 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuSQuAD: Automatically Translated and Aligned SQuAD2.0 for Basque
Apr 18, 2024The widespread availability of Question Answering (QA) datasets in English has greatly facilitated the advancement of the Natural Language Processing (NLP) field. However, the scarcity of such resources for minority languages, such as Basque, poses a substantial challenge for these communities. In this context, the translation and alignment of existing QA datasets plays a crucial role in narrowing this technological gap. This work presents EuSQuAD, the first initiative dedicated to automatically translating and aligning SQuAD2.0 into Basque, resulting in more than 142k QA examples. We demonstrate EuSQuAD's value through extensive qualitative analysis and QA experiments supported with EuSQuAD as training data. These experiments are evaluated with a new human-annotated dataset.
Sensitive Data Detection and Classification in Spanish Clinical Text: Experiments with BERT
Mar 17, 2020
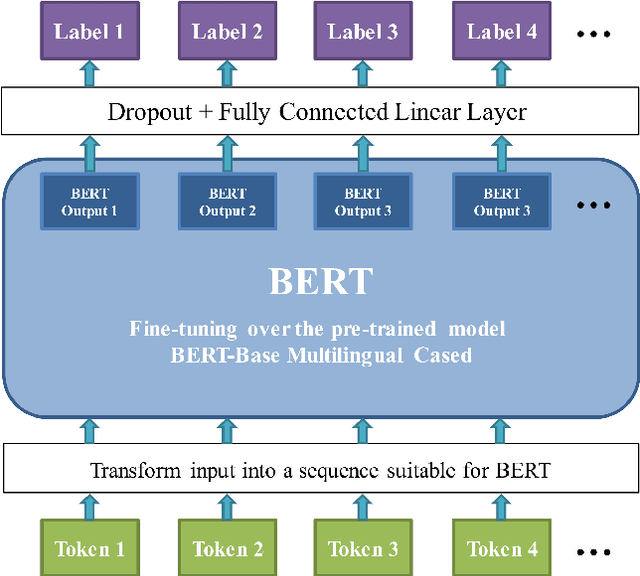


Massive digital data processing provides a wide range of opportunities and benefits, but at the cost of endangering personal data privacy. Anonymisation consists in removing or replacing sensitive information from data, enabling its exploitation for different purposes while preserving the privacy of individuals. Over the years, a lot of automatic anonymisation systems have been proposed; however, depending on the type of data, the target language or the availability of training documents, the task remains challenging still. The emergence of novel deep-learning models during the last two years has brought large improvements to the state of the art in the field of Natural Language Processing. These advancements have been most noticeably led by BERT, a model proposed by Google in 2018, and the shared language models pre-trained on millions of documents. In this paper, we use a BERT-based sequence labelling model to conduct a series of anonymisation experiments on several clinical datasets in Spanish. We also compare BERT to other algorithms. The experiments show that a simple BERT-based model with general-domain pre-training obtains highly competitive results without any domain specific feature engineering.
Hate Speech Dataset from a White Supremacy Forum
Sep 12, 2018
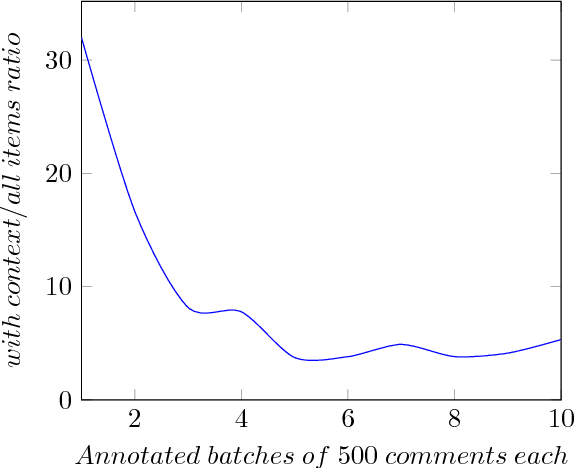

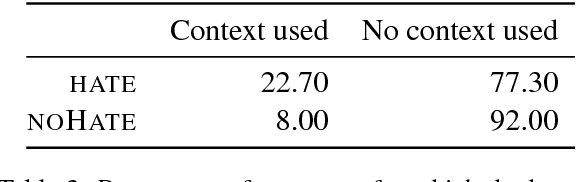
Hate speech is commonly defined as any communication that disparages a target group of people based on some characteristic such as race, colour, ethnicity, gender, sexual orientation, nationality, religion, or other characteristic. Due to the massive rise of user-generated web content on social media, the amount of hate speech is also steadily increasing. Over the past years, interest in online hate speech detection and, particularly, the automation of this task has continuously grown, along with the societal impact of the phenomenon. This paper describes a hate speech dataset composed of thousands of sentences manually labelled as containing hate speech or not. The sentences have been extracted from Stormfront, a white supremacist forum. A custom annotation tool has been developed to carry out the manual labelling task which, among other things, allows the annotators to choose whether to read the context of a sentence before labelling it. The paper also provides a thoughtful qualitative and quantitative study of the resulting dataset and several baseline experiments with different classification models. The dataset is publicly available.
W2VLDA: Almost Unsupervised System for Aspect Based Sentiment Analysis
Jul 18, 2017
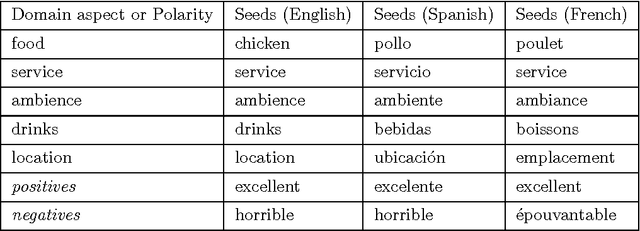
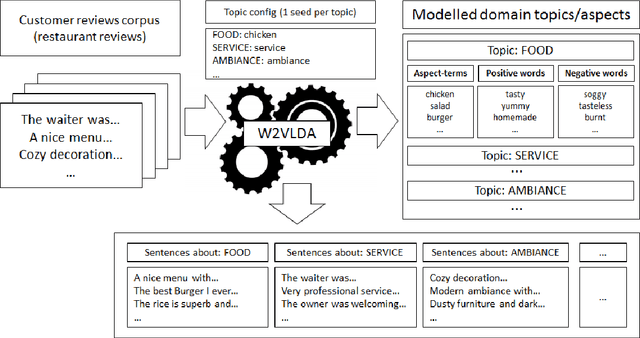
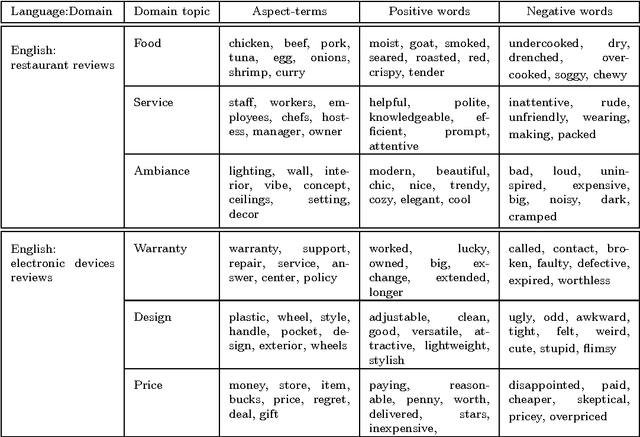
With the increase of online customer opinions in specialised websites and social networks, the necessity of automatic systems to help to organise and classify customer reviews by domain-specific aspect/categories and sentiment polarity is more important than ever. Supervised approaches to Aspect Based Sentiment Analysis obtain good results for the domain/language their are trained on, but having manually labelled data for training supervised systems for all domains and languages are usually very costly and time consuming. In this work we describe W2VLDA, an almost unsupervised system based on topic modelling, that combined with some other unsupervised methods and a minimal configuration, performs aspect/category classifiation, aspect-terms/opinion-words separation and sentiment polarity classification for any given domain and language. We evaluate the performance of the aspect and sentiment classification in the multilingual SemEval 2016 task 5 (ABSA) dataset. We show competitive results for several languages (English, Spanish, French and Dutch) and domains (hotels, restaurants, electronic-devices).