 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Mitigating the Impact of Permanent Faults on a Systolic Array Based Neural Network Accelerator
Paper and Code
Feb 17, 2018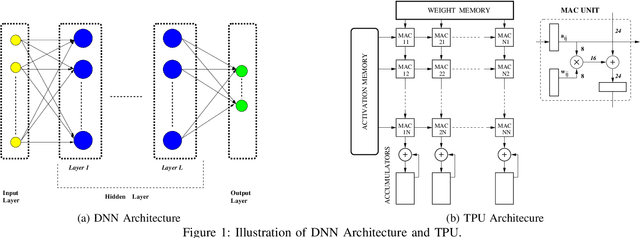

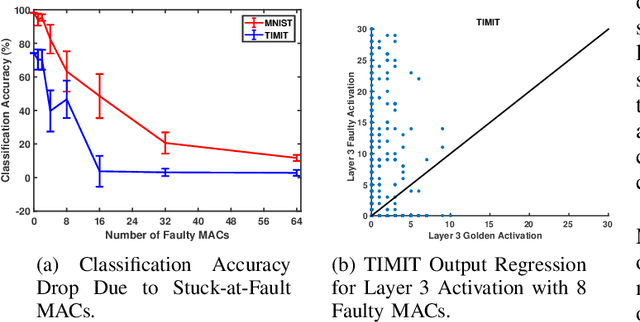
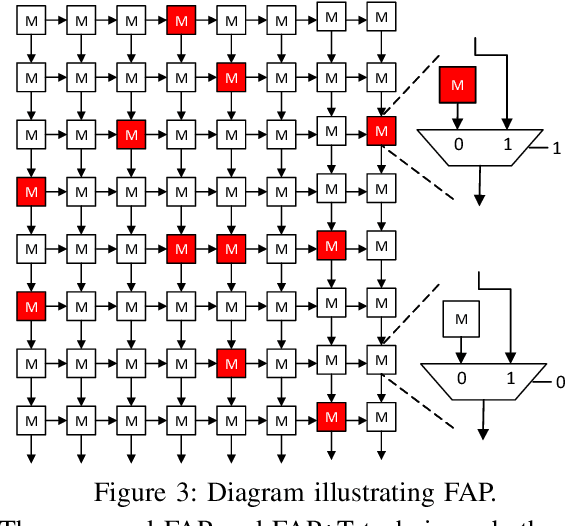
Due to their growing popularity and computational cost, deep neural networks (DNNs) are being targeted for hardware acceleration. A popular architecture for DNN acceleration, adopted by the Google Tensor Processing Unit (TPU), utilizes a systolic array based matrix multiplication unit at its core. This paper deals with the design of fault-tolerant, systolic array based DNN accelerators for high defect rate technologies. To this end, we empirically show that the classification accuracy of a baseline TPU drops significantly even at extremely low fault rates (as low as $0.006\%$). We then propose two novel strategies, fault-aware pruning (FAP) and fault-aware pruning+retraining (FAP+T), that enable the TPU to operate at fault rates of up to $50\%$, with negligible drop in classification accuracy (as low as $0.1\%$) and no run-time performance overhead. The FAP+T does introduce a one-time retraining penalty per TPU chip before it is deployed, but we propose optimizations that reduce this one-time penalty to under 12 minutes. The penalty is then amortized over the entire lifetime of the TPU's operation.