 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete-Time Mean Field Control with Environment States
Paper and Code
Apr 30, 2021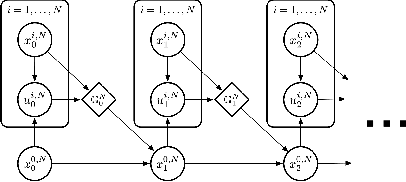

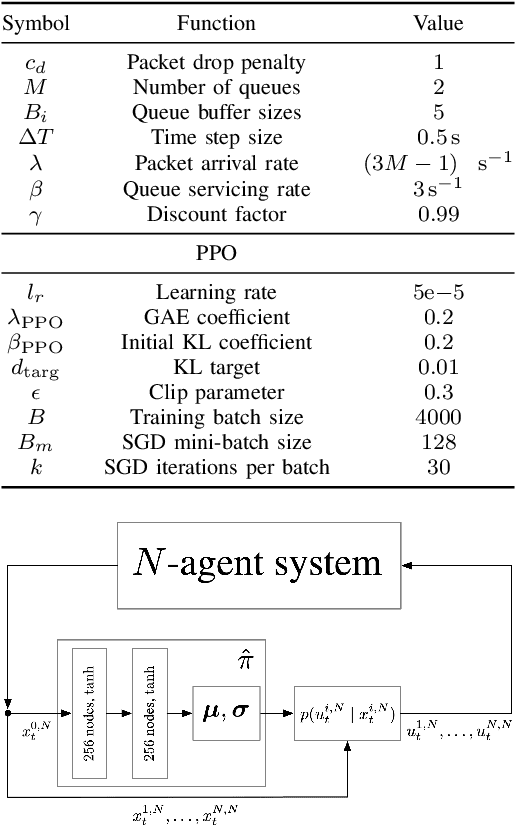
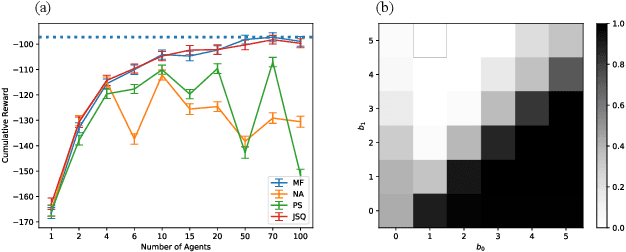
Multi-agent reinforcement learning methods have shown remarkable potential in solving complex multi-agent problems but mostly lack theoretical guarantees. Recently, mean field control and mean field games have been established as a tractable solution for large-scale multi-agent problems with many agents. In this work, driven by a motivating scheduling problem, we consider a discrete-time mean field control model with common environment states. We rigorously establish approximate optimality as the number of agents grows in the finite agent case and find that a dynamic programming principle holds, resulting in the existence of an optimal stationary policy. As exact solutions are difficult in general due to the resulting continuous action space of the limiting mean field Markov decision process, we apply established deep reinforcement learning methods to solve the associated mean field control problem. The performance of the learned mean field control policy is compared to typical multi-agent reinforcement learning approaches and is found to converge to the mean field performance for sufficiently many agents, verifying the obtained theoretical results and reaching competitive solutions.