 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePANDORA Talks: Personality and Demographics on Reddit
Apr 27, 2020
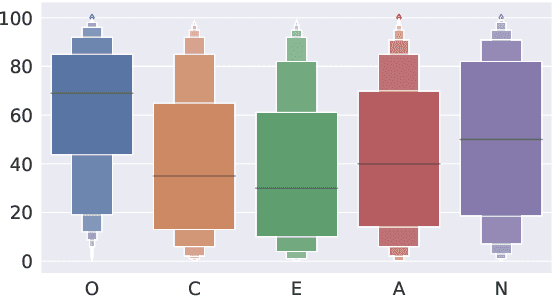
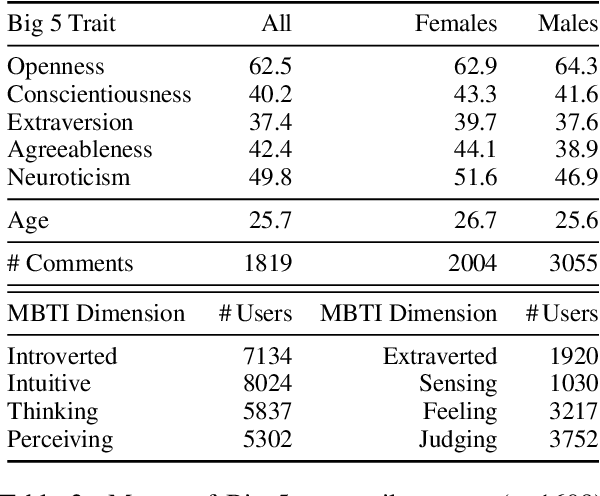
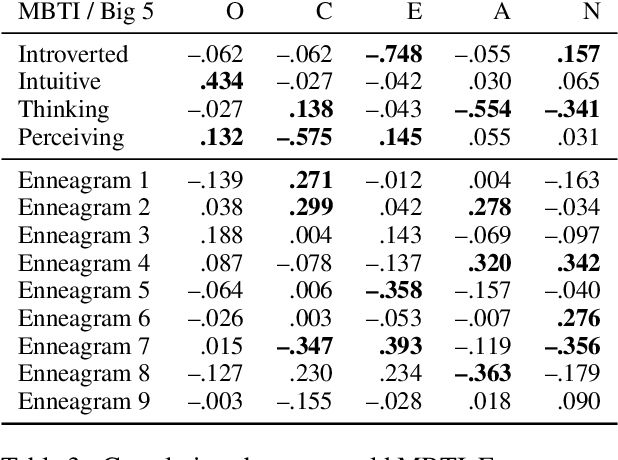
Personality and demographics are important variables in social sciences, while in NLP they can aid in interpretability and removal of societal biases. However, datasets with both personality and demographic labels are scarce. To address this, we present PANDORA, the first large-scale dataset of Reddit comments labeled with three personality models (including the well-established Big 5 model) and demographics (age, gender, and location) for more than 10k users. We showcase the usefulness of this dataset on three experiments, where we leverage the more readily available data from other personality models to predict the Big 5 traits, analyze gender classification biases arising from psycho-demographic variables, and carry out a confirmatory and exploratory analysis based on psychological theories. Finally, we present benchmark prediction models for all personality and demographic variables.