Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Bias in Multilingual Neural Machine Translation: The Architecture Matters
Dec 24, 2020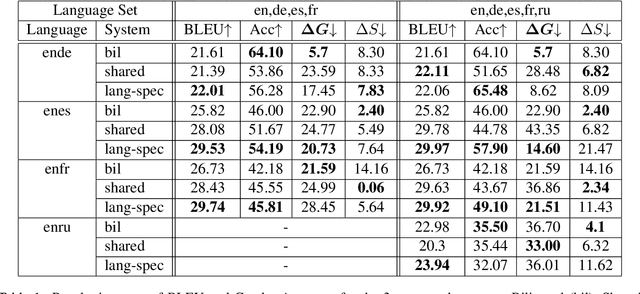

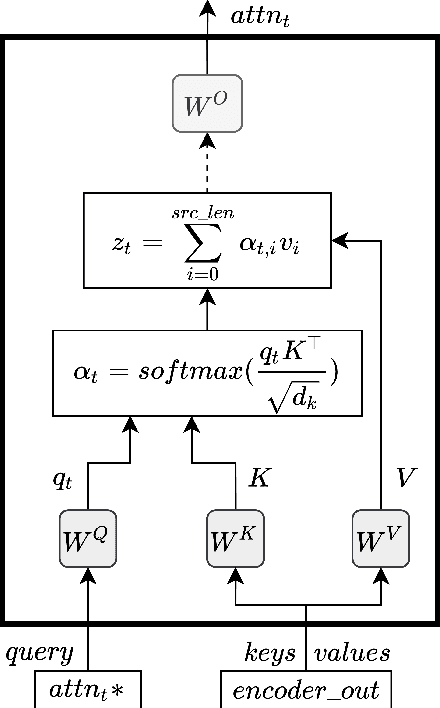
Multilingual Neural Machine Translation architectures mainly differ in the amount of sharing modules and parameters among languages. In this paper, and from an algorithmic perspective, we explore if the chosen architecture, when trained with the same data, influences the gender bias accuracy. Experiments in four language pairs show that Language-Specific encoders-decoders exhibit less bias than the Shared encoder-decoder architecture. Further interpretability analysis of source embeddings and the attention shows that, in the Language-Specific case, the embeddings encode more gender information, and its attention is more diverted. Both behaviors help in mitigating gender bias.
* 12 pages, 5 figures, 3 tables
Via