Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-CrossRE A Multi-Lingual Multi-Domain Dataset for Relation Extraction
Paper and Code

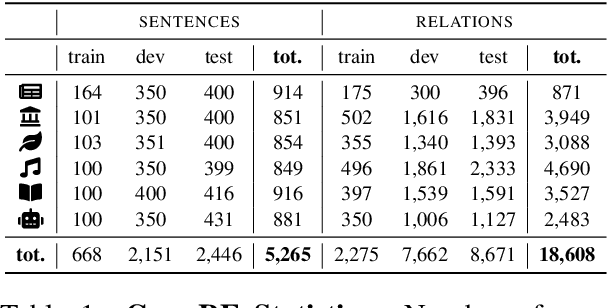
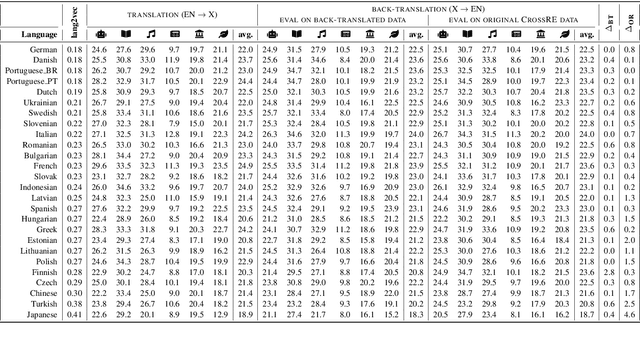

Most research in Relation Extraction (RE) involves the English language, mainly due to the lack of multi-lingual resources. We propose Multi-CrossRE, the broadest multi-lingual dataset for RE, including 26 languages in addition to English, and covering six text domains. Multi-CrossRE is a machine translated version of CrossRE (Bassignana and Plank, 2022), with a sub-portion including more than 200 sentences in seven diverse languages checked by native speakers. We run a baseline model over the 26 new datasets and--as sanity check--over the 26 back-translations to English. Results on the back-translated data are consistent with the ones on the original English CrossRE, indicating high quality of the translation and the resulting dataset.
* Accepted at NoDaLiDa 2023
View paper on
 OpenReview
OpenReview