 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Representation Learning for Additive Rule Ensembles
Jun 26, 2025



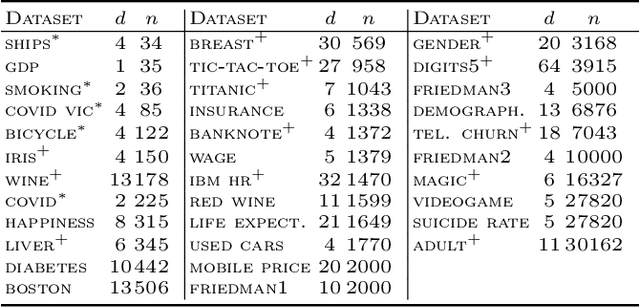
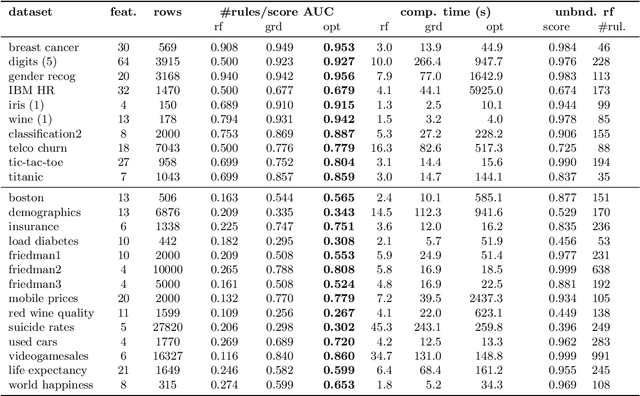
Small additive ensembles of symbolic rules offer interpretable prediction models. Traditionally, these ensembles use rule conditions based on conjunctions of simple threshold propositions $x \geq t$ on a single input variable $x$ and threshold $t$, resulting geometrically in axis-parallel polytopes as decision regions. While this form ensures a high degree of interpretability for individual rules and can be learned efficiently using the gradient boosting approach, it relies on having access to a curated set of expressive and ideally independent input features so that a small ensemble of axis-parallel regions can describe the target variable well. Absent such features, reaching sufficient accuracy requires increasing the number and complexity of individual rules, which diminishes the interpretability of the model. Here, we extend classical rule ensembles by introducing logical propositions with learnable sparse linear transformations of input variables, i.e., propositions of the form $\mathbf{x}^\mathrm{T}\mathbf{w} \geq t$, where $\mathbf{w}$ is a learnable sparse weight vector, enabling decision regions as general polytopes with oblique faces. We propose a learning method using sequential greedy optimization based on an iteratively reweighted formulation of logistic regression. Experimental results demonstrate that the proposed method efficiently constructs rule ensembles with the same test risk as state-of-the-art methods while significantly reducing model complexity across ten benchmark datasets.
Orthogonal Gradient Boosting for Simpler Additive Rule Ensembles
Feb 24, 2024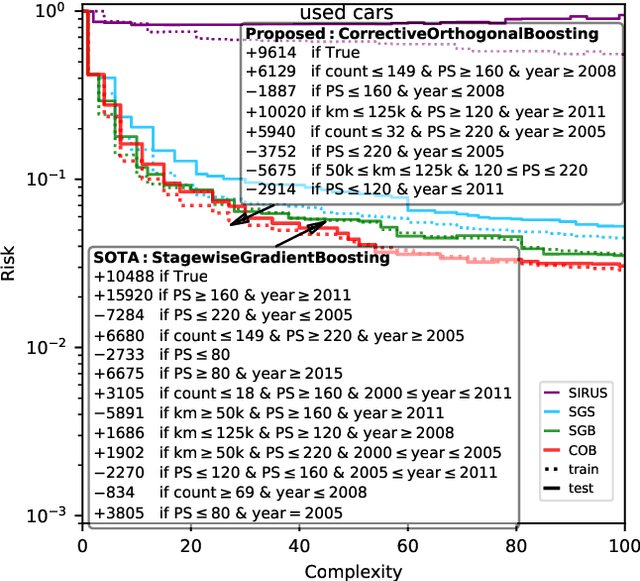
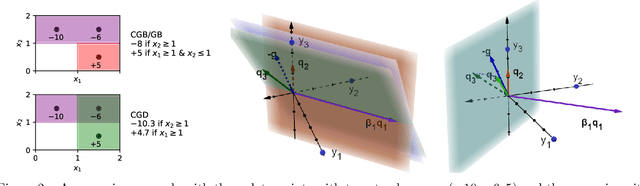
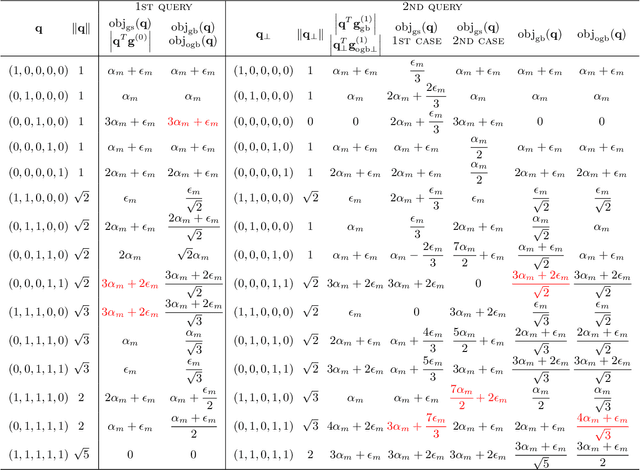
Gradient boosting of prediction rules is an efficient approach to learn potentially interpretable yet accurate probabilistic models. However, actual interpretability requires to limit the number and size of the generated rules, and existing boosting variants are not designed for this purpose. Though corrective boosting refits all rule weights in each iteration to minimise prediction risk, the included rule conditions tend to be sub-optimal, because commonly used objective functions fail to anticipate this refitting. Here, we address this issue by a new objective function that measures the angle between the risk gradient vector and the projection of the condition output vector onto the orthogonal complement of the already selected conditions. This approach correctly approximate the ideal update of adding the risk gradient itself to the model and favours the inclusion of more general and thus shorter rules. As we demonstrate using a wide range of prediction tasks, this significantly improves the comprehensibility/accuracy trade-off of the fitted ensemble. Additionally, we show how objective values for related rule conditions can be computed incrementally to avoid any substantial computational overhead of the new method.
Multi-Target Search in Euclidean Space with Ray Shooting
Jul 06, 2022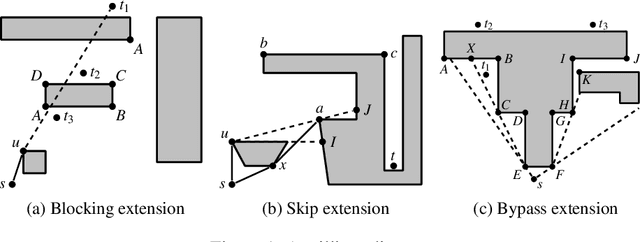
The Euclidean shortest path problem (ESPP) is a well studied problem with many practical applications. Recently a new efficient online approach to this problem, RayScan, has been developed, based on ray shooting and polygon scanning. In this paper we show how we can improve RayScan by carefully reasoning about polygon scans. We also look into how RayScan could be applied in the single-source multi-target scenario, where logic during scanning is used to reduce the number of rays shots required. This improvement also helps in the single target case. We compare the improved RayScan+ against the state-of-the-art ESPP algorithm, illustrating the situations where it is better.
Better Short than Greedy: Interpretable Models through Optimal Rule Boosting
Jan 21, 2021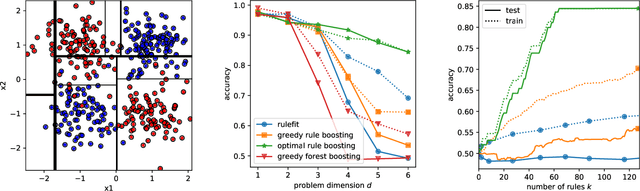
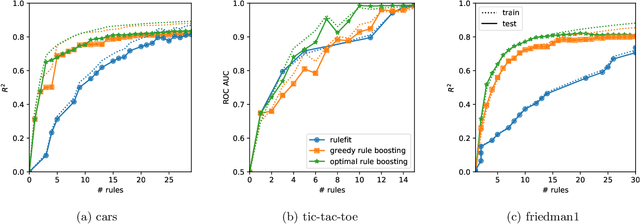
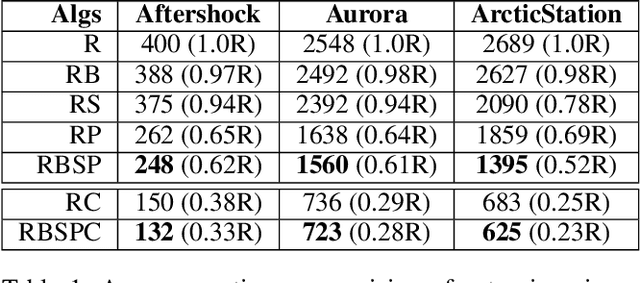
Rule ensembles are designed to provide a useful trade-off between predictive accuracy and model interpretability. However, the myopic and random search components of current rule ensemble methods can compromise this goal: they often need more rules than necessary to reach a certain accuracy level or can even outright fail to accurately model a distribution that can actually be described well with a few rules. Here, we present a novel approach aiming to fit rule ensembles of maximal predictive power for a given ensemble size (and thus model comprehensibility). In particular, we present an efficient branch-and-bound algorithm that optimally solves the per-rule objective function of the popular second-order gradient boosting framework. Our main insight is that the boosting objective can be tightly bounded in linear time of the number of covered data points. Along with an additional novel pruning technique related to rule redundancy, this leads to a computationally feasible approach for boosting optimal rules that, as we demonstrate on a wide range of common benchmark problems, consistently outperforms the predictive performance of boosting greedy rules.
Optimal Decision Lists using SAT
Oct 19, 2020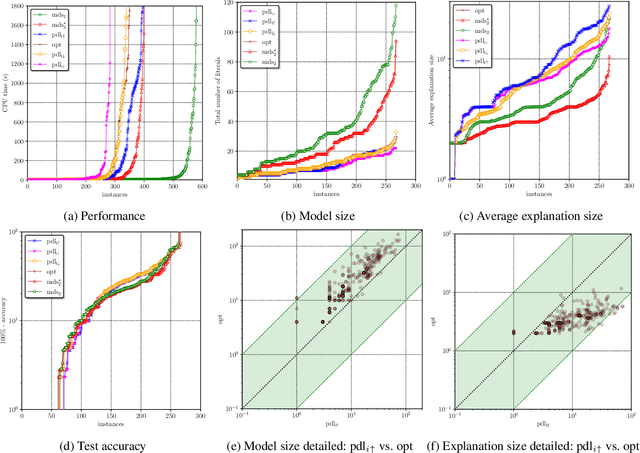
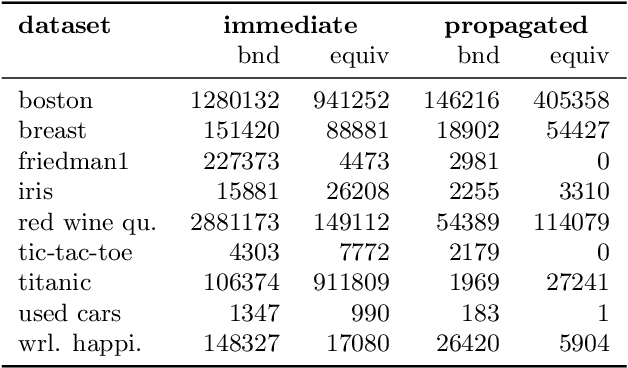
Decision lists are one of the most easily explainable machine learning models. Given the renewed emphasis on explainable machine learning decisions, this machine learning model is increasingly attractive, combining small size and clear explainability. In this paper, we show for the first time how to construct optimal "perfect" decision lists which are perfectly accurate on the training data, and minimal in size, making use of modern SAT solving technology. We also give a new method for determining optimal sparse decision lists, which trade off size and accuracy. We contrast the size and test accuracy of optimal decisions lists versus optimal decision sets, as well as other state-of-the-art methods for determining optimal decision lists. We also examine the size of average explanations generated by decision sets and decision lists.
Computing Optimal Decision Sets with SAT
Jul 29, 2020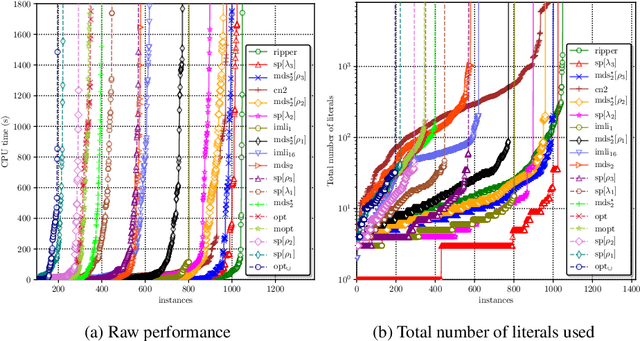
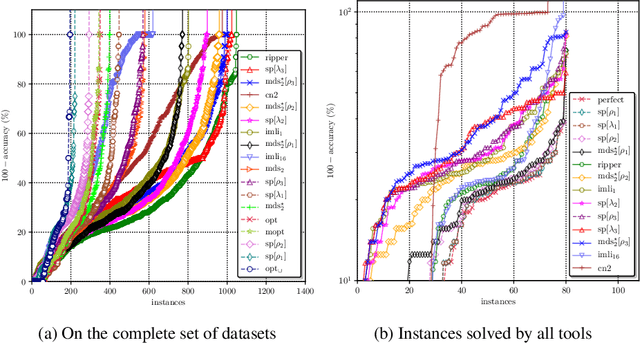
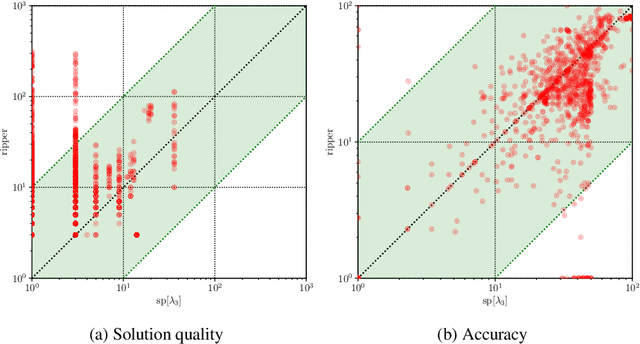
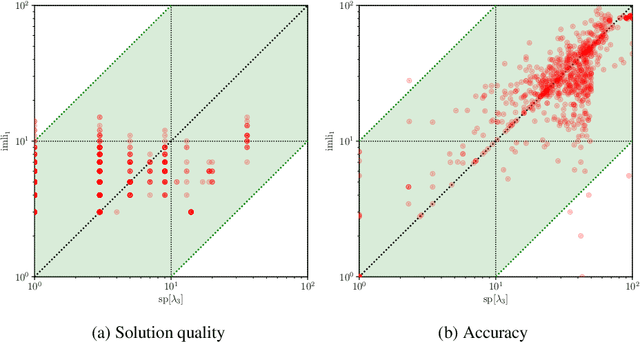
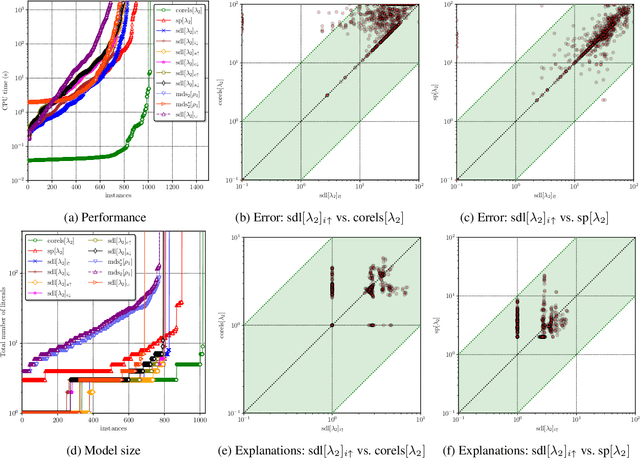
As machine learning is increasingly used to help make decisions, there is a demand for these decisions to be explainable. Arguably, the most explainable machine learning models use decision rules. This paper focuses on decision sets, a type of model with unordered rules, which explains each prediction with a single rule. In order to be easy for humans to understand, these rules must be concise. Earlier work on generating optimal decision sets first minimizes the number of rules, and then minimizes the number of literals, but the resulting rules can often be very large. Here we consider a better measure, namely the total size of the decision set in terms of literals. So we are not driven to a small set of rules which require a large number of literals. We provide the first approach to determine minimum-size decision sets that achieve minimum empirical risk and then investigate sparse alternatives where we trade accuracy for size. By finding optimal solutions we show we can build decision set classifiers that are almost as accurate as the best heuristic methods, but far more concise, and hence more explainable.