Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsely Factored Neural Machine Translation
Feb 17, 2021

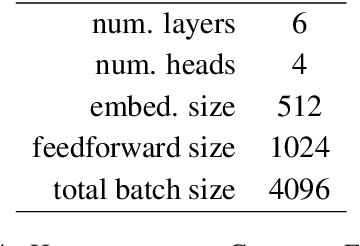

The standard approach to incorporate linguistic information to neural machine translation systems consists in maintaining separate vocabularies for each of the annotated features to be incorporated (e.g. POS tags, dependency relation label), embed them, and then aggregate them with each subword in the word they belong to. This approach, however, cannot easily accommodate annotation schemes that are not dense for every word. We propose a method suited for such a case, showing large improvements in out-of-domain data, and comparable quality for the in-domain data. Experiments are performed in morphologically-rich languages like Basque and German, for the case of low-resource scenarios.
Via