 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing TTS Synthesized Data for Efficient Development of Keyword Spotting Model
Paper and Code
Jul 26, 2024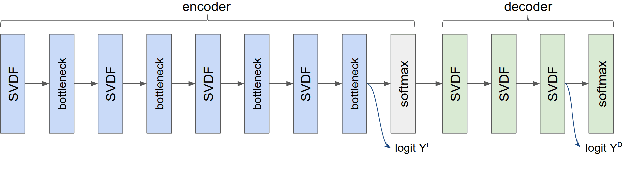
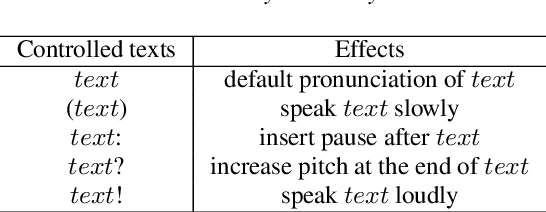
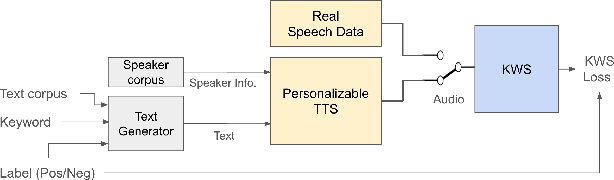

This paper explores the use of TTS synthesized training data for KWS (keyword spotting) task while minimizing development cost and time. Keyword spotting models require a huge amount of training data to be accurate, and obtaining such training data can be costly. In the current state of the art, TTS models can generate large amounts of natural-sounding data, which can help reducing cost and time for KWS model development. Still, TTS generated data can be lacking diversity compared to real data. To pursue maximizing KWS model accuracy under the constraint of limited resources and current TTS capability, we explored various strategies to mix TTS data and real human speech data, with a focus on minimizing real data use and maximizing diversity of TTS output. Our experimental results indicate that relatively small amounts of real audio data with speaker diversity (100 speakers, 2k utterances) and large amounts of TTS synthesized data can achieve reasonably high accuracy (within 3x error rate of baseline), compared to the baseline (trained with 3.8M real positive utterances).