 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLMs for Anxiety, Depression, and Stress Detection Evaluating Large Language Models for Anxiety, Depression, and Stress Detection: Insights into Prompting Strategies and Synthetic Data
Nov 10, 2025Mental health disorders affect over one-fifth of adults globally, yet detecting such conditions from text remains challenging due to the subtle and varied nature of symptom expression. This study evaluates multiple approaches for mental health detection, comparing Large Language Models (LLMs) such as Llama and GPT with classical machine learning and transformer-based architectures including BERT, XLNet, and Distil-RoBERTa. Using the DAIC-WOZ dataset of clinical interviews, we fine-tuned models for anxiety, depression, and stress classification and applied synthetic data generation to mitigate class imbalance. Results show that Distil-RoBERTa achieved the highest F1 score (0.883) for GAD-2, while XLNet outperformed others on PHQ tasks (F1 up to 0.891). For stress detection, a zero-shot synthetic approach (SD+Zero-Shot-Basic) reached an F1 of 0.884 and ROC AUC of 0.886. Findings demonstrate the effectiveness of transformer-based models and highlight the value of synthetic data in improving recall and generalization. However, careful calibration is required to prevent precision loss. Overall, this work emphasizes the potential of combining advanced language models and data augmentation to enhance automated mental health assessment from text.
Towards Sustainable Workplace Mental Health: A Novel Approach to Early Intervention and Support
Feb 02, 2024Employee well-being is a critical concern in the contemporary workplace, as highlighted by the American Psychological Association's 2021 report, indicating that 71% of employees experience stress or tension. This stress contributes significantly to workplace attrition and absenteeism, with 61% of attrition and 16% of sick days attributed to poor mental health. A major challenge for employers is that employees often remain unaware of their mental health issues until they reach a crisis point, resulting in limited utilization of corporate well-being benefits. This research addresses this challenge by presenting a groundbreaking stress detection algorithm that provides real-time support preemptively. Leveraging automated chatbot technology, the algorithm objectively measures mental health levels by analyzing chat conversations, offering personalized treatment suggestions in real-time based on linguistic biomarkers. The study explores the feasibility of integrating these innovations into practical learning applications within real-world contexts and introduces a chatbot-style system integrated into the broader employee experience platform. This platform, encompassing various features, aims to enhance overall employee well-being, detect stress in real time, and proactively engage with individuals to improve support effectiveness, demonstrating a 22% increase when assistance is provided early. Overall, the study emphasizes the importance of fostering a supportive workplace environment for employees' mental health.
An Assessment on Comprehending Mental Health through Large Language Models
Jan 09, 2024Mental health challenges pose considerable global burdens on individuals and communities. Recent data indicates that more than 20% of adults may encounter at least one mental disorder in their lifetime. On the one hand, the advancements in large language models have facilitated diverse applications, yet a significant research gap persists in understanding and enhancing the potential of large language models within the domain of mental health. On the other hand, across various applications, an outstanding question involves the capacity of large language models to comprehend expressions of human mental health conditions in natural language. This study presents an initial evaluation of large language models in addressing this gap. Due to this, we compare the performance of Llama-2 and ChatGPT with classical Machine as well as Deep learning models. Our results on the DAIC-WOZ dataset show that transformer-based models, like BERT or XLNet, outperform the large language models.
TrollsWithOpinion: A Dataset for Predicting Domain-specific Opinion Manipulation in Troll Memes
Sep 08, 2021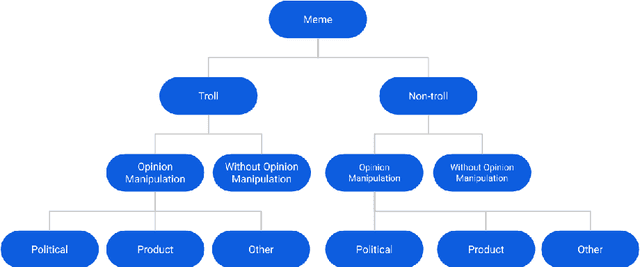

Research into the classification of Image with Text (IWT) troll memes has recently become popular. Since the online community utilizes the refuge of memes to express themselves, there is an abundance of data in the form of memes. These memes have the potential to demean, harras, or bully targeted individuals. Moreover, the targeted individual could fall prey to opinion manipulation. To comprehend the use of memes in opinion manipulation, we define three specific domains (product, political or others) which we classify into troll or not-troll, with or without opinion manipulation. To enable this analysis, we enhanced an existing dataset by annotating the data with our defined classes, resulting in a dataset of 8,881 IWT or multimodal memes in the English language (TrollsWithOpinion dataset). We perform baseline experiments on the annotated dataset, and our result shows that existing state-of-the-art techniques could only reach a weighted-average F1-score of 0.37. This shows the need for a development of a specific technique to deal with multimodal troll memes.
Aspects of Terminological and Named Entity Knowledge within Rule-Based Machine Translation Models for Under-Resourced Neural Machine Translation Scenarios
Sep 28, 2020
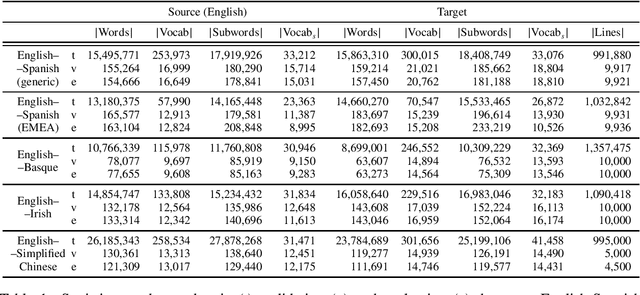
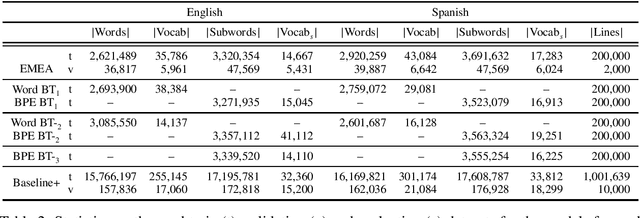

Rule-based machine translation is a machine translation paradigm where linguistic knowledge is encoded by an expert in the form of rules that translate text from source to target language. While this approach grants extensive control over the output of the system, the cost of formalising the needed linguistic knowledge is much higher than training a corpus-based system, where a machine learning approach is used to automatically learn to translate from examples. In this paper, we describe different approaches to leverage the information contained in rule-based machine translation systems to improve a corpus-based one, namely, a neural machine translation model, with a focus on a low-resource scenario. Three different kinds of information were used: morphological information, named entities and terminology. In addition to evaluating the general performance of the system, we systematically analysed the performance of the proposed approaches when dealing with the targeted phenomena. Our results suggest that the proposed models have limited ability to learn from external information, and most approaches do not significantly alter the results of the automatic evaluation, but our preliminary qualitative evaluation shows that in certain cases the hypothesis generated by our system exhibit favourable behaviour such as keeping the use of passive voice.
A Survey of Orthographic Information in Machine Translation
Aug 04, 2020Machine translation is one of the applications of natural language processing which has been explored in different languages. Recently researchers started paying attention towards machine translation for resource-poor languages and closely related languages. A widespread and underlying problem for these machine translation systems is the variation in orthographic conventions which causes many issues to traditional approaches. Two languages written in two different orthographies are not easily comparable, but orthographic information can also be used to improve the machine translation system. This article offers a survey of research regarding orthography's influence on machine translation of under-resourced languages. It introduces under-resourced languages in terms of machine translation and how orthographic information can be utilised to improve machine translation. We describe previous work in this area, discussing what underlying assumptions were made, and showing how orthographic knowledge improves the performance of machine translation of under-resourced languages. We discuss different types of machine translation and demonstrate a recent trend that seeks to link orthographic information with well-established machine translation methods. Considerable attention is given to current efforts of cognates information at different levels of machine translation and the lessons that can be drawn from this. Additionally, multilingual neural machine translation of closely related languages is given a particular focus in this survey. This article ends with a discussion of the way forward in machine translation with orthographic information, focusing on multilingual settings and bilingual lexicon induction.
Polylingual Wordnet
Mar 04, 2019
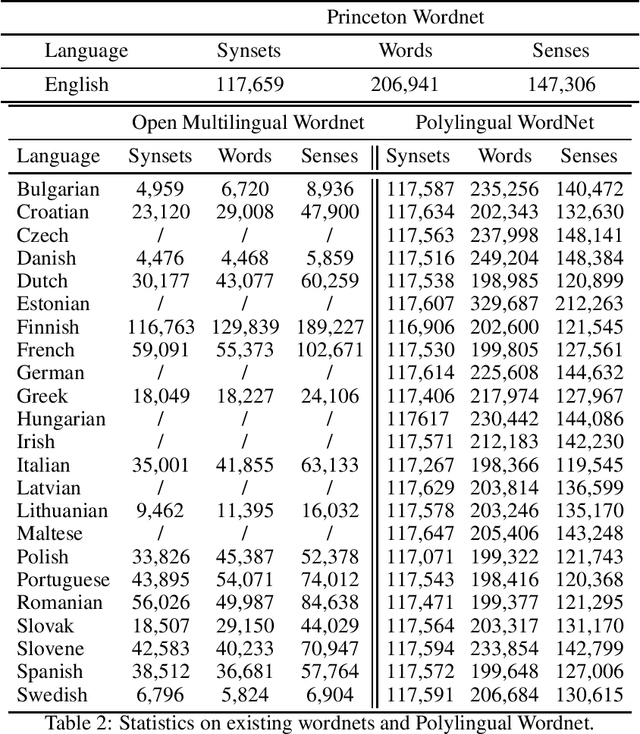
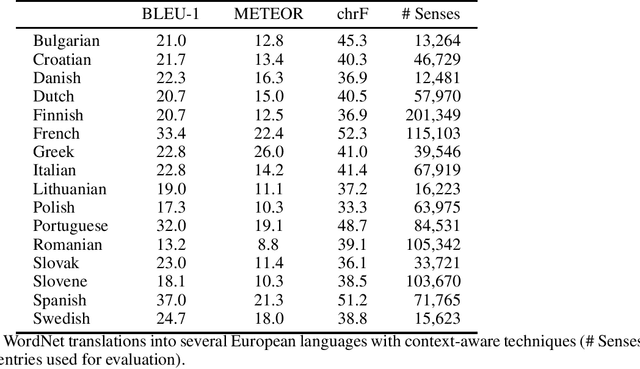
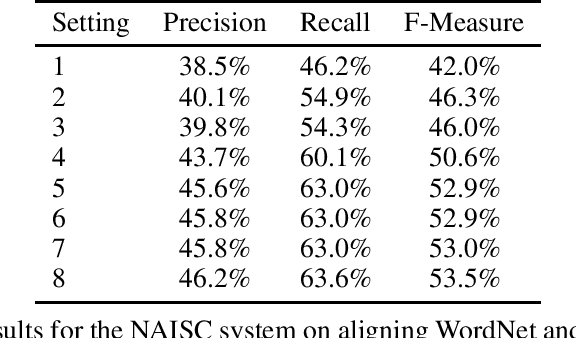
Princeton WordNet is one of the most important resources for natural language processing, but is only available for English. While it has been translated using the expand approach to many other languages, this is an expensive manual process. Therefore it would be beneficial to have a high-quality automatic translation approach that would support NLP techniques, which rely on WordNet in new languages. The translation of wordnets is fundamentally complex because of the need to translate all senses of a word including low frequency senses, which is very challenging for current machine translation approaches. For this reason we leverage existing translations of WordNet in other languages to identify contextual information for wordnet senses from a large set of generic parallel corpora. We evaluate our approach using 10 translated wordnets for European languages. Our experiment shows a significant improvement over translation without any contextual information. Furthermore, we evaluate how the choice of pivot languages affects performance of multilingual word sense disambiguation.
Translating Questions into Answers using DBPedia n-triples
Mar 07, 2018
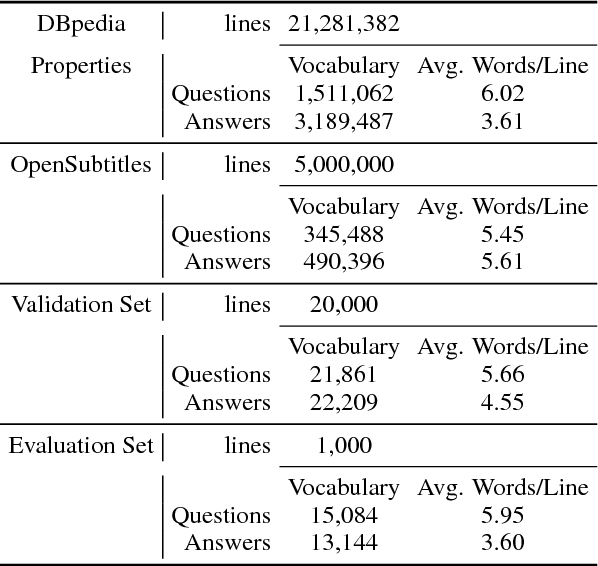


In this paper we present a question answering system using a neural network to interpret questions learned from the DBpedia repository. We train a sequence-to-sequence neural network model with n-triples extracted from the DBpedia Infobox Properties. Since these properties do not represent the natural language, we further used question-answer dialogues from movie subtitles. Although the automatic evaluation shows a low overlap of the generated answers compared to the gold standard set, a manual inspection of the showed promising outcomes from the experiment for further work.
Translating Domain-Specific Expressions in Knowledge Bases with Neural Machine Translation
Sep 07, 2017



Our work presented in this paper focuses on the translation of domain-specific expressions represented in semantically structured resources, like ontologies or knowledge graphs. To make knowledge accessible beyond language borders, these resources need to be translated into different languages. The challenge of translating labels or terminological expressions represented in ontologies lies in the highly specific vocabulary and the lack of contextual information, which can guide a machine translation system to translate ambiguous words into the targeted domain. Due to the challenges, we train and translate the terminological expressions in the medial and financial domain with statistical as well as with neural machine translation methods. We evaluate the translation quality of domain-specific expressions with translation systems trained on a generic dataset and experiment domain adaptation with terminological expressions. Furthermore we perform experiments on the injection of external knowledge into the translation systems. Through these experiments, we observed a clear advantage in domain adaptation and terminology injection of NMT methods over SMT. Nevertheless, through the specific and unique terminological expressions, subword segmentation within NMT does not outperform a word based neural translation model.