 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial training of Keyword Spotting to Minimize TTS Data Overfitting
Aug 20, 2024



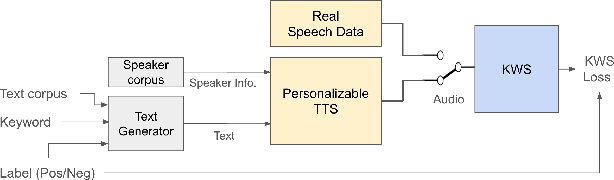
The keyword spotting (KWS) problem requires large amounts of real speech training data to achieve high accuracy across diverse populations. Utilizing large amounts of text-to-speech (TTS) synthesized data can reduce the cost and time associated with KWS development. However, TTS data may contain artifacts not present in real speech, which the KWS model can exploit (overfit), leading to degraded accuracy on real speech. To address this issue, we propose applying an adversarial training method to prevent the KWS model from learning TTS-specific features when trained on large amounts of TTS data. Experimental results demonstrate that KWS model accuracy on real speech data can be improved by up to 12% when adversarial loss is used in addition to the original KWS loss. Surprisingly, we also observed that the adversarial setup improves accuracy by up to 8%, even when trained solely on TTS and real negative speech data, without any real positive examples.
Utilizing TTS Synthesized Data for Efficient Development of Keyword Spotting Model
Jul 26, 2024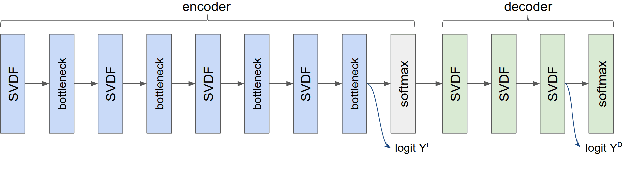
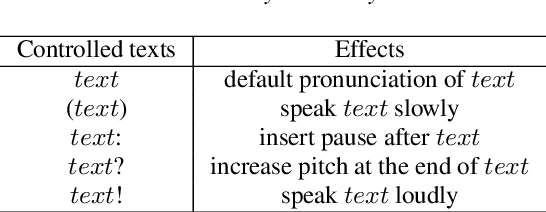

This paper explores the use of TTS synthesized training data for KWS (keyword spotting) task while minimizing development cost and time. Keyword spotting models require a huge amount of training data to be accurate, and obtaining such training data can be costly. In the current state of the art, TTS models can generate large amounts of natural-sounding data, which can help reducing cost and time for KWS model development. Still, TTS generated data can be lacking diversity compared to real data. To pursue maximizing KWS model accuracy under the constraint of limited resources and current TTS capability, we explored various strategies to mix TTS data and real human speech data, with a focus on minimizing real data use and maximizing diversity of TTS output. Our experimental results indicate that relatively small amounts of real audio data with speaker diversity (100 speakers, 2k utterances) and large amounts of TTS synthesized data can achieve reasonably high accuracy (within 3x error rate of baseline), compared to the baseline (trained with 3.8M real positive utterances).
Recurrent Graph Neural Networks for Rumor Detection in Online Forums
Aug 08, 2021


The widespread adoption of online social networks in daily life has created a pressing need for effectively classifying user-generated content. This work presents techniques for classifying linked content spread on forum websites -- specifically, links to news articles or blogs -- using user interaction signals alone. Importantly, online forums such as Reddit do not have a user-generated social graph, which is assumed in social network behavioral-based classification settings. Using Reddit as a case-study, we show how to obtain a derived social graph, and use this graph, Reddit post sequences, and comment trees as inputs to a Recurrent Graph Neural Network (R-GNN) encoder. We train the R-GNN on news link categorization and rumor detection, showing superior results to recent baselines. Our code is made publicly available at https://github.com/google-research/social_cascades.