 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual NMT with a language-independent attention bridge
Paper and Code

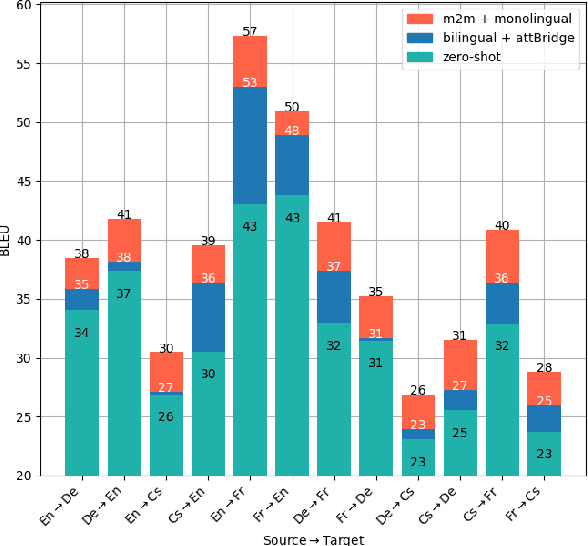
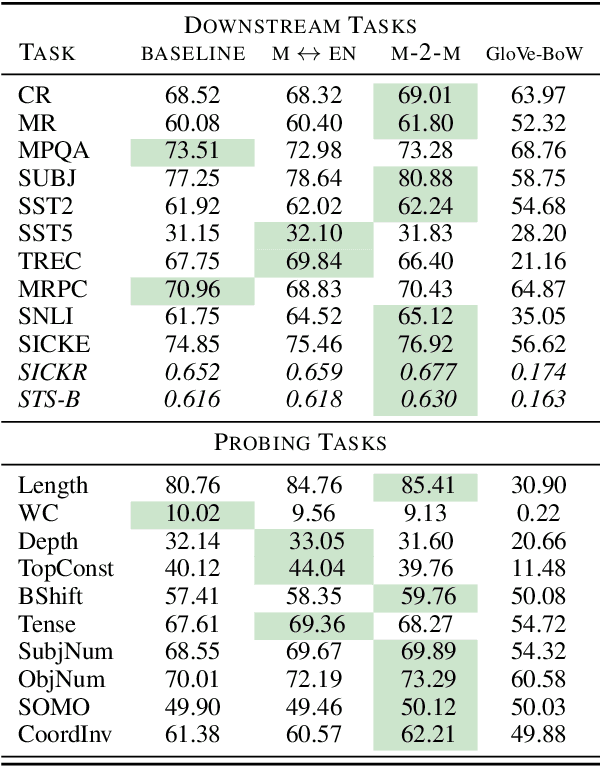
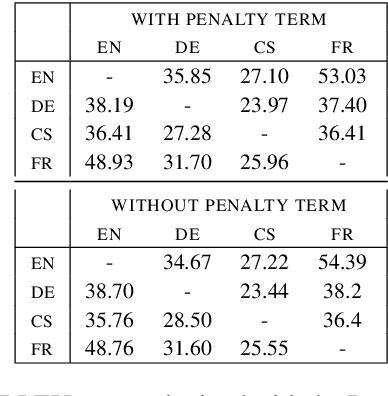
In this paper, we propose a multilingual encoder-decoder architecture capable of obtaining multilingual sentence representations by means of incorporating an intermediate {\em attention bridge} that is shared across all languages. That is, we train the model with language-specific encoders and decoders that are connected via self-attention with a shared layer that we call attention bridge. This layer exploits the semantics from each language for performing translation and develops into a language-independent meaning representation that can efficiently be used for transfer learning. We present a new framework for the efficient development of multilingual NMT using this model and scheduled training. We have tested the approach in a systematic way with a multi-parallel data set. We show that the model achieves substantial improvements over strong bilingual models and that it also works well for zero-shot translation, which demonstrates its ability of abstraction and transfer learning.