 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial training of Keyword Spotting to Minimize TTS Data Overfitting
Aug 20, 2024



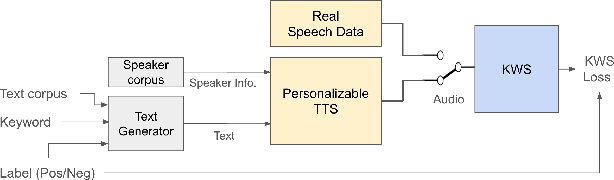
The keyword spotting (KWS) problem requires large amounts of real speech training data to achieve high accuracy across diverse populations. Utilizing large amounts of text-to-speech (TTS) synthesized data can reduce the cost and time associated with KWS development. However, TTS data may contain artifacts not present in real speech, which the KWS model can exploit (overfit), leading to degraded accuracy on real speech. To address this issue, we propose applying an adversarial training method to prevent the KWS model from learning TTS-specific features when trained on large amounts of TTS data. Experimental results demonstrate that KWS model accuracy on real speech data can be improved by up to 12% when adversarial loss is used in addition to the original KWS loss. Surprisingly, we also observed that the adversarial setup improves accuracy by up to 8%, even when trained solely on TTS and real negative speech data, without any real positive examples.
Utilizing TTS Synthesized Data for Efficient Development of Keyword Spotting Model
Jul 26, 2024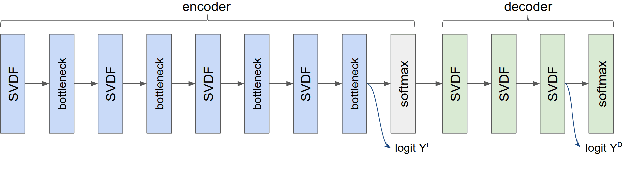
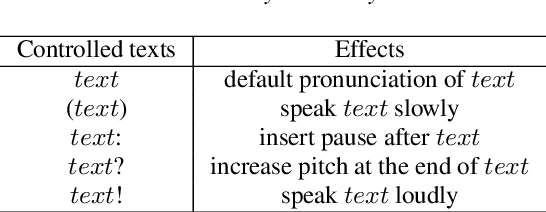

This paper explores the use of TTS synthesized training data for KWS (keyword spotting) task while minimizing development cost and time. Keyword spotting models require a huge amount of training data to be accurate, and obtaining such training data can be costly. In the current state of the art, TTS models can generate large amounts of natural-sounding data, which can help reducing cost and time for KWS model development. Still, TTS generated data can be lacking diversity compared to real data. To pursue maximizing KWS model accuracy under the constraint of limited resources and current TTS capability, we explored various strategies to mix TTS data and real human speech data, with a focus on minimizing real data use and maximizing diversity of TTS output. Our experimental results indicate that relatively small amounts of real audio data with speaker diversity (100 speakers, 2k utterances) and large amounts of TTS synthesized data can achieve reasonably high accuracy (within 3x error rate of baseline), compared to the baseline (trained with 3.8M real positive utterances).
Free resolutions of function classes via order complexes
Sep 05, 2019
Function classes are collections of Boolean functions on a finite set, which are fundamental objects of study in theoretical computer science. We study algebraic properties of ideals associated to function classes previously defined by the third author. We consider the broad family of intersection-closed function classes, and describe cellular free resolutions of their ideals by order complexes of the associated posets. For function classes arising from matroids, polyhedral cell complexes, and more generally interval Cohen-Macaulay posets, we show that the multigraded Betti numbers are pure, and are given combinatorially by the M\"obius functions. We then apply our methods to derive bounds on the VC dimension of some important families of function classes in learning theory.
CrossTrainer: Practical Domain Adaptation with Loss Reweighting
May 07, 2019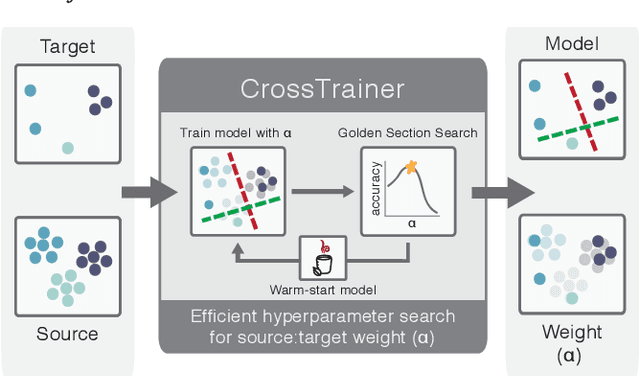

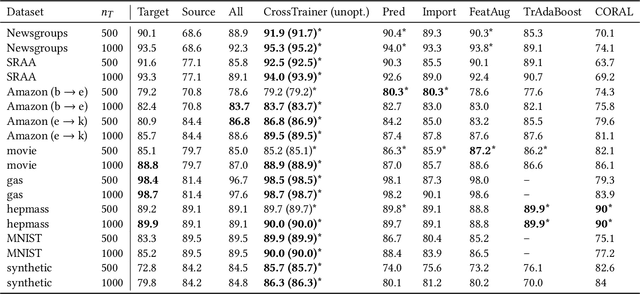
Domain adaptation provides a powerful set of model training techniques given domain-specific training data and supplemental data with unknown relevance. The techniques are useful when users need to develop models with data from varying sources, of varying quality, or from different time ranges. We build CrossTrainer, a system for practical domain adaptation. CrossTrainer utilizes loss reweighting, which provides consistently high model accuracy across a variety of datasets in our empirical analysis. However, loss reweighting is sensitive to the choice of a weight hyperparameter that is expensive to tune. We develop optimizations leveraging unique properties of loss reweighting that allow CrossTrainer to output accurate models while improving training time compared to naive hyperparameter search.
Combinatorially Generated Piecewise Activation Functions
May 17, 2016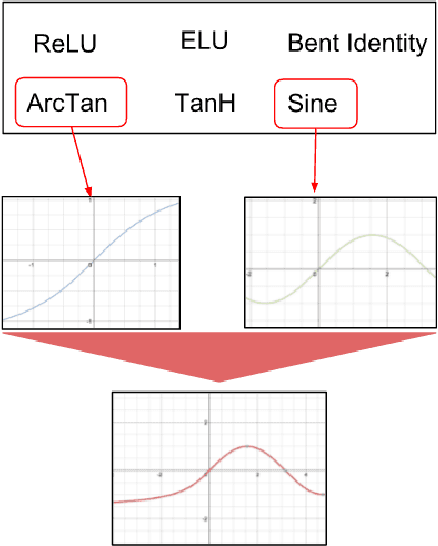
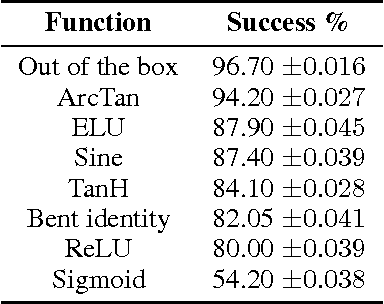
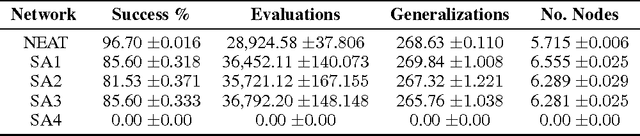
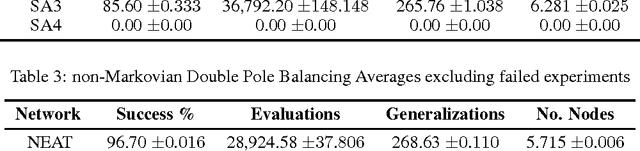
In the neuroevolution literature, research has primarily focused on evolving the number of nodes, connections, and weights in artificial neural networks. Few attempts have been made to evolve activation functions. Research in evolving activation functions has mainly focused on evolving function parameters, and developing heterogeneous networks by selecting from a fixed pool of activation functions. This paper introduces a novel technique for evolving heterogeneous artificial neural networks through combinatorially generating piecewise activation functions to enhance expressive power. I demonstrate this technique on NeuroEvolution of Augmenting Topologies using ArcTan and Sigmoid, and show that it outperforms the original algorithm on non-Markovian double pole balancing. This technique expands the landscape of unconventional activation functions by demonstrating that they are competitive with canonical choices, and introduces a purview for further exploration of automatic model selection for artificial neural networks.