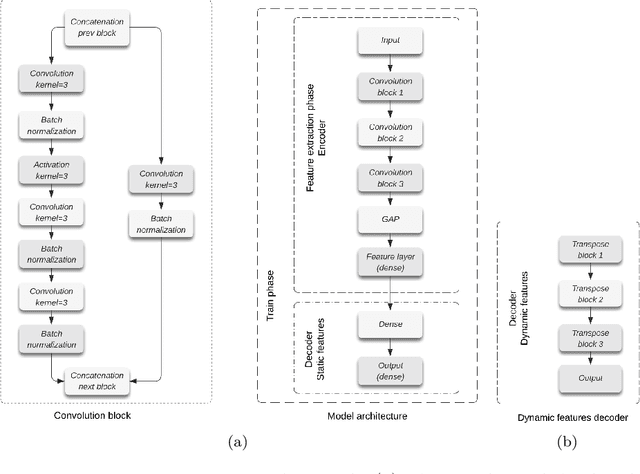
Feature extraction methods help in dimensionality reduction and capture relevant information. In time series forecasting (TSF), features can be used as auxiliary information to achieve better accuracy. Traditionally, features used in TSF are handcrafted, which requires domain knowledge and significant data-engineering work. In this research, we first introduce a notion of static and dynamic features, which then enables us to develop our autonomous Feature Retrieving Autoregressive Network for Static features (FRANS) that does not require domain knowledge. The method is based on a CNN classifier that is trained to create for each series a collective and unique class representation either from parts of the series or, if class labels are available, from a set of series of the same class. It allows to discriminate series with similar behaviour but from different classes and makes the features extracted from the classifier to be maximally discriminatory. We explore the interpretability of our features, and evaluate the prediction capabilities of the method within the forecasting meta-learning environment FFORMA. Our results show that our features lead to improvement in accuracy in most situations. Once trained our approach creates features orders of magnitude faster than statistical methods.
Object Recognition for Economic Development from Daytime Satellite Imagery
Sep 11, 2020
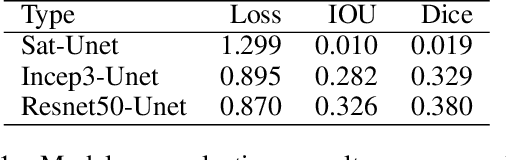
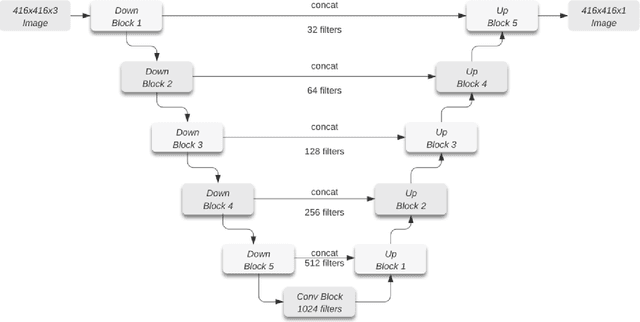
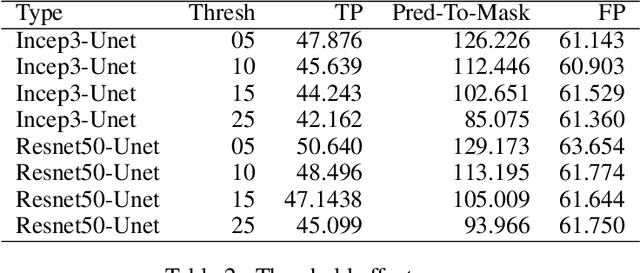
Reliable data about the stock of physical capital and infrastructure in developing countries is typically very scarce. This is particular a problem for data at the subnational level where existing data is often outdated, not consistently measured or coverage is incomplete. Traditional data collection methods are time and labor-intensive costly, which often prohibits developing countries from collecting this type of data. This paper proposes a novel method to extract infrastructure features from high-resolution satellite images. We collected high-resolution satellite images for 5 million 1km $\times$ 1km grid cells covering 21 African countries. We contribute to the growing body of literature in this area by training our machine learning algorithm on ground-truth data. We show that our approach strongly improves the predictive accuracy. Our methodology can build the foundation to then predict subnational indicators of economic development for areas where this data is either missing or unreliable.