 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsely Factored Neural Machine Translation
Feb 17, 2021

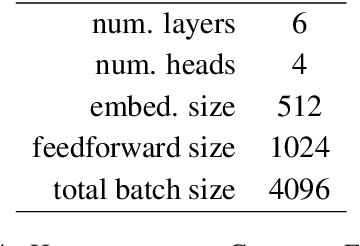

The standard approach to incorporate linguistic information to neural machine translation systems consists in maintaining separate vocabularies for each of the annotated features to be incorporated (e.g. POS tags, dependency relation label), embed them, and then aggregate them with each subword in the word they belong to. This approach, however, cannot easily accommodate annotation schemes that are not dense for every word. We propose a method suited for such a case, showing large improvements in out-of-domain data, and comparable quality for the in-domain data. Experiments are performed in morphologically-rich languages like Basque and German, for the case of low-resource scenarios.
Aspects of Terminological and Named Entity Knowledge within Rule-Based Machine Translation Models for Under-Resourced Neural Machine Translation Scenarios
Sep 28, 2020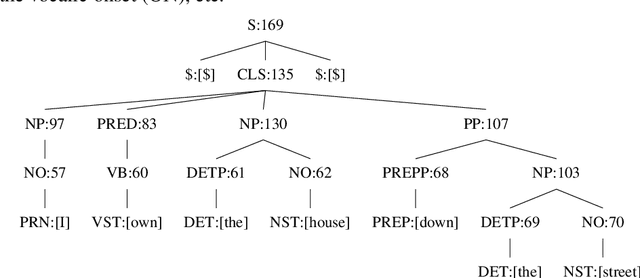
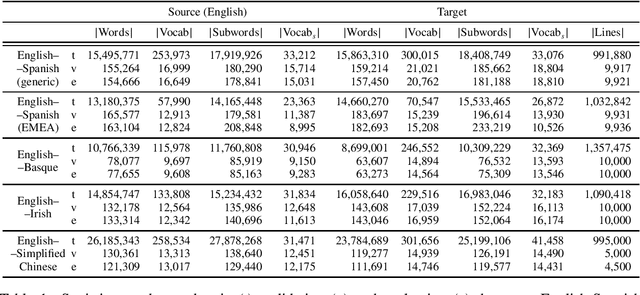
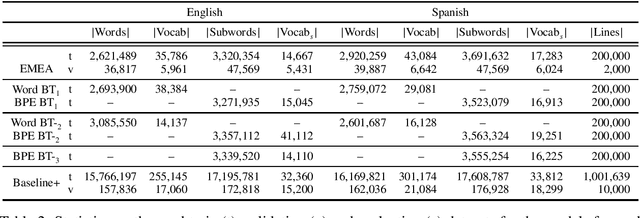

Rule-based machine translation is a machine translation paradigm where linguistic knowledge is encoded by an expert in the form of rules that translate text from source to target language. While this approach grants extensive control over the output of the system, the cost of formalising the needed linguistic knowledge is much higher than training a corpus-based system, where a machine learning approach is used to automatically learn to translate from examples. In this paper, we describe different approaches to leverage the information contained in rule-based machine translation systems to improve a corpus-based one, namely, a neural machine translation model, with a focus on a low-resource scenario. Three different kinds of information were used: morphological information, named entities and terminology. In addition to evaluating the general performance of the system, we systematically analysed the performance of the proposed approaches when dealing with the targeted phenomena. Our results suggest that the proposed models have limited ability to learn from external information, and most approaches do not significantly alter the results of the automatic evaluation, but our preliminary qualitative evaluation shows that in certain cases the hypothesis generated by our system exhibit favourable behaviour such as keeping the use of passive voice.
Syntax-driven Iterative Expansion Language Models for Controllable Text Generation
Apr 05, 2020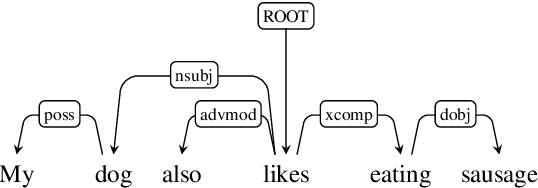
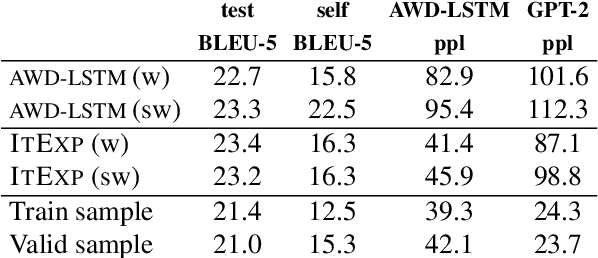
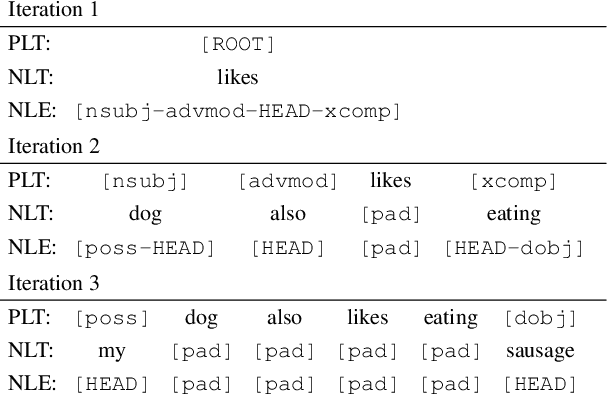
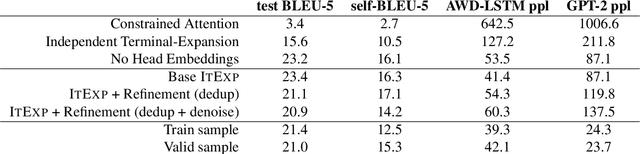
The dominant language modeling paradigms handle text as a sequence of discrete tokens. While these approaches can capture the latent structure of the text, they are inherently constrained to sequential dynamics for text generation. We propose a new paradigm for introducing a syntactic inductive bias into neural language modeling and text generation, where the dependency parse tree is used to drive the Transformer model to generate sentences iteratively, starting from a root placeholder and generating the tokens of the different dependency tree branches in parallel, using either word or subword vocabularies. Our experiments show that this paradigm is effective for text generation, with quality and diversity comparable or superior to those of sequential baselines, and how its inherently controllable generation process enables control over the output syntactic constructions, allowing the induction of stylistic variations.
Do all Roads Lead to Rome? Understanding the Role of Initialization in Iterative Back-Translation
Feb 28, 2020
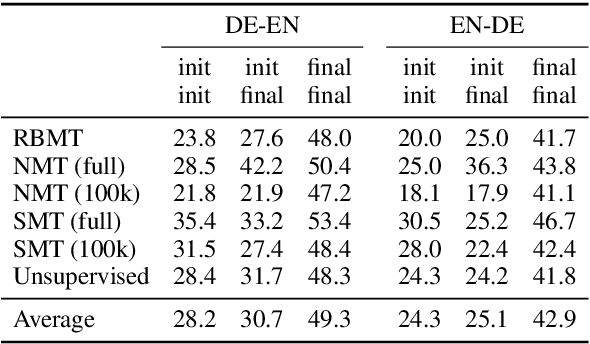
Back-translation provides a simple yet effective approach to exploit monolingual corpora in Neural Machine Translation (NMT). Its iterative variant, where two opposite NMT models are jointly trained by alternately using a synthetic parallel corpus generated by the reverse model, plays a central role in unsupervised machine translation. In order to start producing sound translations and provide a meaningful training signal to each other, existing approaches rely on either a separate machine translation system to warm up the iterative procedure, or some form of pre-training to initialize the weights of the model. In this paper, we analyze the role that such initialization plays in iterative back-translation. Is the behavior of the final system heavily dependent on it? Or does iterative back-translation converge to a similar solution given any reasonable initialization? Through a series of empirical experiments over a diverse set of warmup systems, we show that, although the quality of the initial system does affect final performance, its effect is relatively small, as iterative back-translation has a strong tendency to convergence to a similar solution. As such, the margin of improvement left for the initialization method is narrow, suggesting that future research should focus more on improving the iterative mechanism itself.
Joint Source-Target Self Attention with Locality Constraints
May 16, 2019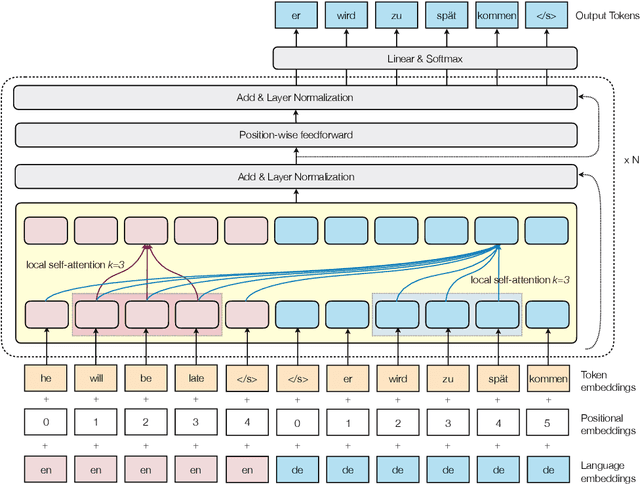
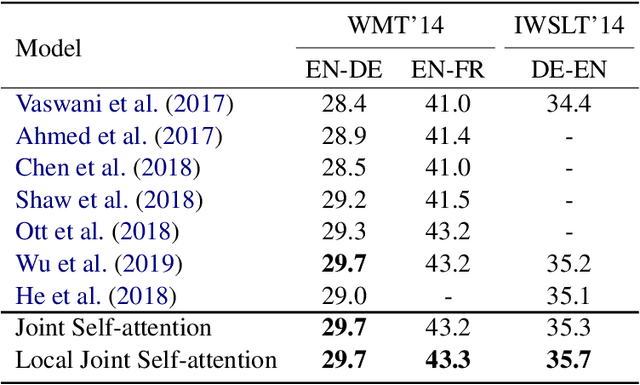
The dominant neural machine translation models are based on the encoder-decoder structure, and many of them rely on an unconstrained receptive field over source and target sequences. In this paper we study a new architecture that breaks with both conventions. Our simplified architecture consists in the decoder part of a transformer model, based on self-attention, but with locality constraints applied on the attention receptive field. As input for training, both source and target sentences are fed to the network, which is trained as a language model. At inference time, the target tokens are predicted autoregressively starting with the source sequence as previous tokens. The proposed model achieves a new state of the art of 35.7 BLEU on IWSLT'14 German-English and matches the best reported results in the literature on the WMT'14 English-German and WMT'14 English-French translation benchmarks.
Evaluating the Underlying Gender Bias in Contextualized Word Embeddings
Apr 18, 2019

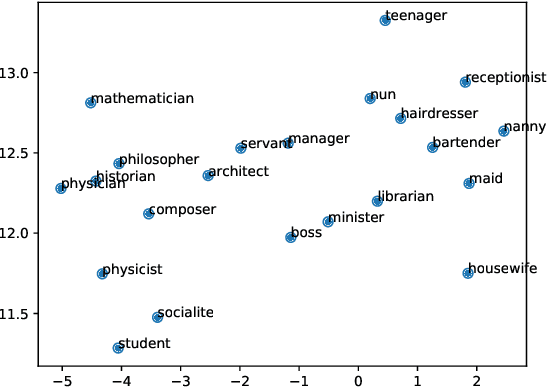
Gender bias is highly impacting natural language processing applications. Word embeddings have clearly been proven both to keep and amplify gender biases that are present in current data sources. Recently, contextualized word embeddings have enhanced previous word embedding techniques by computing word vector representations dependent on the sentence they appear in. In this paper, we study the impact of this conceptual change in the word embedding computation in relation with gender bias. Our analysis includes different measures previously applied in the literature to standard word embeddings. Our findings suggest that contextualized word embeddings are less biased than standard ones even when the latter are debiased.
English-Catalan Neural Machine Translation in the Biomedical Domain through the cascade approach
Apr 26, 2018

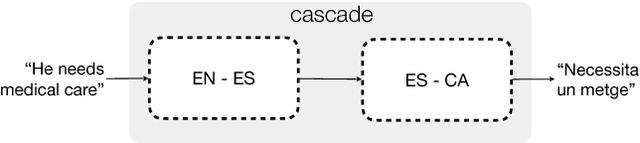
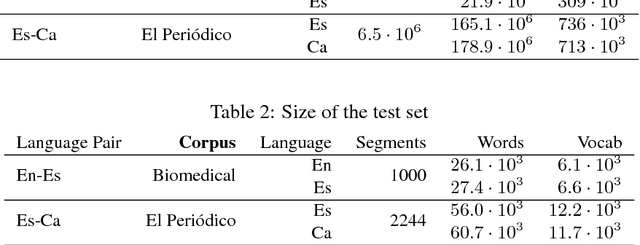
This paper describes the methodology followed to build a neural machine translation system in the biomedical domain for the English-Catalan language pair. This task can be considered a low-resourced task from the point of view of the domain and the language pair. To face this task, this paper reports experiments on a cascade pivot strategy through Spanish for the neural machine translation using the English-Spanish SCIELO and Spanish-Catalan El Peri\'odico database. To test the final performance of the system, we have created a new test data set for English-Catalan in the biomedical domain which is freely available on request.
* Full workshop proceedings can be found at https://multilingualbio.bsc.es/wp-content/uploads/2018/03/LREC-2018-PROCEEDINGS-MultilingualBIO.pdf
Deep Deterministic Policy Gradient for Urban Traffic Light Control
Aug 02, 2017



Traffic light timing optimization is still an active line of research despite the wealth of scientific literature on the topic, and the problem remains unsolved for any non-toy scenario. One of the key issues with traffic light optimization is the large scale of the input information that is available for the controlling agent, namely all the traffic data that is continually sampled by the traffic detectors that cover the urban network. This issue has in the past forced researchers to focus on agents that work on localized parts of the traffic network, typically on individual intersections, and to coordinate every individual agent in a multi-agent setup. In order to overcome the large scale of the available state information, we propose to rely on the ability of deep Learning approaches to handle large input spaces, in the form of Deep Deterministic Policy Gradient (DDPG) algorithm. We performed several experiments with a range of models, from the very simple one (one intersection) to the more complex one (a big city section).
A review of landmark articles in the field of co-evolutionary computing
Jun 29, 2015
Coevolution is a powerful tool in evolutionary computing that mitigates some of its endemic problems, namely stagnation in local optima and lack of convergence in high dimensionality problems. Since its inception in 1990, there are multiple articles that have contributed greatly to the development and improvement of the coevolutionary techniques. In this report we review some of those landmark articles dwelving in the techniques they propose and how they fit to conform robust evolutionary algorithms
Genetic Algorithms for multimodal optimization: a review
Jun 10, 2015In this article we provide a comprehensive review of the different evolutionary algorithm techniques used to address multimodal optimization problems, classifying them according to the nature of their approach. On the one hand there are algorithms that address the issue of the early convergence to a local optimum by differentiating the individuals of the population into groups and limiting their interaction, hence having each group evolve with a high degree of independence. On the other hand other approaches are based on directly addressing the lack of genetic diversity of the population by introducing elements into the evolutionary dynamics that promote new niches of the genotypical space to be explored. Finally, we study multi-objective optimization genetic algorithms, that handle the situations where multiple criteria have to be satisfied with no penalty for any of them. Very rich literature has arised over the years on these topics, and we aim at offering an overview of the most important techniques of each branch of the field.