 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRAL: a Context-aware Croatian Abusive Language Dataset
Nov 11, 2022



In light of unprecedented increases in the popularity of the internet and social media, comment moderation has never been a more relevant task. Semi-automated comment moderation systems greatly aid human moderators by either automatically classifying the examples or allowing the moderators to prioritize which comments to consider first. However, the concept of inappropriate content is often subjective, and such content can be conveyed in many subtle and indirect ways. In this work, we propose CoRAL -- a language and culturally aware Croatian Abusive dataset covering phenomena of implicitness and reliance on local and global context. We show experimentally that current models degrade when comments are not explicit and further degrade when language skill and context knowledge are required to interpret the comment.
Not All Comments are Equal: Insights into Comment Moderation from a Topic-Aware Model
Sep 21, 2021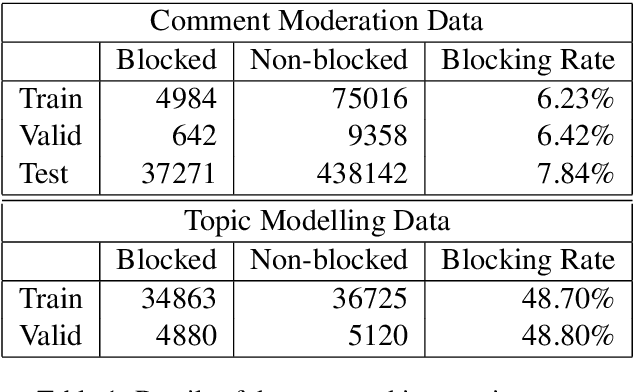
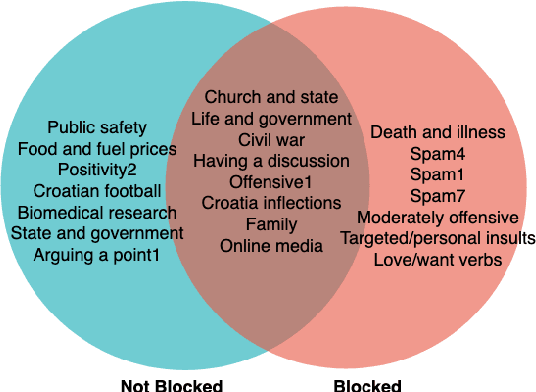
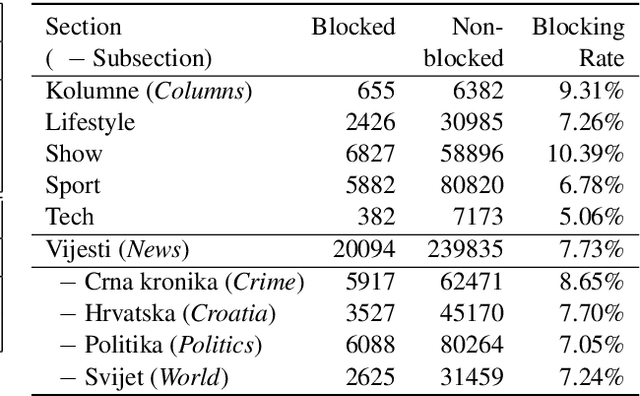
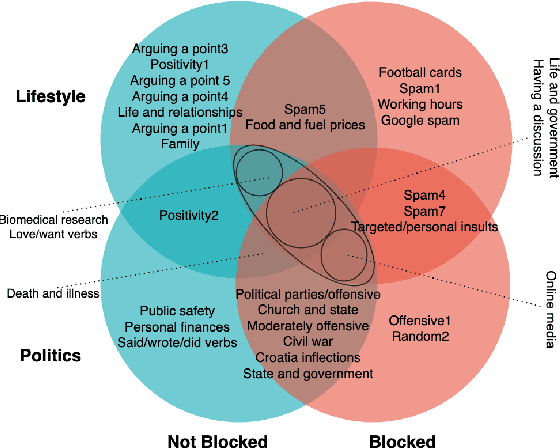
Moderation of reader comments is a significant problem for online news platforms. Here, we experiment with models for automatic moderation, using a dataset of comments from a popular Croatian newspaper. Our analysis shows that while comments that violate the moderation rules mostly share common linguistic and thematic features, their content varies across the different sections of the newspaper. We therefore make our models topic-aware, incorporating semantic features from a topic model into the classification decision. Our results show that topic information improves the performance of the model, increases its confidence in correct outputs, and helps us understand the model's outputs.
PANDORA Talks: Personality and Demographics on Reddit
Apr 27, 2020
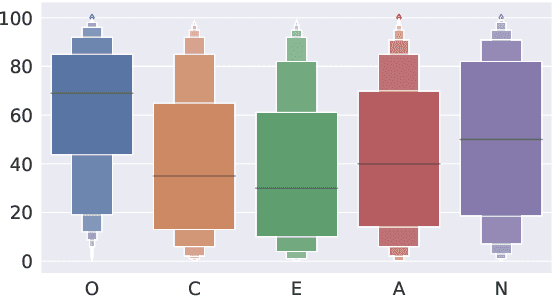
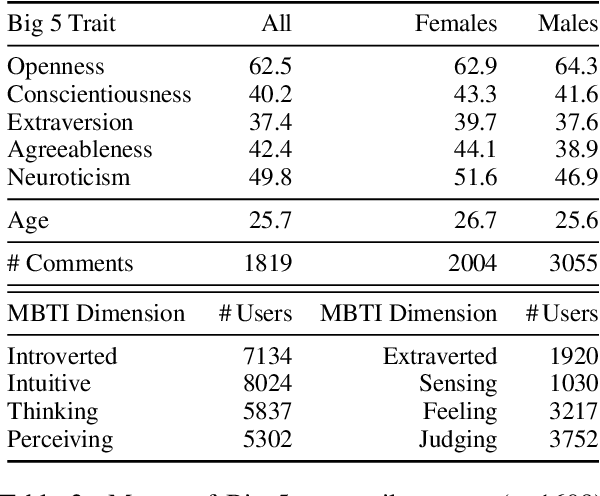
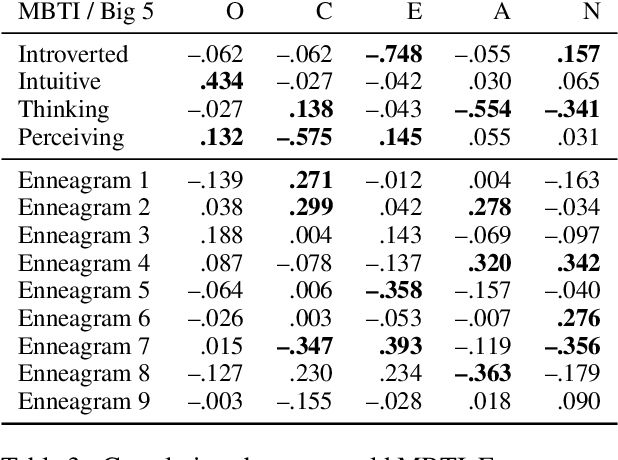
Personality and demographics are important variables in social sciences, while in NLP they can aid in interpretability and removal of societal biases. However, datasets with both personality and demographic labels are scarce. To address this, we present PANDORA, the first large-scale dataset of Reddit comments labeled with three personality models (including the well-established Big 5 model) and demographics (age, gender, and location) for more than 10k users. We showcase the usefulness of this dataset on three experiments, where we leverage the more readily available data from other personality models to predict the Big 5 traits, analyze gender classification biases arising from psycho-demographic variables, and carry out a confirmatory and exploratory analysis based on psychological theories. Finally, we present benchmark prediction models for all personality and demographic variables.