 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the TalentCLEF 2025: Skill and Job Title Intelligence for Human Capital Management
Jul 17, 2025Advances in natural language processing and large language models are driving a major transformation in Human Capital Management, with a growing interest in building smart systems based on language technologies for talent acquisition, upskilling strategies, and workforce planning. However, the adoption and progress of these technologies critically depend on the development of reliable and fair models, properly evaluated on public data and open benchmarks, which have so far been unavailable in this domain. To address this gap, we present TalentCLEF 2025, the first evaluation campaign focused on skill and job title intelligence. The lab consists of two tasks: Task A - Multilingual Job Title Matching, covering English, Spanish, German, and Chinese; and Task B - Job Title-Based Skill Prediction, in English. Both corpora were built from real job applications, carefully anonymized, and manually annotated to reflect the complexity and diversity of real-world labor market data, including linguistic variability and gender-marked expressions. The evaluations included monolingual and cross-lingual scenarios and covered the evaluation of gender bias. TalentCLEF attracted 76 registered teams with more than 280 submissions. Most systems relied on information retrieval techniques built with multilingual encoder-based models fine-tuned with contrastive learning, and several of them incorporated large language models for data augmentation or re-ranking. The results show that the training strategies have a larger effect than the size of the model alone. TalentCLEF provides the first public benchmark in this field and encourages the development of robust, fair, and transferable language technologies for the labor market.
MELO: An Evaluation Benchmark for Multilingual Entity Linking of Occupations
Oct 10, 2024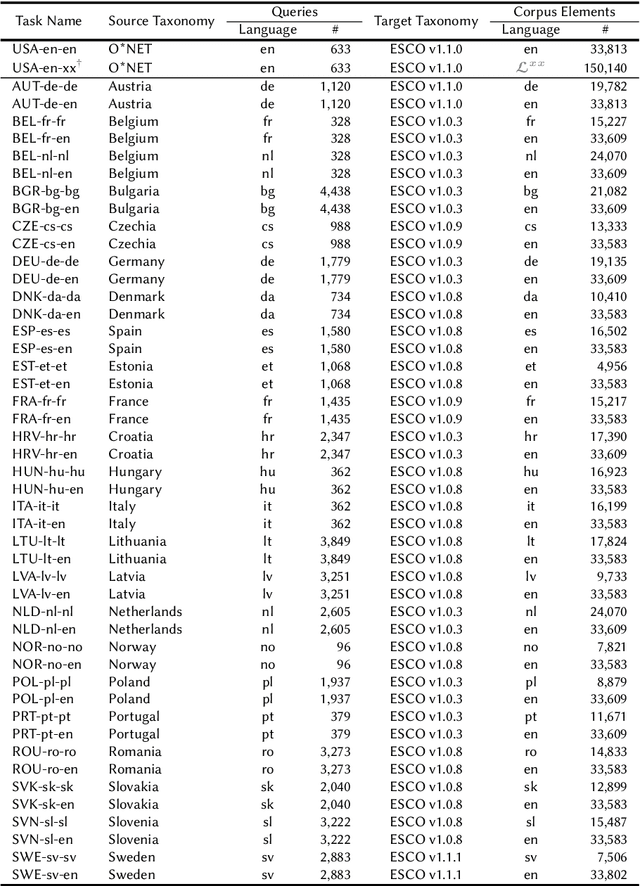
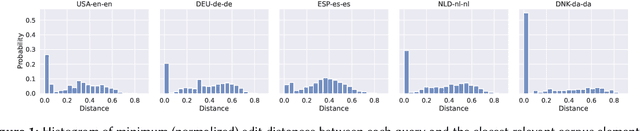
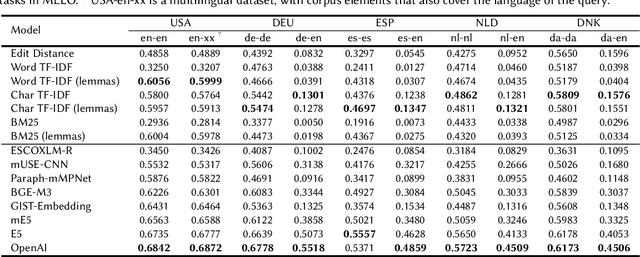
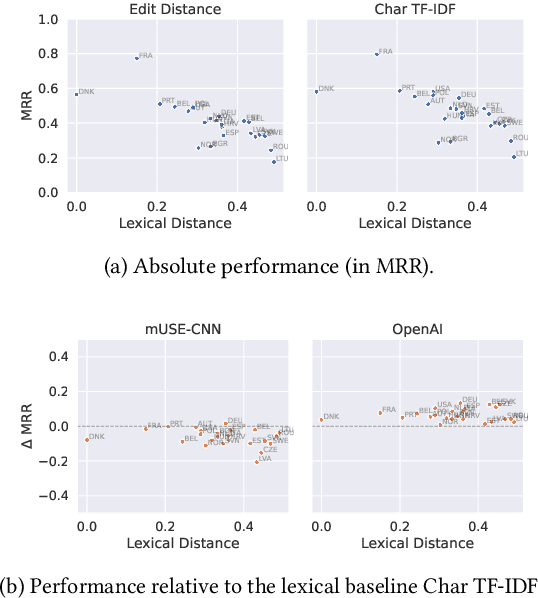
We present the Multilingual Entity Linking of Occupations (MELO) Benchmark, a new collection of 48 datasets for evaluating the linking of entity mentions in 21 languages to the ESCO Occupations multilingual taxonomy. MELO was built using high-quality, pre-existent human annotations. We conduct experiments with simple lexical models and general-purpose sentence encoders, evaluated as bi-encoders in a zero-shot setup, to establish baselines for future research. The datasets and source code for standardized evaluation are publicly available at https://github.com/Avature/melo-benchmark
Overview of BioASQ 2023: The eleventh BioASQ challenge on Large-Scale Biomedical Semantic Indexing and Question Answering
Jul 11, 2023This is an overview of the eleventh edition of the BioASQ challenge in the context of the Conference and Labs of the Evaluation Forum (CLEF) 2023. BioASQ is a series of international challenges promoting advances in large-scale biomedical semantic indexing and question answering. This year, BioASQ consisted of new editions of the two established tasks b and Synergy, and a new task (MedProcNER) on semantic annotation of clinical content in Spanish with medical procedures, which have a critical role in medical practice. In this edition of BioASQ, 28 competing teams submitted the results of more than 150 distinct systems in total for the three different shared tasks of the challenge. Similarly to previous editions, most of the participating systems achieved competitive performance, suggesting the continuous advancement of the state-of-the-art in the field.
Overview of BioASQ 2022: The tenth BioASQ challenge on Large-Scale Biomedical Semantic Indexing and Question Answering
Oct 13, 2022This paper presents an overview of the tenth edition of the BioASQ challenge in the context of the Conference and Labs of the Evaluation Forum (CLEF) 2022. BioASQ is an ongoing series of challenges that promotes advances in the domain of large-scale biomedical semantic indexing and question answering. In this edition, the challenge was composed of the three established tasks a, b, and Synergy, and a new task named DisTEMIST for automatic semantic annotation and grounding of diseases from clinical content in Spanish, a key concept for semantic indexing and search engines of literature and clinical records. This year, BioASQ received more than 170 distinct systems from 38 teams in total for the four different tasks of the challenge. As in previous years, the majority of the competing systems outperformed the strong baselines, indicating the continuous advancement of the state-of-the-art in this domain.
* 25 pages, 14 tables, 4 figures. arXiv admin note: substantial text overlap with arXiv:2106.14885
Overview of BioASQ 2021: The ninth BioASQ challenge on Large-Scale Biomedical Semantic Indexing and Question Answering
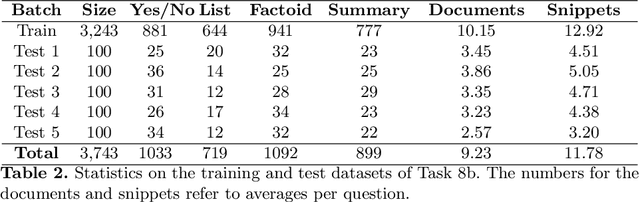
Jun 28, 2021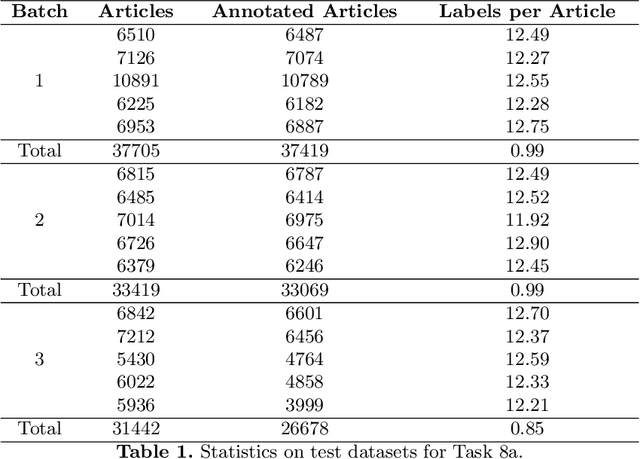

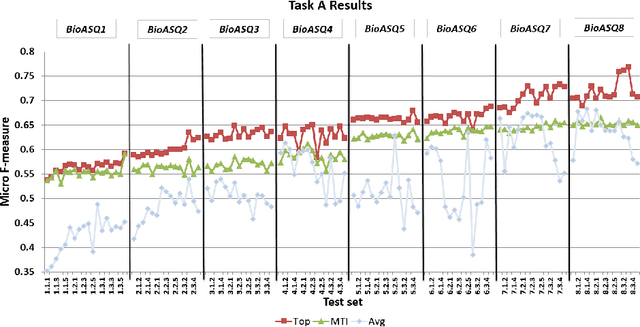
Advancing the state-of-the-art in large-scale biomedical semantic indexing and question answering is the main focus of the BioASQ challenge. BioASQ organizes respective tasks where different teams develop systems that are evaluated on the same benchmark datasets that represent the real information needs of experts in the biomedical domain. This paper presents an overview of the ninth edition of the BioASQ challenge in the context of the Conference and Labs of the Evaluation Forum (CLEF) 2021. In this year, a new question answering task, named Synergy, is introduced to support researchers studying the COVID-19 disease and measure the ability of the participating teams to discern information while the problem is still developing. In total, 42 teams with more than 170 systems were registered to participate in the four tasks of the challenge. The evaluation results, similarly to previous years, show a performance gain against the baselines which indicates the continuous improvement of the state-of-the-art in this field.