 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLucky 52: How Many Languages Are Needed to Instruction Fine-Tune Large Language Models?
Paper and Code
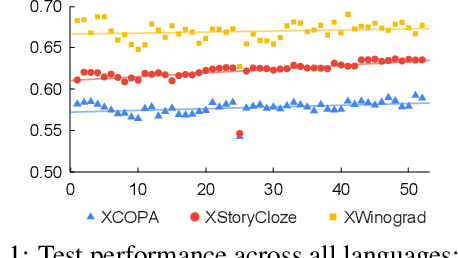



Fine-tuning large language models for multilingual downstream tasks requires a diverse set of languages to capture the nuances and structures of different linguistic contexts effectively. While the specific number varies depending on the desired scope and target languages, we argue that the number of languages, language exposure, and similarity that incorporate the selection of languages for fine-tuning are some important aspects to examine. By fine-tuning large multilingual models on 1 to 52 languages, this paper answers one question: How many languages are needed in instruction fine-tuning for multilingual tasks? We investigate how multilingual instruction fine-tuned models behave on multilingual benchmarks with an increasing number of languages and discuss our findings from the perspective of language exposure and similarity.