 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCIGAR: A Personalized Reconstruction Approach for Federated Graph-level Anomaly Detection
May 10, 2026Graph-level anomaly detection (GLAD) is crucial for ensuring the reliability of graph-driven applications by identifying abnormal graphs that deviate from the majority. Considering the privacy concerns in distributed scenarios, federated graph-level anomaly detection (FedGLAD) has emerged as a promising solution to enable collaborative detection without sharing raw data. However, existing methods suffer from poor generalization due to the reliance on unrealistic synthetic anomalies and insufficient personalization capabilities under data heterogeneity. To address these challenges, we propose a novel Federated graph-level anomaly detection approach with Cluster-adaptIve GAted Reconstruction (FedCIGAR). Specifically, we design a reconstruction-based paradigm trained on normal graphs to avoid synthetic data. Furthermore, we introduce a client-side node contribution gating mechanism and a server-side sliding window-based clustering strategy to tackle data heterogeneity. Extensive experiments demonstrate that FedCIGAR achieves superior performance and robustness in contrast to state-of-the-art methods.
Beyond a Single Perspective: Text Anomaly Detection with Multi-View Language Representations
Jan 25, 2026Text anomaly detection (TAD) plays a critical role in various language-driven real-world applications, including harmful content moderation, phishing detection, and spam review filtering. While two-step "embedding-detector" TAD methods have shown state-of-the-art performance, their effectiveness is often limited by the use of a single embedding model and the lack of adaptability across diverse datasets and anomaly types. To address these limitations, we propose to exploit the embeddings from multiple pretrained language models and integrate them into $MCA^2$, a multi-view TAD framework. $MCA^2$ adopts a multi-view reconstruction model to effectively extract normal textual patterns from multiple embedding perspectives. To exploit inter-view complementarity, a contrastive collaboration module is designed to leverage and strengthen the interactions across different views. Moreover, an adaptive allocation module is developed to automatically assign the contribution weight of each view, thereby improving the adaptability to diverse datasets. Extensive experiments on 10 benchmark datasets verify the effectiveness of $MCA^2$ against strong baselines. The source code of $MCA^2$ is available at https://github.com/yankehan/MCA2.
DeNoise: Learning Robust Graph Representations for Unsupervised Graph-Level Anomaly Detection
Nov 06, 2025With the rapid growth of graph-structured data in critical domains, unsupervised graph-level anomaly detection (UGAD) has become a pivotal task. UGAD seeks to identify entire graphs that deviate from normal behavioral patterns. However, most Graph Neural Network (GNN) approaches implicitly assume that the training set is clean, containing only normal graphs, which is rarely true in practice. Even modest contamination by anomalous graphs can distort learned representations and sharply degrade performance. To address this challenge, we propose DeNoise, a robust UGAD framework explicitly designed for contaminated training data. It jointly optimizes a graph-level encoder, an attribute decoder, and a structure decoder via an adversarial objective to learn noise-resistant embeddings. Further, DeNoise introduces an encoder anchor-alignment denoising mechanism that fuses high-information node embeddings from normal graphs into all graph embeddings, improving representation quality while suppressing anomaly interference. A contrastive learning component then compacts normal graph embeddings and repels anomalous ones in the latent space. Extensive experiments on eight real-world datasets demonstrate that DeNoise consistently learns reliable graph-level representations under varying noise intensities and significantly outperforms state-of-the-art UGAD baselines.
Uncertainty-Aware Graph Neural Networks: A Multi-Hop Evidence Fusion Approach
Jun 16, 2025Graph neural networks (GNNs) excel in graph representation learning by integrating graph structure and node features. Existing GNNs, unfortunately, fail to account for the uncertainty of class probabilities that vary with the depth of the model, leading to unreliable and risky predictions in real-world scenarios. To bridge the gap, in this paper, we propose a novel Evidence Fusing Graph Neural Network (EFGNN for short) to achieve trustworthy prediction, enhance node classification accuracy, and make explicit the risk of wrong predictions. In particular, we integrate the evidence theory with multi-hop propagation-based GNN architecture to quantify the prediction uncertainty of each node with the consideration of multiple receptive fields. Moreover, a parameter-free cumulative belief fusion (CBF) mechanism is developed to leverage the changes in prediction uncertainty and fuse the evidence to improve the trustworthiness of the final prediction. To effectively optimize the EFGNN model, we carefully design a joint learning objective composed of evidence cross-entropy, dissonance coefficient, and false confident penalty. The experimental results on various datasets and theoretical analyses demonstrate the effectiveness of the proposed model in terms of accuracy and trustworthiness, as well as its robustness to potential attacks. The source code of EFGNN is available at https://github.com/Shiy-Li/EFGNN.
A Novel Generative Model with Causality Constraint for Mitigating Biases in Recommender Systems
May 22, 2025Accurately predicting counterfactual user feedback is essential for building effective recommender systems. However, latent confounding bias can obscure the true causal relationship between user feedback and item exposure, ultimately degrading recommendation performance. Existing causal debiasing approaches often rely on strong assumptions-such as the availability of instrumental variables (IVs) or strong correlations between latent confounders and proxy variables-that are rarely satisfied in real-world scenarios. To address these limitations, we propose a novel generative framework called Latent Causality Constraints for Debiasing representation learning in Recommender Systems (LCDR). Specifically, LCDR leverages an identifiable Variational Autoencoder (iVAE) as a causal constraint to align the latent representations learned by a standard Variational Autoencoder (VAE) through a unified loss function. This alignment allows the model to leverage even weak or noisy proxy variables to recover latent confounders effectively. The resulting representations are then used to improve recommendation performance. Extensive experiments on three real-world datasets demonstrate that LCDR consistently outperforms existing methods in both mitigating bias and improving recommendation accuracy.
A Survey of Hallucination in Large Visual Language Models
Oct 20, 2024



The Large Visual Language Models (LVLMs) enhances user interaction and enriches user experience by integrating visual modality on the basis of the Large Language Models (LLMs). It has demonstrated their powerful information processing and generation capabilities. However, the existence of hallucinations has limited the potential and practical effectiveness of LVLM in various fields. Although lots of work has been devoted to the issue of hallucination mitigation and correction, there are few reviews to summary this issue. In this survey, we first introduce the background of LVLMs and hallucinations. Then, the structure of LVLMs and main causes of hallucination generation are introduced. Further, we summary recent works on hallucination correction and mitigation. In addition, the available hallucination evaluation benchmarks for LVLMs are presented from judgmental and generative perspectives. Finally, we suggest some future research directions to enhance the dependability and utility of LVLMs.
Mitigating Dual Latent Confounding Biases in Recommender Systems
Oct 16, 2024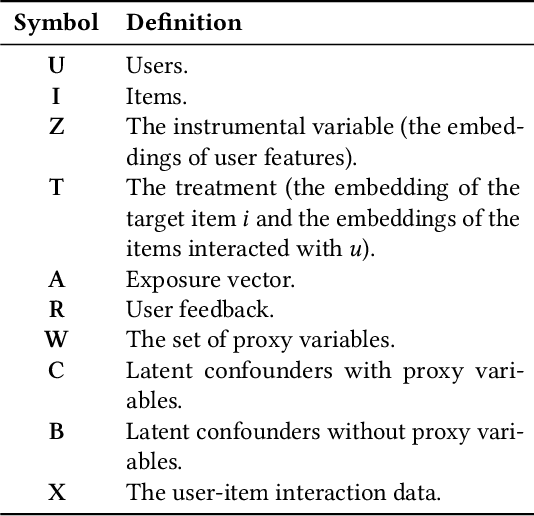
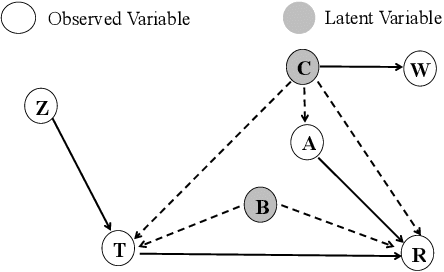
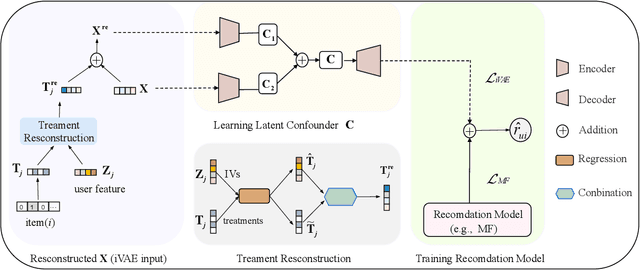
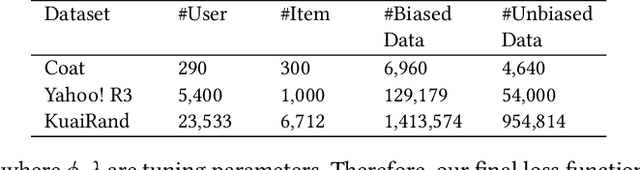
Recommender systems are extensively utilised across various areas to predict user preferences for personalised experiences and enhanced user engagement and satisfaction. Traditional recommender systems, however, are complicated by confounding bias, particularly in the presence of latent confounders that affect both item exposure and user feedback. Existing debiasing methods often fail to capture the complex interactions caused by latent confounders in interaction data, especially when dual latent confounders affect both the user and item sides. To address this, we propose a novel debiasing method that jointly integrates the Instrumental Variables (IV) approach and identifiable Variational Auto-Encoder (iVAE) for Debiased representation learning in Recommendation systems, referred to as IViDR. Specifically, IViDR leverages the embeddings of user features as IVs to address confounding bias caused by latent confounders between items and user feedback, and reconstructs the embedding of items to obtain debiased interaction data. Moreover, IViDR employs an Identifiable Variational Auto-Encoder (iVAE) to infer identifiable representations of latent confounders between item exposure and user feedback from both the original and debiased interaction data. Additionally, we provide theoretical analyses of the soundness of using IV and the identifiability of the latent representations. Extensive experiments on both synthetic and real-world datasets demonstrate that IViDR outperforms state-of-the-art models in reducing bias and providing reliable recommendations.
Noise-Resilient Unsupervised Graph Representation Learning via Multi-Hop Feature Quality Estimation
Jul 29, 2024



Unsupervised graph representation learning (UGRL) based on graph neural networks (GNNs), has received increasing attention owing to its efficacy in handling graph-structured data. However, existing UGRL methods ideally assume that the node features are noise-free, which makes them fail to distinguish between useful information and noise when applied to real data with noisy features, thus affecting the quality of learned representations. This urges us to take node noisy features into account in real-world UGRL. With empirical analysis, we reveal that feature propagation, the essential operation in GNNs, acts as a "double-edged sword" in handling noisy features - it can both denoise and diffuse noise, leading to varying feature quality across nodes, even within the same node at different hops. Building on this insight, we propose a novel UGRL method based on Multi-hop feature Quality Estimation (MQE for short). Unlike most UGRL models that directly utilize propagation-based GNNs to generate representations, our approach aims to learn representations through estimating the quality of propagated features at different hops. Specifically, we introduce a Gaussian model that utilizes a learnable "meta-representation" as a condition to estimate the expectation and variance of multi-hop propagated features via neural networks. In this way, the "meta representation" captures the semantic and structural information underlying multiple propagated features but is naturally less susceptible to interference by noise, thereby serving as high-quality node representations beneficial for downstream tasks. Extensive experiments on multiple real-world datasets demonstrate that MQE in learning reliable node representations in scenarios with diverse types of feature noise.
Transformer-based Single-Cell Language Model: A Survey
Jul 18, 2024The transformers have achieved significant accomplishments in the natural language processing as its outstanding parallel processing capabilities and highly flexible attention mechanism. In addition, increasing studies based on transformers have been proposed to model single-cell data. In this review, we attempt to systematically summarize the single-cell language models and applications based on transformers. First, we provide a detailed introduction about the structure and principles of transformers. Then, we review the single-cell language models and large language models for single-cell data analysis. Moreover, we explore the datasets and applications of single-cell language models in downstream tasks such as batch correction, cell clustering, cell type annotation, gene regulatory network inference and perturbation response. Further, we discuss the challenges of single-cell language models and provide promising research directions. We hope this review will serve as an up-to-date reference for researchers interested in the direction of single-cell language models.
ARC: A Generalist Graph Anomaly Detector with In-Context Learning
May 27, 2024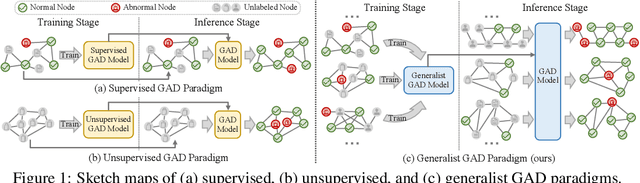

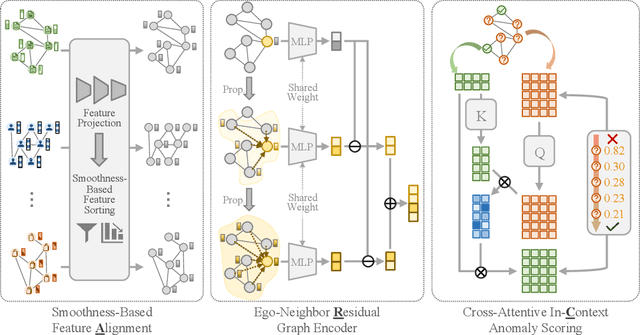
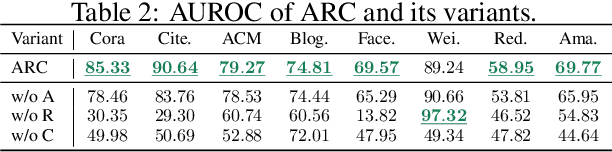
Graph anomaly detection (GAD), which aims to identify abnormal nodes that differ from the majority within a graph, has garnered significant attention. However, current GAD methods necessitate training specific to each dataset, resulting in high training costs, substantial data requirements, and limited generalizability when being applied to new datasets and domains. To address these limitations, this paper proposes ARC, a generalist GAD approach that enables a ``one-for-all'' GAD model to detect anomalies across various graph datasets on-the-fly. Equipped with in-context learning, ARC can directly extract dataset-specific patterns from the target dataset using few-shot normal samples at the inference stage, without the need for retraining or fine-tuning on the target dataset. ARC comprises three components that are well-crafted for capturing universal graph anomaly patterns: 1) smoothness-based feature Alignment module that unifies the features of different datasets into a common and anomaly-sensitive space; 2) ego-neighbor Residual graph encoder that learns abnormality-related node embeddings; and 3) cross-attentive in-Context anomaly scoring module that predicts node abnormality by leveraging few-shot normal samples. Extensive experiments on multiple benchmark datasets from various domains demonstrate the superior anomaly detection performance, efficiency, and generalizability of ARC.