 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Mitigating the Impact of Permanent Faults on a Systolic Array Based Neural Network Accelerator
Feb 17, 2018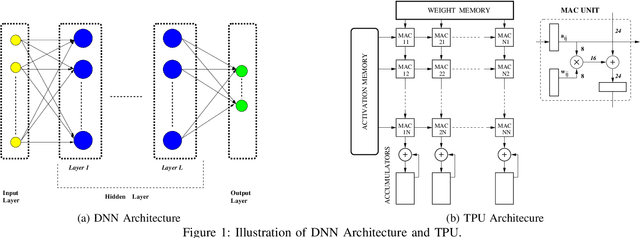

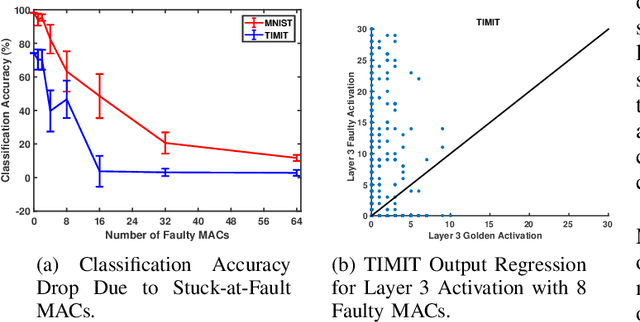
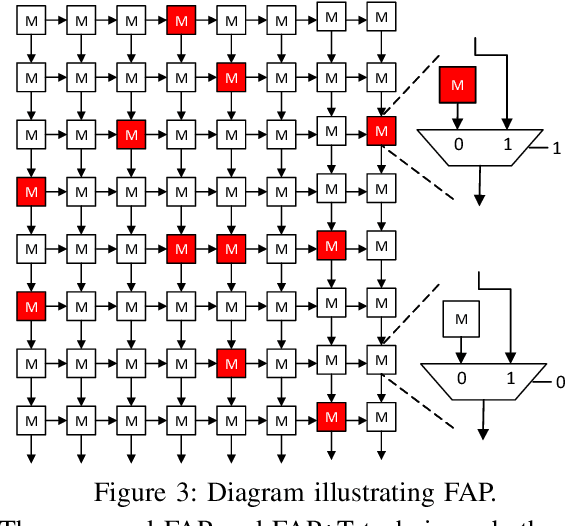
Due to their growing popularity and computational cost, deep neural networks (DNNs) are being targeted for hardware acceleration. A popular architecture for DNN acceleration, adopted by the Google Tensor Processing Unit (TPU), utilizes a systolic array based matrix multiplication unit at its core. This paper deals with the design of fault-tolerant, systolic array based DNN accelerators for high defect rate technologies. To this end, we empirically show that the classification accuracy of a baseline TPU drops significantly even at extremely low fault rates (as low as $0.006\%$). We then propose two novel strategies, fault-aware pruning (FAP) and fault-aware pruning+retraining (FAP+T), that enable the TPU to operate at fault rates of up to $50\%$, with negligible drop in classification accuracy (as low as $0.1\%$) and no run-time performance overhead. The FAP+T does introduce a one-time retraining penalty per TPU chip before it is deployed, but we propose optimizations that reduce this one-time penalty to under 12 minutes. The penalty is then amortized over the entire lifetime of the TPU's operation.
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Aug 22, 2017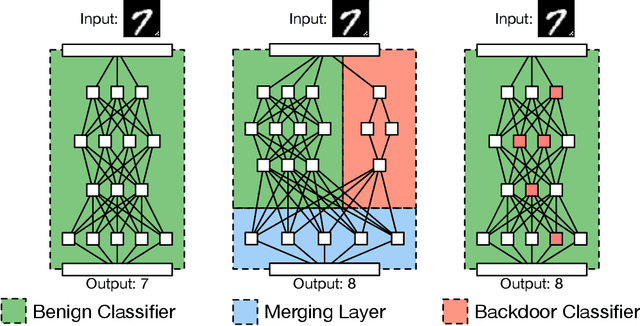
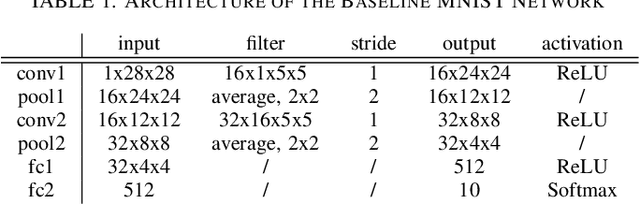
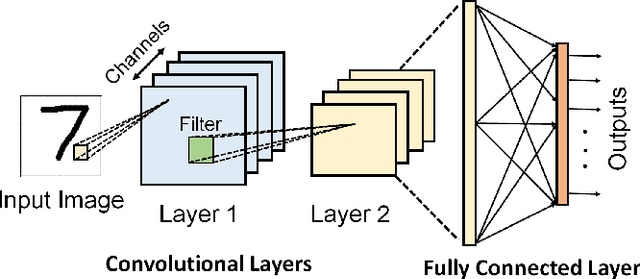
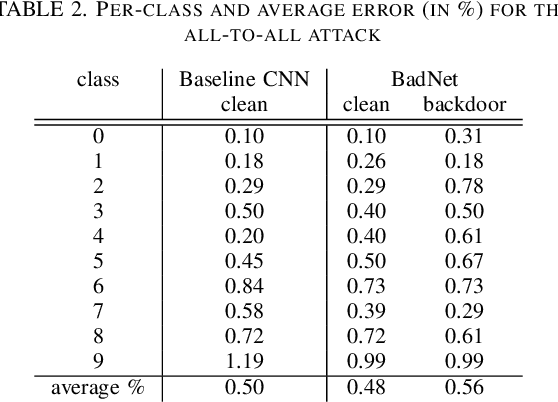
Deep learning-based techniques have achieved state-of-the-art performance on a wide variety of recognition and classification tasks. However, these networks are typically computationally expensive to train, requiring weeks of computation on many GPUs; as a result, many users outsource the training procedure to the cloud or rely on pre-trained models that are then fine-tuned for a specific task. In this paper we show that outsourced training introduces new security risks: an adversary can create a maliciously trained network (a backdoored neural network, or a \emph{BadNet}) that has state-of-the-art performance on the user's training and validation samples, but behaves badly on specific attacker-chosen inputs. We first explore the properties of BadNets in a toy example, by creating a backdoored handwritten digit classifier. Next, we demonstrate backdoors in a more realistic scenario by creating a U.S. street sign classifier that identifies stop signs as speed limits when a special sticker is added to the stop sign; we then show in addition that the backdoor in our US street sign detector can persist even if the network is later retrained for another task and cause a drop in accuracy of {25}\% on average when the backdoor trigger is present. These results demonstrate that backdoors in neural networks are both powerful and---because the behavior of neural networks is difficult to explicate---stealthy. This work provides motivation for further research into techniques for verifying and inspecting neural networks, just as we have developed tools for verifying and debugging software.
SafetyNets: Verifiable Execution of Deep Neural Networks on an Untrusted Cloud
Jun 30, 2017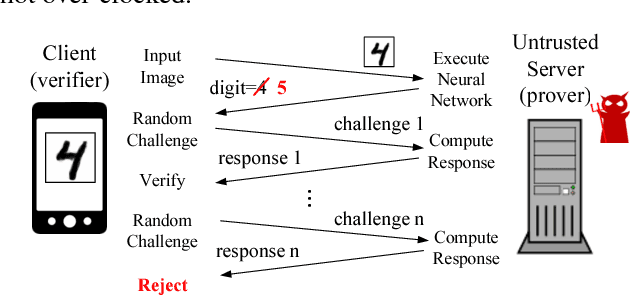
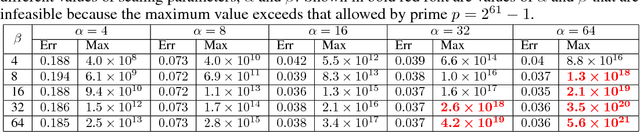
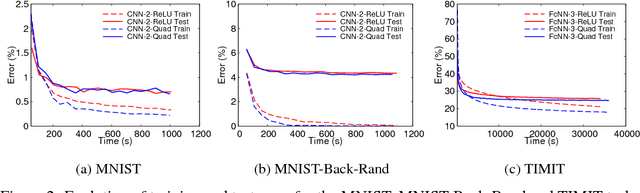

Inference using deep neural networks is often outsourced to the cloud since it is a computationally demanding task. However, this raises a fundamental issue of trust. How can a client be sure that the cloud has performed inference correctly? A lazy cloud provider might use a simpler but less accurate model to reduce its own computational load, or worse, maliciously modify the inference results sent to the client. We propose SafetyNets, a framework that enables an untrusted server (the cloud) to provide a client with a short mathematical proof of the correctness of inference tasks that they perform on behalf of the client. Specifically, SafetyNets develops and implements a specialized interactive proof (IP) protocol for verifiable execution of a class of deep neural networks, i.e., those that can be represented as arithmetic circuits. Our empirical results on three- and four-layer deep neural networks demonstrate the run-time costs of SafetyNets for both the client and server are low. SafetyNets detects any incorrect computations of the neural network by the untrusted server with high probability, while achieving state-of-the-art accuracy on the MNIST digit recognition (99.4%) and TIMIT speech recognition tasks (75.22%).