 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Transformer Tracker with Correlative Masked Modeling
Paper and Code
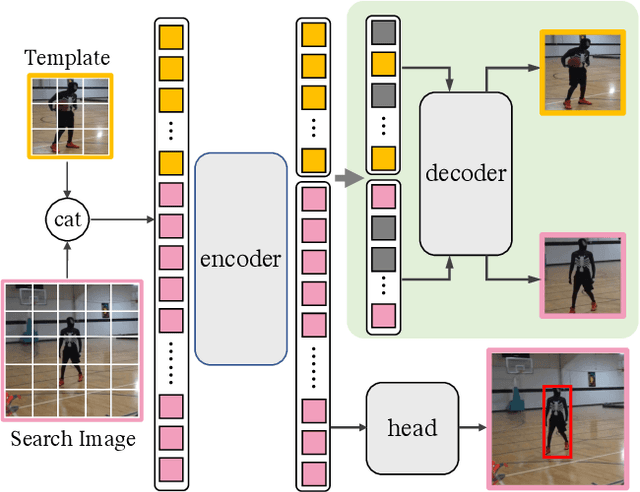



Transformer framework has been showing superior performances in visual object tracking for its great strength in information aggregation across the template and search image with the well-known attention mechanism. Most recent advances focus on exploring attention mechanism variants for better information aggregation. We find these schemes are equivalent to or even just a subset of the basic self-attention mechanism. In this paper, we prove that the vanilla self-attention structure is sufficient for information aggregation, and structural adaption is unnecessary. The key is not the attention structure, but how to extract the discriminative feature for tracking and enhance the communication between the target and search image. Based on this finding, we adopt the basic vision transformer (ViT) architecture as our main tracker and concatenate the template and search image for feature embedding. To guide the encoder to capture the invariant feature for tracking, we attach a lightweight correlative masked decoder which reconstructs the original template and search image from the corresponding masked tokens. The correlative masked decoder serves as a plugin for the compact transform tracker and is skipped in inference. Our compact tracker uses the most simple structure which only consists of a ViT backbone and a box head, and can run at 40 fps. Extensive experiments show the proposed compact transform tracker outperforms existing approaches, including advanced attention variants, and demonstrates the sufficiency of self-attention in tracking tasks. Our method achieves state-of-the-art performance on five challenging datasets, along with the VOT2020, UAV123, LaSOT, TrackingNet, and GOT-10k benchmarks. Our project is available at https://github.com/HUSTDML/CTTrack.