 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent and Unspecified Behaviors in Streaming Decision Trees
Paper and Code
Oct 16, 2020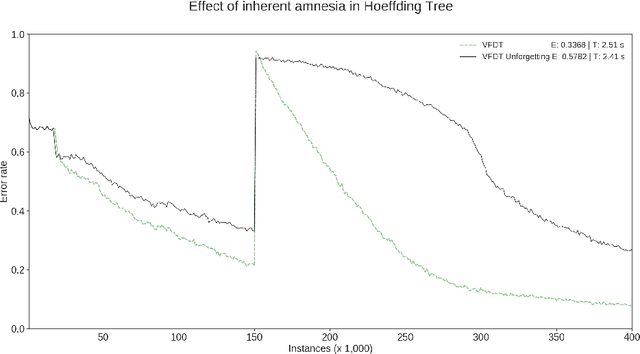
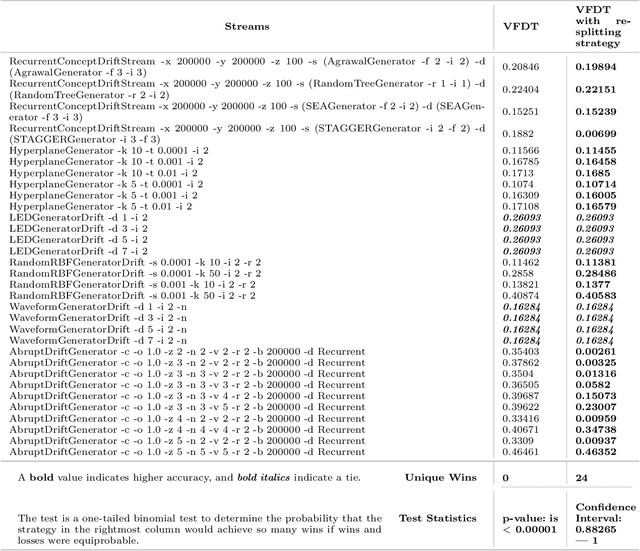


Hoeffding trees are the state-of-the-art methods in decision tree learning for evolving data streams. These very fast decision trees are used in many real applications where data is created in real-time due to their efficiency. In this work, we extricate explanations for why these streaming decision tree algorithms for stationary and nonstationary streams (HoeffdingTree and HoeffdingAdaptiveTree) work as well as they do. In doing so, we identify thirteen unique unspecified design decisions in both the theoretical constructs and their implementations with substantial and consequential effects on predictive accuracy---design decisions that, without necessarily changing the essence of the algorithms, drive algorithm performance. We begin a larger conversation about explainability not just of the model but also of the processes responsible for an algorithm's success.