 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Short than Greedy: Interpretable Models through Optimal Rule Boosting
Jan 21, 2021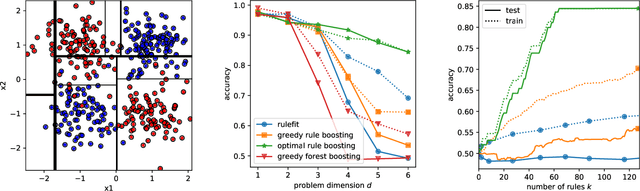
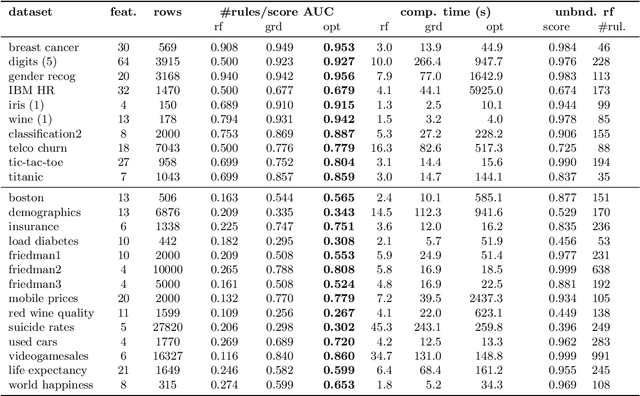
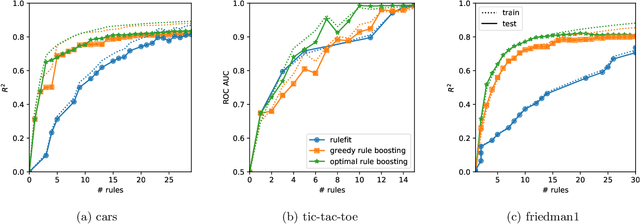
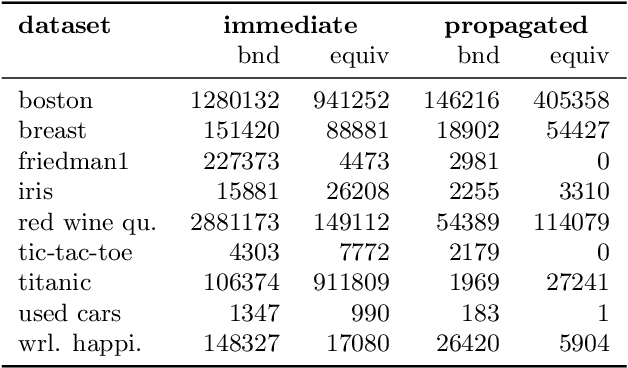
Rule ensembles are designed to provide a useful trade-off between predictive accuracy and model interpretability. However, the myopic and random search components of current rule ensemble methods can compromise this goal: they often need more rules than necessary to reach a certain accuracy level or can even outright fail to accurately model a distribution that can actually be described well with a few rules. Here, we present a novel approach aiming to fit rule ensembles of maximal predictive power for a given ensemble size (and thus model comprehensibility). In particular, we present an efficient branch-and-bound algorithm that optimally solves the per-rule objective function of the popular second-order gradient boosting framework. Our main insight is that the boosting objective can be tightly bounded in linear time of the number of covered data points. Along with an additional novel pruning technique related to rule redundancy, this leads to a computationally feasible approach for boosting optimal rules that, as we demonstrate on a wide range of common benchmark problems, consistently outperforms the predictive performance of boosting greedy rules.
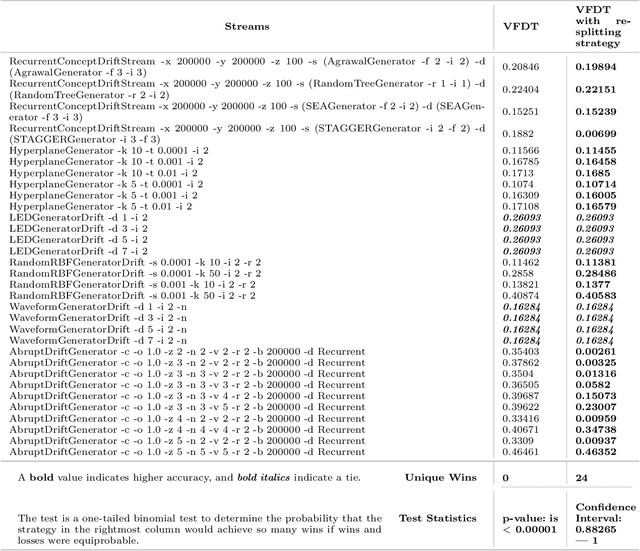
An Eager Splitting Strategy for Online Decision Trees
Oct 20, 2020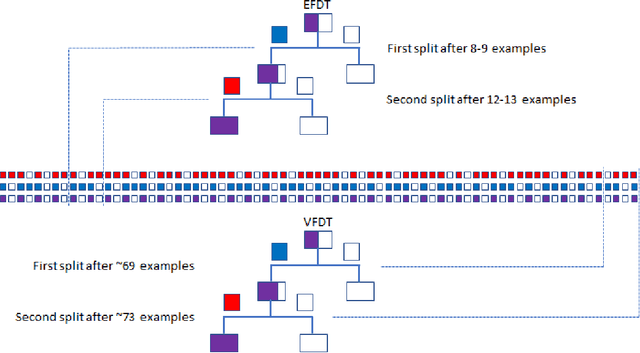


We study the effectiveness of replacing the split strategy for the state-of-the-art online tree learner, Hoeffding Tree, with a rigorous but more eager splitting strategy. Our method, Hoeffding AnyTime Tree (HATT), uses the Hoeffding Test to determine whether the current best candidate split is superior to the current split, with the possibility of revision, while Hoeffding Tree aims to determine whether the top candidate is better than the second best and fixes it for all posterity. Our method converges to the ideal batch tree while Hoeffding Tree does not. Decision tree ensembles are widely used in practice, and in this work, we study the efficacy of HATT as a base learner for online bagging and online boosting ensembles. On UCI and synthetic streams, the success of Hoeffding AnyTime Tree in terms of prequential accuracy over Hoeffding Tree is established. HATT as a base learner component outperforms HT within a 0.05 significance level for the majority of tested ensembles on what we believe is the largest and most comprehensive set of testbenches in the online learning literature. Our results indicate that HATT is a superior alternative to Hoeffding Tree in a large number of ensemble settings.
Emergent and Unspecified Behaviors in Streaming Decision Trees
Oct 16, 2020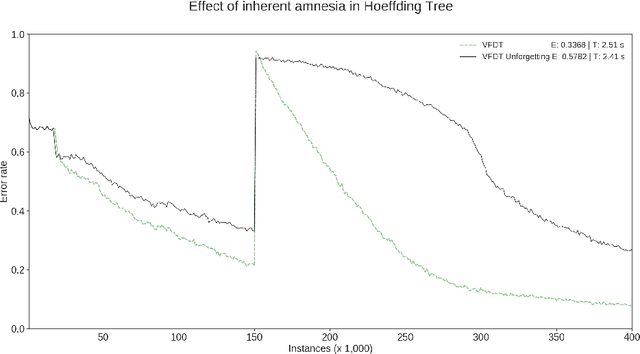


Hoeffding trees are the state-of-the-art methods in decision tree learning for evolving data streams. These very fast decision trees are used in many real applications where data is created in real-time due to their efficiency. In this work, we extricate explanations for why these streaming decision tree algorithms for stationary and nonstationary streams (HoeffdingTree and HoeffdingAdaptiveTree) work as well as they do. In doing so, we identify thirteen unique unspecified design decisions in both the theoretical constructs and their implementations with substantial and consequential effects on predictive accuracy---design decisions that, without necessarily changing the essence of the algorithms, drive algorithm performance. We begin a larger conversation about explainability not just of the model but also of the processes responsible for an algorithm's success.
Instance-Dependent PU Learning by Bayesian Optimal Relabeling
Aug 07, 2018
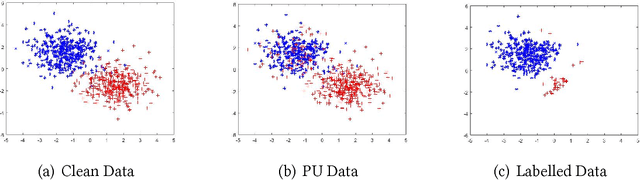

When learning from positive and unlabelled data, it is a strong assumption that the positive observations are randomly sampled from the distribution of $X$ conditional on $Y = 1$, where X stands for the feature and Y the label. Most existing algorithms are optimally designed under the assumption. However, for many real-world applications, the observed positive examples are dependent on the conditional probability $P(Y = 1|X)$ and should be sampled biasedly. In this paper, we assume that a positive example with a higher $P(Y = 1|X)$ is more likely to be labelled and propose a probabilistic-gap based PU learning algorithms. Specifically, by treating the unlabelled data as noisy negative examples, we could automatically label a group positive and negative examples whose labels are identical to the ones assigned by a Bayesian optimal classifier with a consistency guarantee. The relabelled examples have a biased domain, which is remedied by the kernel mean matching technique. The proposed algorithm is model-free and thus do not have any parameters to tune. Experimental results demonstrate that our method works well on both generated and real-world datasets.