 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of BioASQ 2023: The eleventh BioASQ challenge on Large-Scale Biomedical Semantic Indexing and Question Answering
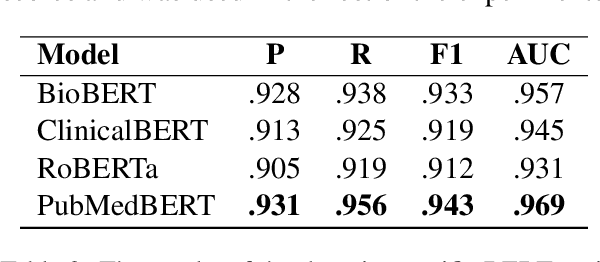
Jul 11, 2023This is an overview of the eleventh edition of the BioASQ challenge in the context of the Conference and Labs of the Evaluation Forum (CLEF) 2023. BioASQ is a series of international challenges promoting advances in large-scale biomedical semantic indexing and question answering. This year, BioASQ consisted of new editions of the two established tasks b and Synergy, and a new task (MedProcNER) on semantic annotation of clinical content in Spanish with medical procedures, which have a critical role in medical practice. In this edition of BioASQ, 28 competing teams submitted the results of more than 150 distinct systems in total for the three different shared tasks of the challenge. Similarly to previous editions, most of the participating systems achieved competitive performance, suggesting the continuous advancement of the state-of-the-art in the field.
Overview of BioASQ 2022: The tenth BioASQ challenge on Large-Scale Biomedical Semantic Indexing and Question Answering
Oct 13, 2022This paper presents an overview of the tenth edition of the BioASQ challenge in the context of the Conference and Labs of the Evaluation Forum (CLEF) 2022. BioASQ is an ongoing series of challenges that promotes advances in the domain of large-scale biomedical semantic indexing and question answering. In this edition, the challenge was composed of the three established tasks a, b, and Synergy, and a new task named DisTEMIST for automatic semantic annotation and grounding of diseases from clinical content in Spanish, a key concept for semantic indexing and search engines of literature and clinical records. This year, BioASQ received more than 170 distinct systems from 38 teams in total for the four different tasks of the challenge. As in previous years, the majority of the competing systems outperformed the strong baselines, indicating the continuous advancement of the state-of-the-art in this domain.
* 25 pages, 14 tables, 4 figures. arXiv admin note: substantial text overlap with arXiv:2106.14885
Predicting Intervention Approval in Clinical Trials through Multi-Document Summarization
Apr 01, 2022


Clinical trials offer a fundamental opportunity to discover new treatments and advance the medical knowledge. However, the uncertainty of the outcome of a trial can lead to unforeseen costs and setbacks. In this study, we propose a new method to predict the effectiveness of an intervention in a clinical trial. Our method relies on generating an informative summary from multiple documents available in the literature about the intervention under study. Specifically, our method first gathers all the abstracts of PubMed articles related to the intervention. Then, an evidence sentence, which conveys information about the effectiveness of the intervention, is extracted automatically from each abstract. Based on the set of evidence sentences extracted from the abstracts, a short summary about the intervention is constructed. Finally, the produced summaries are used to train a BERT-based classifier, in order to infer the effectiveness of an intervention. To evaluate our proposed method, we introduce a new dataset which is a collection of clinical trials together with their associated PubMed articles. Our experiments, demonstrate the effectiveness of producing short informative summaries and using them to predict the effectiveness of an intervention.
Overview of BioASQ 2021: The ninth BioASQ challenge on Large-Scale Biomedical Semantic Indexing and Question Answering
Jun 28, 2021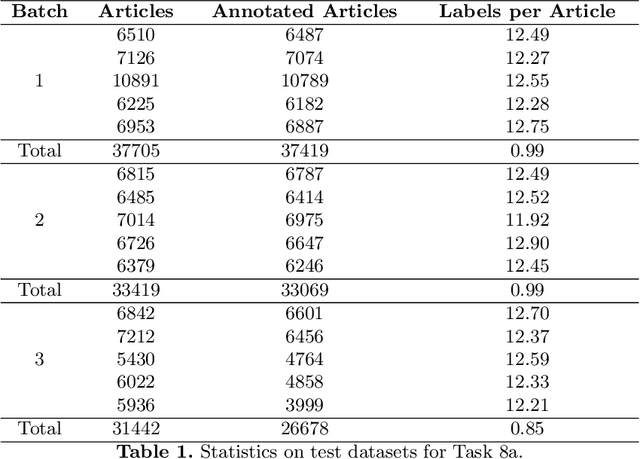

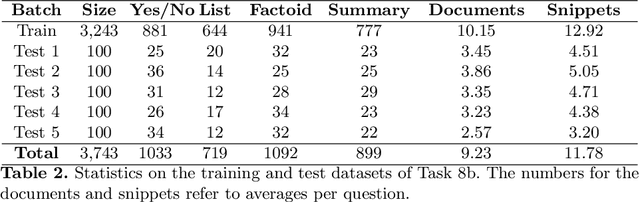
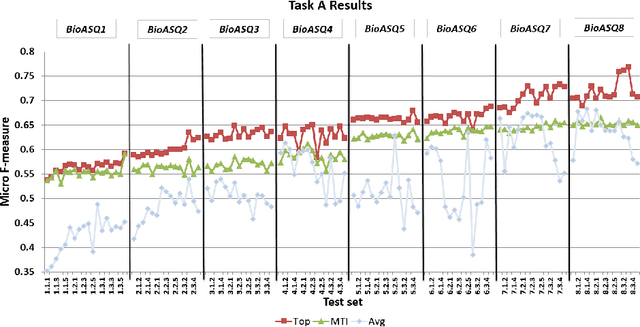
Advancing the state-of-the-art in large-scale biomedical semantic indexing and question answering is the main focus of the BioASQ challenge. BioASQ organizes respective tasks where different teams develop systems that are evaluated on the same benchmark datasets that represent the real information needs of experts in the biomedical domain. This paper presents an overview of the ninth edition of the BioASQ challenge in the context of the Conference and Labs of the Evaluation Forum (CLEF) 2021. In this year, a new question answering task, named Synergy, is introduced to support researchers studying the COVID-19 disease and measure the ability of the participating teams to discern information while the problem is still developing. In total, 42 teams with more than 170 systems were registered to participate in the four tasks of the challenge. The evaluation results, similarly to previous years, show a performance gain against the baselines which indicates the continuous improvement of the state-of-the-art in this field.
Semi-Supervised Tensor Factorization for Node Classification in Complex Social Networks
Jul 24, 2019
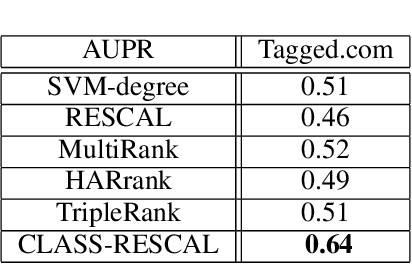


This paper proposes a method to guide tensor factorization, using class labels. Furthermore, it shows the advantages of using the proposed method in identifying nodes that play a special role in multi-relational networks, e.g. spammers. Most complex systems involve multiple types of relationships and interactions among entities. Combining information from different relationships may be crucial for various prediction tasks. Instead of creating distinct prediction models for each type of relationship, in this paper we present a tensor factorization approach based on RESCAL, which collectively exploits all existing relations. We extend RESCAL to produce a semi-supervised factorization method that combines a classification error term with the standard factor optimization process. The coupled optimization approach, models the tensorial data assimilating observed information from all the relations, while also taking into account classification performance. Our evaluation on real-world social network data shows that incorporating supervision, when available, leads to models that are more accurate.