 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Hallucination in Large Visual Language Models
Oct 20, 2024



The Large Visual Language Models (LVLMs) enhances user interaction and enriches user experience by integrating visual modality on the basis of the Large Language Models (LLMs). It has demonstrated their powerful information processing and generation capabilities. However, the existence of hallucinations has limited the potential and practical effectiveness of LVLM in various fields. Although lots of work has been devoted to the issue of hallucination mitigation and correction, there are few reviews to summary this issue. In this survey, we first introduce the background of LVLMs and hallucinations. Then, the structure of LVLMs and main causes of hallucination generation are introduced. Further, we summary recent works on hallucination correction and mitigation. In addition, the available hallucination evaluation benchmarks for LVLMs are presented from judgmental and generative perspectives. Finally, we suggest some future research directions to enhance the dependability and utility of LVLMs.
Unsupervised Foggy Scene Understanding via Self Spatial-Temporal Label Diffusion
Jun 10, 2022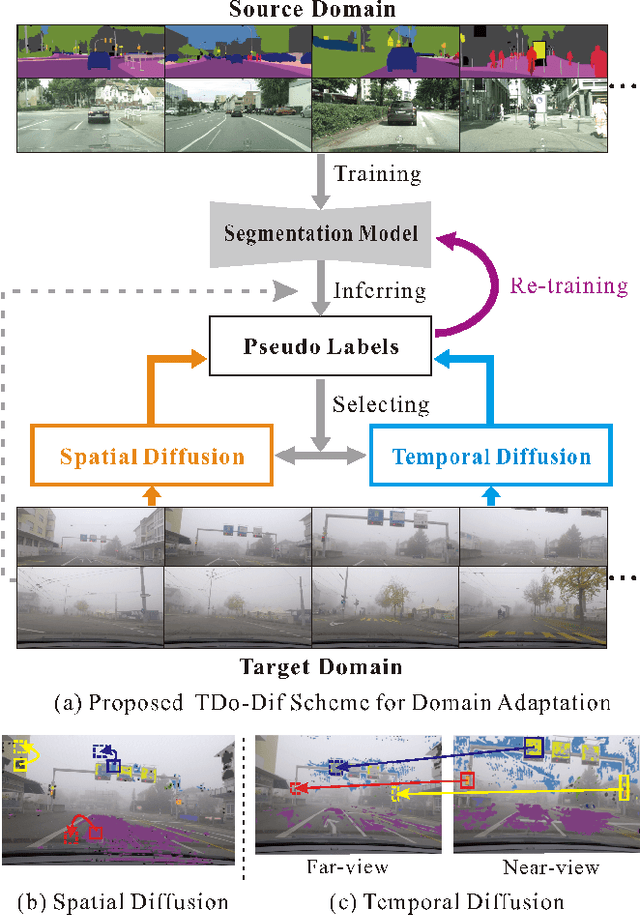
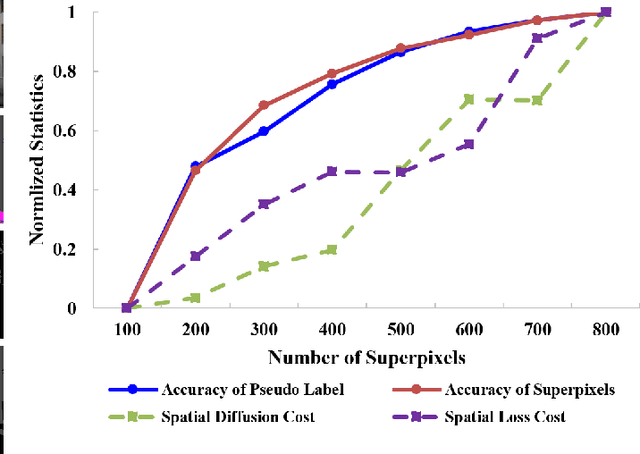
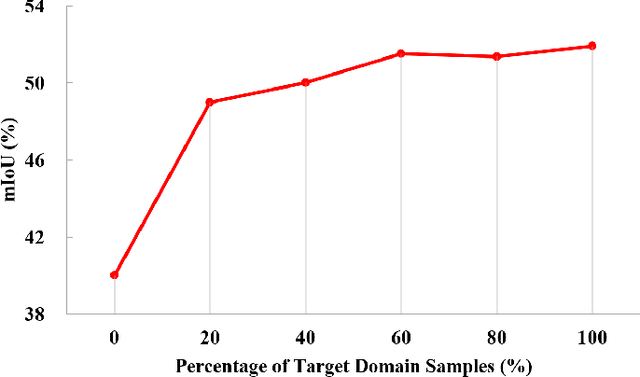
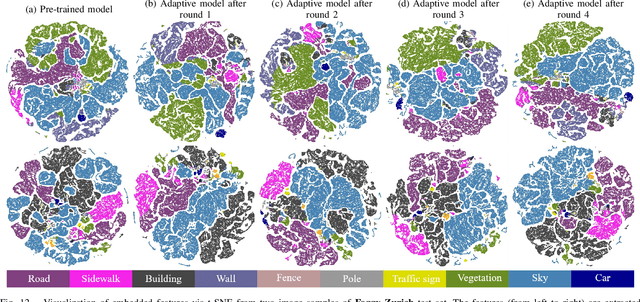
Understanding foggy image sequence in the driving scenes is critical for autonomous driving, but it remains a challenging task due to the difficulty in collecting and annotating real-world images of adverse weather. Recently, the self-training strategy has been considered a powerful solution for unsupervised domain adaptation, which iteratively adapts the model from the source domain to the target domain by generating target pseudo labels and re-training the model. However, the selection of confident pseudo labels inevitably suffers from the conflict between sparsity and accuracy, both of which will lead to suboptimal models. To tackle this problem, we exploit the characteristics of the foggy image sequence of driving scenes to densify the confident pseudo labels. Specifically, based on the two discoveries of local spatial similarity and adjacent temporal correspondence of the sequential image data, we propose a novel Target-Domain driven pseudo label Diffusion (TDo-Dif) scheme. It employs superpixels and optical flows to identify the spatial similarity and temporal correspondence, respectively and then diffuses the confident but sparse pseudo labels within a superpixel or a temporal corresponding pair linked by the flow. Moreover, to ensure the feature similarity of the diffused pixels, we introduce local spatial similarity loss and temporal contrastive loss in the model re-training stage. Experimental results show that our TDo-Dif scheme helps the adaptive model achieve 51.92% and 53.84% mean intersection-over-union (mIoU) on two publicly available natural foggy datasets (Foggy Zurich and Foggy Driving), which exceeds the state-of-the-art unsupervised domain adaptive semantic segmentation methods. Models and data can be found at https://github.com/velor2012/TDo-Dif.