 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed Encoder Self-Attention Patterns in Transformer-Based Machine Translation
Paper and Code
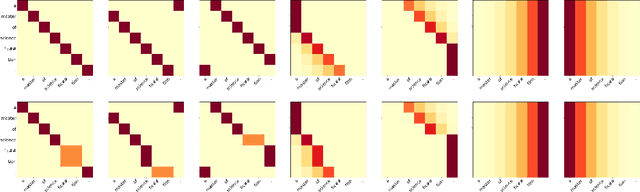

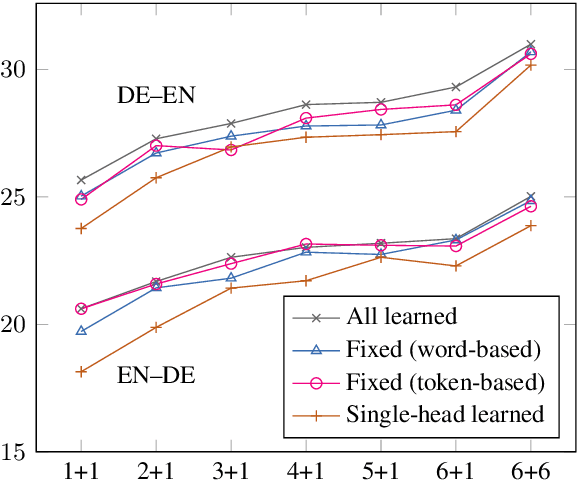

Transformer-based models have brought a radical change to neural machine translation. A key feature of the Transformer architecture is the so-called multi-head attention mechanism, which allows the model to focus simultaneously on different parts of the input. However, recent works have shown that attention heads learn simple positional patterns which are often redundant. In this paper, we propose to replace all but one attention head of each encoder layer with fixed -- non-learnable -- attentive patterns that are solely based on position and do not require any external knowledge. Our experiments show that fixing the attention heads on the encoder side of the Transformer at training time does not impact the translation quality and even increases BLEU scores by up to 3 points in low-resource scenarios.