 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJobResQA: A Benchmark for LLM Machine Reading Comprehension on Multilingual Résumés and JDs
Jan 30, 2026We introduce JobResQA, a multilingual Question Answering benchmark for evaluating Machine Reading Comprehension (MRC) capabilities of LLMs on HR-specific tasks involving résumés and job descriptions. The dataset comprises 581 QA pairs across 105 synthetic résumé-job description pairs in five languages (English, Spanish, Italian, German, and Chinese), with questions spanning three complexity levels from basic factual extraction to complex cross-document reasoning. We propose a data generation pipeline derived from real-world sources through de-identification and data synthesis to ensure both realism and privacy, while controlled demographic and professional attributes (implemented via placeholders) enable systematic bias and fairness studies. We also present a cost-effective, human-in-the-loop translation pipeline based on the TEaR methodology, incorporating MQM error annotations and selective post-editing to ensure an high-quality multi-way parallel benchmark. We provide a baseline evaluations across multiple open-weight LLM families using an LLM-as-judge approach revealing higher performances on English and Spanish but substantial degradation for other languages, highlighting critical gaps in multilingual MRC capabilities for HR applications. JobResQA provides a reproducible benchmark for advancing fair and reliable LLM-based HR systems. The benchmark is publicly available at: https://github.com/Avature/jobresqa-benchmark
Overview of the TalentCLEF 2025: Skill and Job Title Intelligence for Human Capital Management
Jul 17, 2025Advances in natural language processing and large language models are driving a major transformation in Human Capital Management, with a growing interest in building smart systems based on language technologies for talent acquisition, upskilling strategies, and workforce planning. However, the adoption and progress of these technologies critically depend on the development of reliable and fair models, properly evaluated on public data and open benchmarks, which have so far been unavailable in this domain. To address this gap, we present TalentCLEF 2025, the first evaluation campaign focused on skill and job title intelligence. The lab consists of two tasks: Task A - Multilingual Job Title Matching, covering English, Spanish, German, and Chinese; and Task B - Job Title-Based Skill Prediction, in English. Both corpora were built from real job applications, carefully anonymized, and manually annotated to reflect the complexity and diversity of real-world labor market data, including linguistic variability and gender-marked expressions. The evaluations included monolingual and cross-lingual scenarios and covered the evaluation of gender bias. TalentCLEF attracted 76 registered teams with more than 280 submissions. Most systems relied on information retrieval techniques built with multilingual encoder-based models fine-tuned with contrastive learning, and several of them incorporated large language models for data augmentation or re-ranking. The results show that the training strategies have a larger effect than the size of the model alone. TalentCLEF provides the first public benchmark in this field and encourages the development of robust, fair, and transferable language technologies for the labor market.
MELO: An Evaluation Benchmark for Multilingual Entity Linking of Occupations
Oct 10, 2024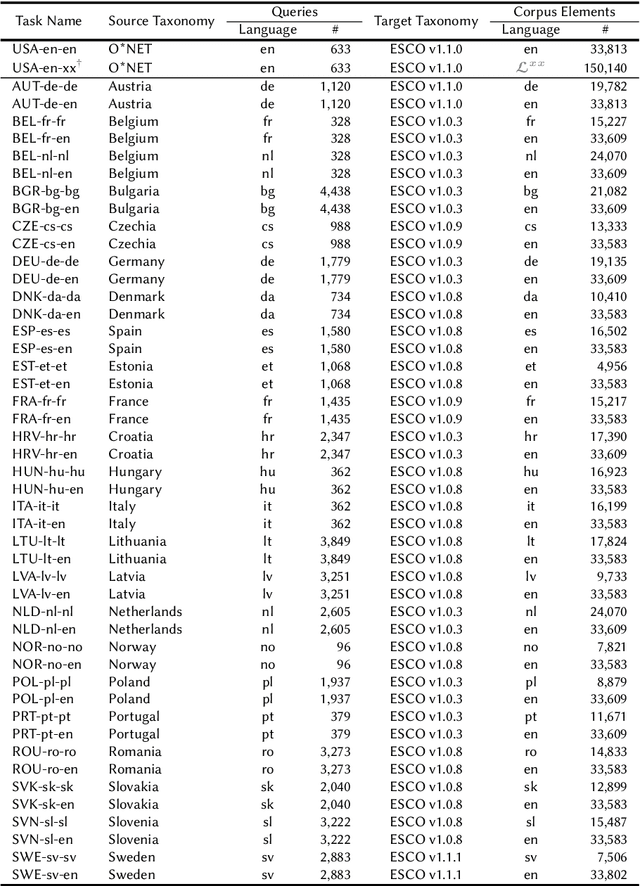
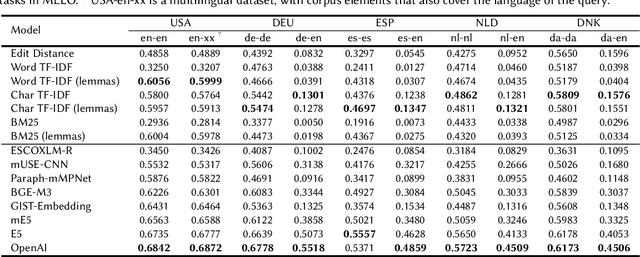
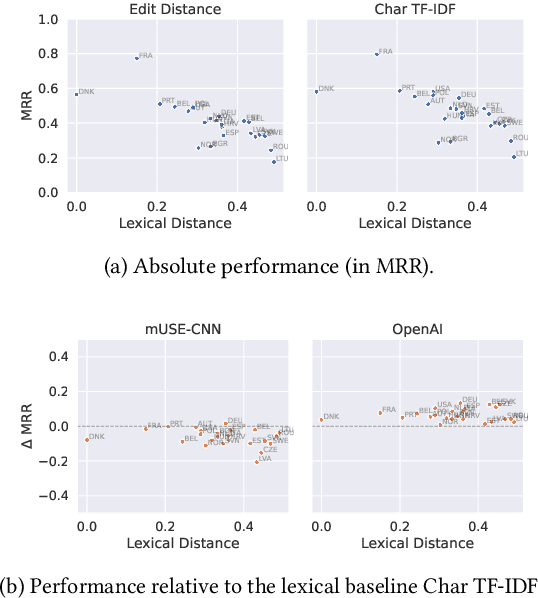
We present the Multilingual Entity Linking of Occupations (MELO) Benchmark, a new collection of 48 datasets for evaluating the linking of entity mentions in 21 languages to the ESCO Occupations multilingual taxonomy. MELO was built using high-quality, pre-existent human annotations. We conduct experiments with simple lexical models and general-purpose sentence encoders, evaluated as bi-encoders in a zero-shot setup, to establish baselines for future research. The datasets and source code for standardized evaluation are publicly available at https://github.com/Avature/melo-benchmark
Résumé Parsing as Hierarchical Sequence Labeling: An Empirical Study
Sep 13, 2023



Extracting information from r\'esum\'es is typically formulated as a two-stage problem, where the document is first segmented into sections and then each section is processed individually to extract the target entities. Instead, we cast the whole problem as sequence labeling in two levels -- lines and tokens -- and study model architectures for solving both tasks simultaneously. We build high-quality r\'esum\'e parsing corpora in English, French, Chinese, Spanish, German, Portuguese, and Swedish. Based on these corpora, we present experimental results that demonstrate the effectiveness of the proposed models for the information extraction task, outperforming approaches introduced in previous work. We conduct an ablation study of the proposed architectures. We also analyze both model performance and resource efficiency, and describe the trade-offs for model deployment in the context of a production environment.
Learning Job Titles Similarity from Noisy Skill Labels
Jul 01, 2022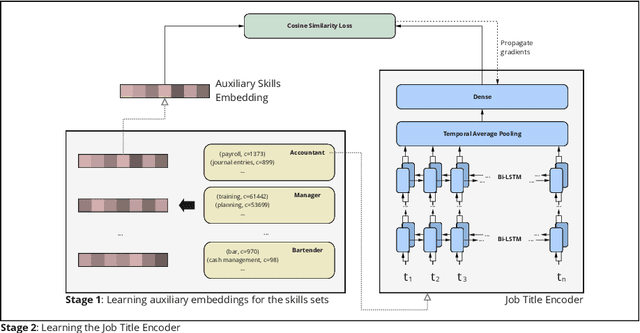
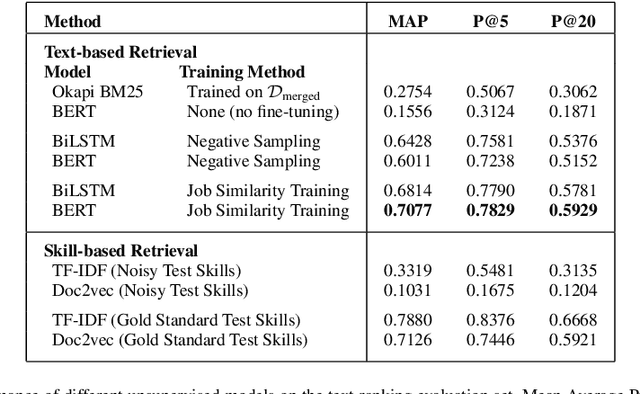
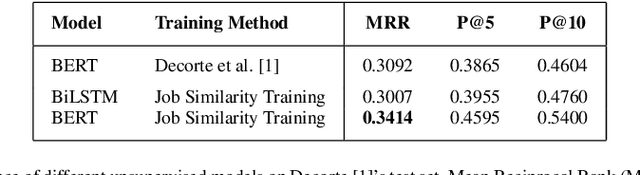
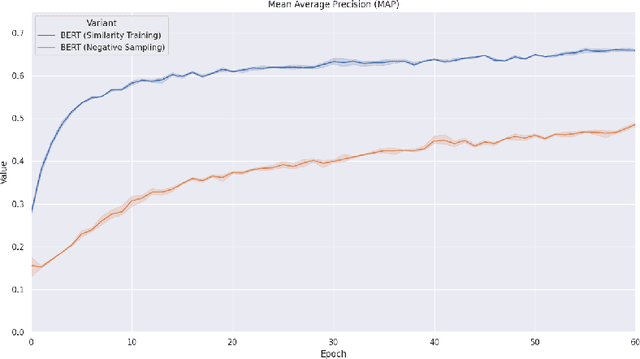
Measuring semantic similarity between job titles is an essential functionality for automatic job recommendations. This task is usually approached using supervised learning techniques, which requires training data in the form of equivalent job title pairs. In this paper, we instead propose an unsupervised representation learning method for training a job title similarity model using noisy skill labels. We show that it is highly effective for tasks such as text ranking and job normalization.
Statistical Machine Translation Features with Multitask Tensor Networks
Jun 01, 2015
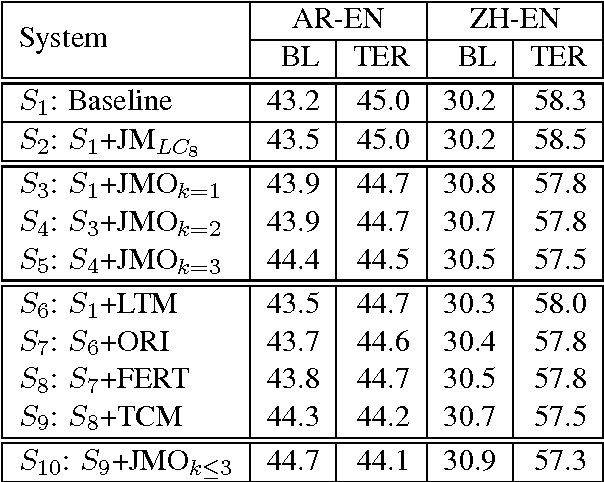
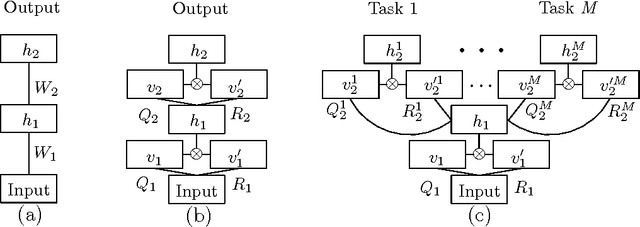
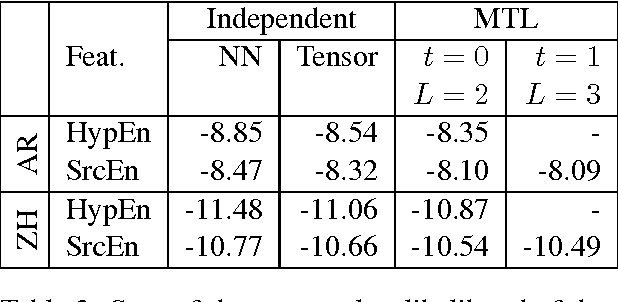
We present a three-pronged approach to improving Statistical Machine Translation (SMT), building on recent success in the application of neural networks to SMT. First, we propose new features based on neural networks to model various non-local translation phenomena. Second, we augment the architecture of the neural network with tensor layers that capture important higher-order interaction among the network units. Third, we apply multitask learning to estimate the neural network parameters jointly. Each of our proposed methods results in significant improvements that are complementary. The overall improvement is +2.7 and +1.8 BLEU points for Arabic-English and Chinese-English translation over a state-of-the-art system that already includes neural network features.