 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOBRA: Catastrophic Bit-flip Reliability Analysis of State-Space Models
Dec 22, 2025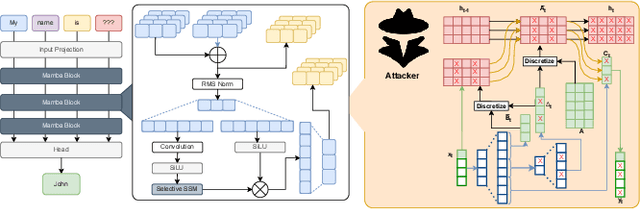
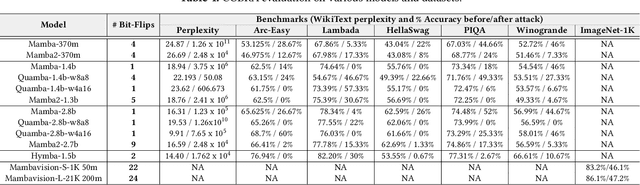
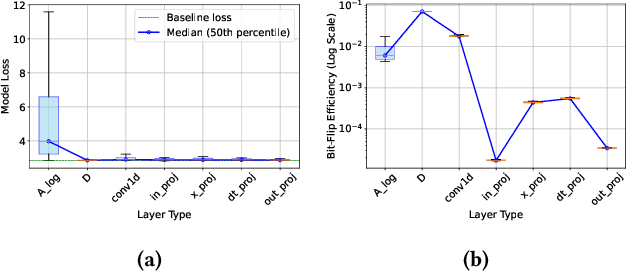
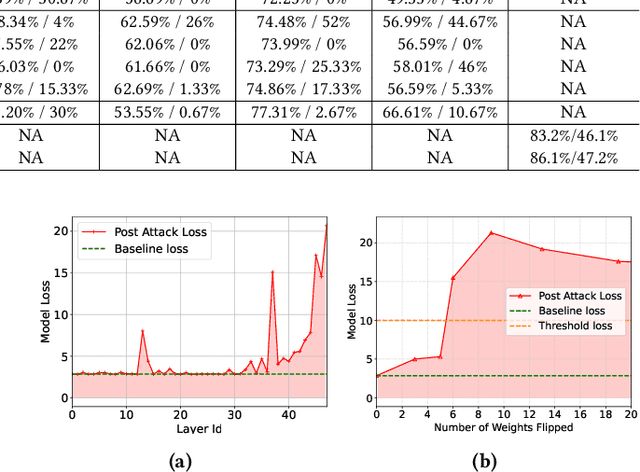
State-space models (SSMs), exemplified by the Mamba architecture, have recently emerged as state-of-the-art sequence-modeling frameworks, offering linear-time scalability together with strong performance in long-context settings. Owing to their unique combination of efficiency, scalability, and expressive capacity, SSMs have become compelling alternatives to transformer-based models, which suffer from the quadratic computational and memory costs of attention mechanisms. As SSMs are increasingly deployed in real-world applications, it is critical to assess their susceptibility to both software- and hardware-level threats to ensure secure and reliable operation. Among such threats, hardware-induced bit-flip attacks (BFAs) pose a particularly severe risk by corrupting model parameters through memory faults, thereby undermining model accuracy and functional integrity. To investigate this vulnerability, we introduce RAMBO, the first BFA framework specifically designed to target Mamba-based architectures. Through experiments on the Mamba-1.4b model with LAMBADA benchmark, a cloze-style word-prediction task, we demonstrate that flipping merely a single critical bit can catastrophically reduce accuracy from 74.64% to 0% and increase perplexity from 18.94 to 3.75 x 10^6. These results demonstrate the pronounced fragility of SSMs to adversarial perturbations.
AttentionBreaker: Adaptive Evolutionary Optimization for Unmasking Vulnerabilities in LLMs through Bit-Flip Attacks
Nov 21, 2024



Large Language Models (LLMs) have revolutionized natural language processing (NLP), excelling in tasks like text generation and summarization. However, their increasing adoption in mission-critical applications raises concerns about hardware-based threats, particularly bit-flip attacks (BFAs). BFAs, enabled by fault injection methods such as Rowhammer, target model parameters in memory, compromising both integrity and performance. Identifying critical parameters for BFAs in the vast parameter space of LLMs poses significant challenges. While prior research suggests transformer-based architectures are inherently more robust to BFAs compared to traditional deep neural networks, we challenge this assumption. For the first time, we demonstrate that as few as three bit-flips can cause catastrophic performance degradation in an LLM with billions of parameters. Current BFA techniques are inadequate for exploiting this vulnerability due to the difficulty of efficiently identifying critical parameters within the immense parameter space. To address this, we propose AttentionBreaker, a novel framework tailored for LLMs that enables efficient traversal of the parameter space to identify critical parameters. Additionally, we introduce GenBFA, an evolutionary optimization strategy designed to refine the search further, isolating the most critical bits for an efficient and effective attack. Empirical results reveal the profound vulnerability of LLMs to AttentionBreaker. For example, merely three bit-flips (4.129 x 10^-9% of total parameters) in the LLaMA3-8B-Instruct 8-bit quantized (W8) model result in a complete performance collapse: accuracy on MMLU tasks drops from 67.3% to 0%, and Wikitext perplexity skyrockets from 12.6 to 4.72 x 10^5. These findings underscore the effectiveness of AttentionBreaker in uncovering and exploiting critical vulnerabilities within LLM architectures.