 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Gender Debiased Word Embeddings in Language Modeling
May 05, 2021



Gender, race and social biases have recently been detected as evident examples of unfairness in applications of Natural Language Processing. A key path towards fairness is to understand, analyse and interpret our data and algorithms. Recent studies have shown that the human-generated data used in training is an apparent factor of getting biases. In addition, current algorithms have also been proven to amplify biases from data. To further address these concerns, in this paper, we study how an state-of-the-art recurrent neural language model behaves when trained on data, which under-represents females, using pre-trained standard and debiased word embeddings. Results show that language models inherit higher bias when trained on unbalanced data when using pre-trained embeddings, in comparison with using embeddings trained within the task. Moreover, results show that, on the same data, language models inherit lower bias when using debiased pre-trained emdeddings, compared to using standard pre-trained embeddings.
Gender Bias in Multilingual Neural Machine Translation: The Architecture Matters
Dec 24, 2020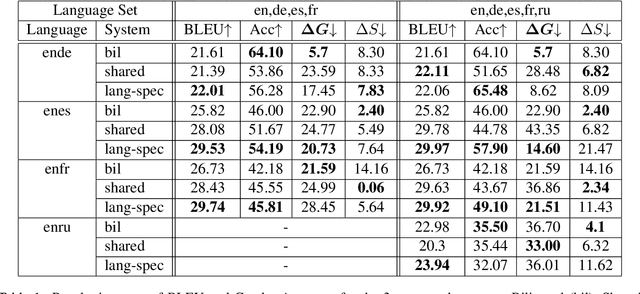

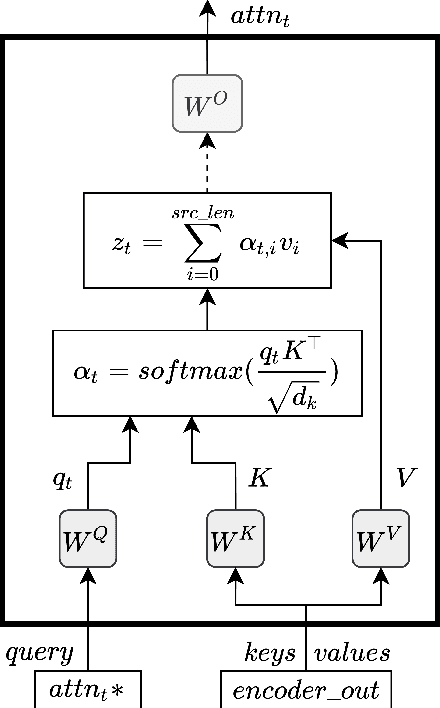
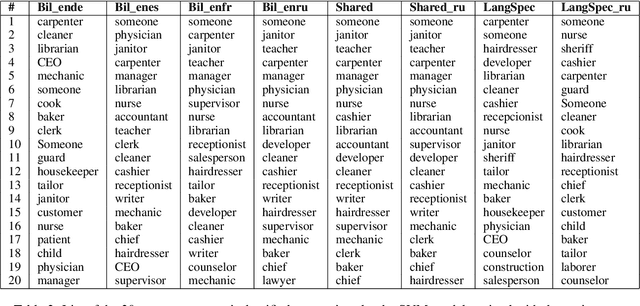
Multilingual Neural Machine Translation architectures mainly differ in the amount of sharing modules and parameters among languages. In this paper, and from an algorithmic perspective, we explore if the chosen architecture, when trained with the same data, influences the gender bias accuracy. Experiments in four language pairs show that Language-Specific encoders-decoders exhibit less bias than the Shared encoder-decoder architecture. Further interpretability analysis of source embeddings and the attention shows that, in the Language-Specific case, the embeddings encode more gender information, and its attention is more diverted. Both behaviors help in mitigating gender bias.
Evaluating Gender Bias in Speech Translation
Oct 29, 2020

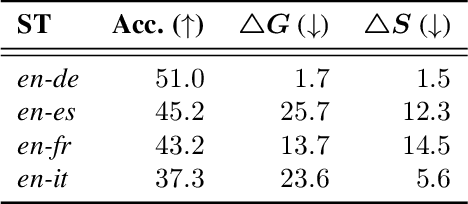
The scientific community is more and more aware of the necessity to embrace pluralism and consistently represent major and minor social groups. In this direction, there is an urgent need to provide evaluation sets and protocols to measure existing biases in our automatic systems. This paper introduces WinoST, a new freely available challenge set for evaluating gender bias in speech translation. WinoST is the speech version of WinoMT which is an MT challenge set and both follow an evaluation protocol to measure gender accuracy. Using a state-of-the-art end-to-end speech translation system, we report the gender bias evaluation on 4 language pairs, and we show that gender accuracy in speech translation is more than 23% lower than in MT.
Evaluating the Underlying Gender Bias in Contextualized Word Embeddings
Apr 18, 2019

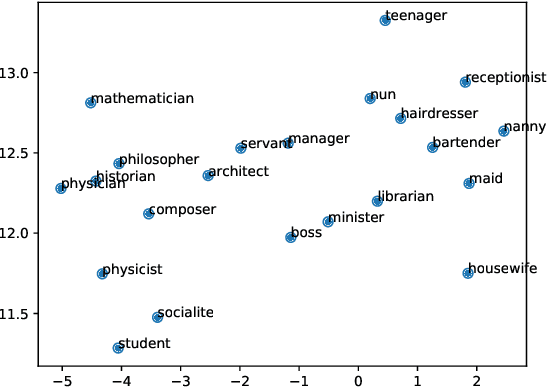
Gender bias is highly impacting natural language processing applications. Word embeddings have clearly been proven both to keep and amplify gender biases that are present in current data sources. Recently, contextualized word embeddings have enhanced previous word embedding techniques by computing word vector representations dependent on the sentence they appear in. In this paper, we study the impact of this conceptual change in the word embedding computation in relation with gender bias. Our analysis includes different measures previously applied in the literature to standard word embeddings. Our findings suggest that contextualized word embeddings are less biased than standard ones even when the latter are debiased.