Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpanish Language Models
Aug 13, 2021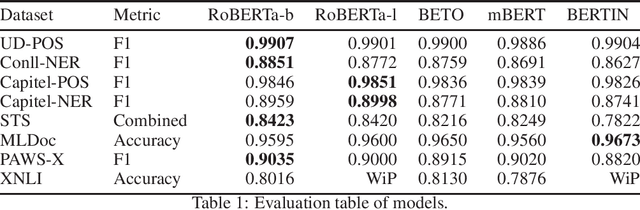
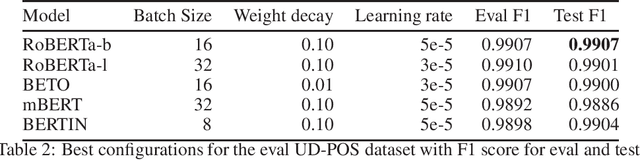
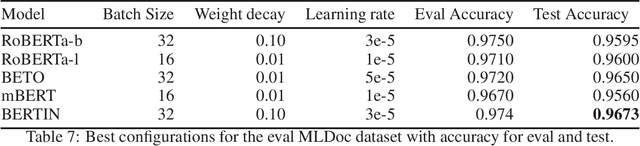
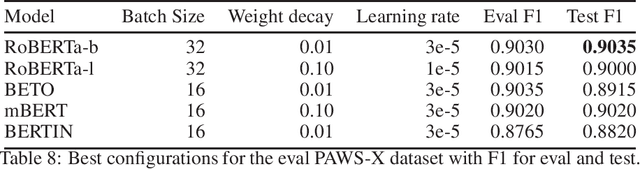
This paper presents the Spanish RoBERTa-base and RoBERTa-large models, as well as the corresponding performance evaluations. Both models were pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the National Library of Spain from 2009 to 2019. We extended the current evaluation datasets with an extractive Question Answering dataset and our models outperform the existing Spanish models across tasks and settings.
Via