 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbon-Efficient 3D DNN Acceleration: Optimizing Performance and Sustainability
Apr 14, 2025As Deep Neural Networks (DNNs) continue to drive advancements in artificial intelligence, the design of hardware accelerators faces growing concerns over embodied carbon footprint due to complex fabrication processes. 3D integration improves performance but introduces sustainability challenges, making carbon-aware optimization essential. In this work, we propose a carbon-efficient design methodology for 3D DNN accelerators, leveraging approximate computing and genetic algorithm-based design space exploration to optimize Carbon Delay Product (CDP). By integrating area-efficient approximate multipliers into Multiply-Accumulate (MAC) units, our approach effectively reduces silicon area and fabrication overhead while maintaining high computational accuracy. Experimental evaluations across three technology nodes (45nm, 14nm, and 7nm) show that our method reduces embodied carbon by up to 30% with negligible accuracy drop.
Kolmogorov-Arnold Network for Transistor Compact Modeling
Mar 19, 2025Neural network (NN)-based transistor compact modeling has recently emerged as a transformative solution for accelerating device modeling and SPICE circuit simulations. However, conventional NN architectures, despite their widespread adoption in state-of-the-art methods, primarily function as black-box problem solvers. This lack of interpretability significantly limits their capacity to extract and convey meaningful insights into learned data patterns, posing a major barrier to their broader adoption in critical modeling tasks. This work introduces, for the first time, Kolmogorov-Arnold network (KAN) for the transistor - a groundbreaking NN architecture that seamlessly integrates interpretability with high precision in physics-based function modeling. We systematically evaluate the performance of KAN and Fourier KAN for FinFET compact modeling, benchmarking them against the golden industry-standard compact model and the widely used MLP architecture. Our results reveal that KAN and FKAN consistently achieve superior prediction accuracy for critical figures of merit, including gate current, drain charge, and source charge. Furthermore, we demonstrate and improve the unique ability of KAN to derive symbolic formulas from learned data patterns - a capability that not only enhances interpretability but also facilitates in-depth transistor analysis and optimization. This work highlights the transformative potential of KAN in bridging the gap between interpretability and precision in NN-driven transistor compact modeling. By providing a robust and transparent approach to transistor modeling, KAN represents a pivotal advancement for the semiconductor industry as it navigates the challenges of advanced technology scaling.
Leveraging Highly Approximated Multipliers in DNN Inference
Dec 21, 2024



In this work, we present a control variate approximation technique that enables the exploitation of highly approximate multipliers in Deep Neural Network (DNN) accelerators. Our approach does not require retraining and significantly decreases the induced error due to approximate multiplications, improving the overall inference accuracy. As a result, our approach enables satisfying tight accuracy loss constraints while boosting the power savings. Our experimental evaluation, across six different DNNs and several approximate multipliers, demonstrates the versatility of our approach and shows that compared to the accurate design, our control variate approximation achieves the same performance, 45% power reduction, and less than 1% average accuracy loss. Compared to the corresponding approximate designs without using our technique, our approach improves the accuracy by 1.9x on average.
GNN4REL: Graph Neural Networks for Predicting Circuit Reliability Degradation
Aug 04, 2022

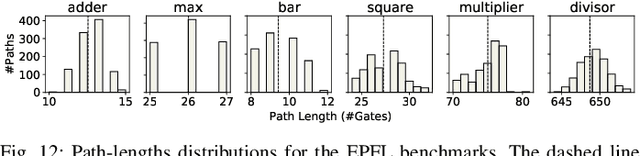

Process variations and device aging impose profound challenges for circuit designers. Without a precise understanding of the impact of variations on the delay of circuit paths, guardbands, which keep timing violations at bay, cannot be correctly estimated. This problem is exacerbated for advanced technology nodes, where transistor dimensions reach atomic levels and established margins are severely constrained. Hence, traditional worst-case analysis becomes impractical, resulting in intolerable performance overheads. Contrarily, process-variation/aging-aware static timing analysis (STA) equips designers with accurate statistical delay distributions. Timing guardbands that are small, yet sufficient, can then be effectively estimated. However, such analysis is costly as it requires intensive Monte-Carlo simulations. Further, it necessitates access to confidential physics-based aging models to generate the standard-cell libraries required for STA. In this work, we employ graph neural networks (GNNs) to accurately estimate the impact of process variations and device aging on the delay of any path within a circuit. Our proposed GNN4REL framework empowers designers to perform rapid and accurate reliability estimations without accessing transistor models, standard-cell libraries, or even STA; these components are all incorporated into the GNN model via training by the foundry. Specifically, GNN4REL is trained on a FinFET technology model that is calibrated against industrial 14nm measurement data. Through our extensive experiments on EPFL and ITC-99 benchmarks, as well as RISC-V processors, we successfully estimate delay degradations of all paths -- notably within seconds -- with a mean absolute error down to 0.01 percentage points.
Modeling and Predicting Transistor Aging under Workload Dependency using Machine Learning
Jul 08, 2022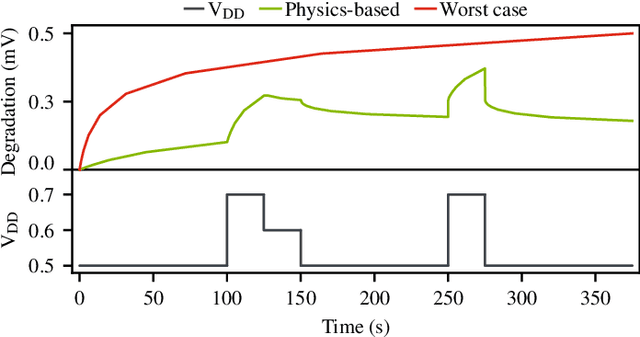
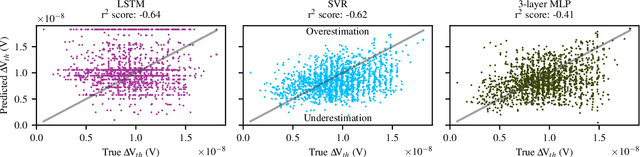
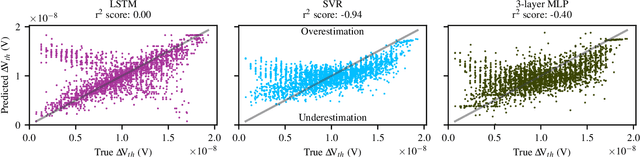
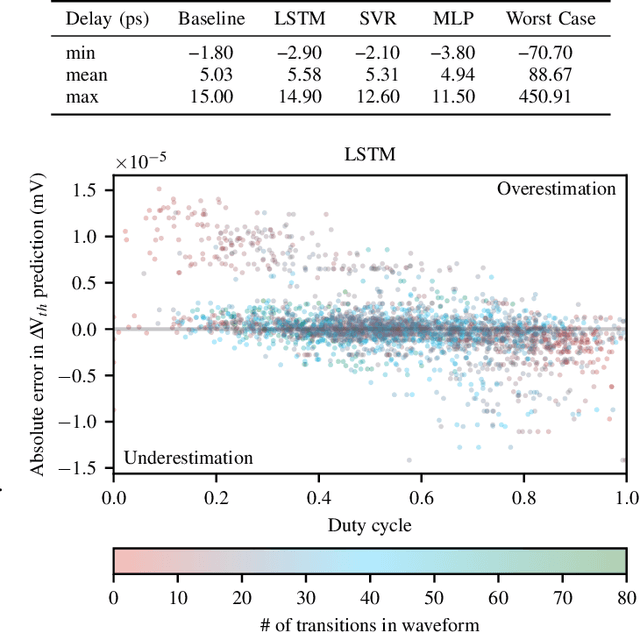
The pivotal issue of reliability is one of colossal concern for circuit designers. The driving force is transistor aging, dependent on operating voltage and workload. At the design time, it is difficult to estimate close-to-the-edge guardbands that keep aging effects during the lifetime at bay. This is because the foundry does not share its calibrated physics-based models, comprised of highly confidential technology and material parameters. However, the unmonitored yet necessary overestimation of degradation amounts to a performance decline, which could be preventable. Furthermore, these physics-based models are exceptionally computationally complex. The costs of modeling millions of individual transistors at design time can be evidently exorbitant. We propose the revolutionizing prospect of a machine learning model trained to replicate the physics-based model, such that no confidential parameters are disclosed. This effectual workaround is fully accessible to circuit designers for the purposes of design optimization. We demonstrate the models' ability to generalize by training on data from one circuit and applying it successfully to a benchmark circuit. The mean relative error is as low as 1.7%, with a speedup of up to 20X. Circuit designers, for the first time ever, will have ease of access to a high-precision aging model, which is paramount for efficient designs. This work is a promising step in the direction of bridging the wide gulf between the foundry and circuit designers.
Brain-Inspired Hyperdimensional Computing: How Thermal-Friendly for Edge Computing?
Apr 05, 2022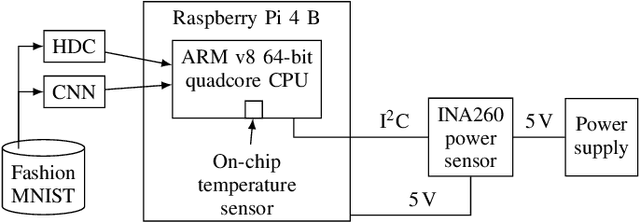
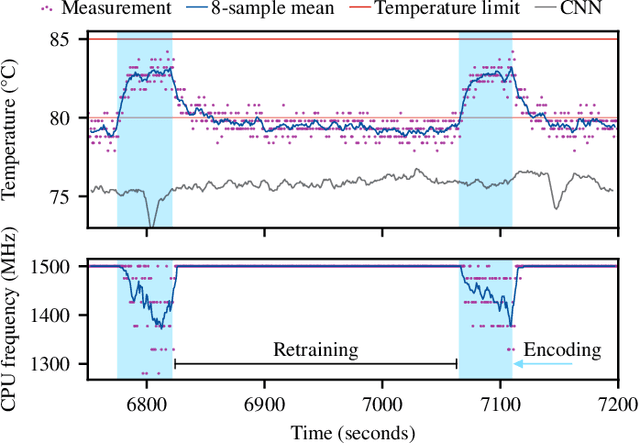
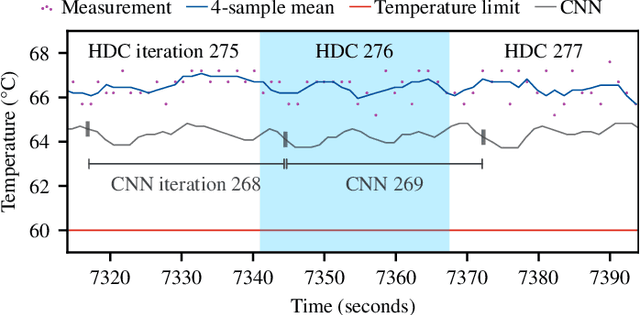
Brain-inspired hyperdimensional computing (HDC) is an emerging machine learning (ML) methods. It is based on large vectors of binary or bipolar symbols and a few simple mathematical operations. The promise of HDC is a highly efficient implementation for embedded systems like wearables. While fast implementations have been presented, other constraints have not been considered for edge computing. In this work, we aim at answering how thermal-friendly HDC for edge computing is. Devices like smartwatches, smart glasses, or even mobile systems have a restrictive cooling budget due to their limited volume. Although HDC operations are simple, the vectors are large, resulting in a high number of CPU operations and thus a heavy load on the entire system potentially causing temperature violations. In this work, the impact of HDC on the chip's temperature is investigated for the first time. We measure the temperature and power consumption of a commercial embedded system and compare HDC with conventional CNN. We reveal that HDC causes up to 6.8{\deg}C higher temperatures and leads to up to 47% more CPU throttling. Even when both HDC and CNN aim for the same throughput (i.e., perform a similar number of classifications per second), HDC still causes higher on-chip temperatures due to the larger power consumption.
Positive/Negative Approximate Multipliers for DNN Accelerators
Jul 20, 2021


Recent Deep Neural Networks (DNNs) managed to deliver superhuman accuracy levels on many AI tasks. Several applications rely more and more on DNNs to deliver sophisticated services and DNN accelerators are becoming integral components of modern systems-on-chips. DNNs perform millions of arithmetic operations per inference and DNN accelerators integrate thousands of multiply-accumulate units leading to increased energy requirements. Approximate computing principles are employed to significantly lower the energy consumption of DNN accelerators at the cost of some accuracy loss. Nevertheless, recent research demonstrated that complex DNNs are increasingly sensitive to approximation. Hence, the obtained energy savings are often limited when targeting tight accuracy constraints. In this work, we present a dynamically configurable approximate multiplier that supports three operation modes, i.e., exact, positive error, and negative error. In addition, we propose a filter-oriented approximation method to map the weights to the appropriate modes of the approximate multiplier. Our mapping algorithm balances the positive with the negative errors due to the approximate multiplications, aiming at maximizing the energy reduction while minimizing the overall convolution error. We evaluate our approach on multiple DNNs and datasets against state-of-the-art approaches, where our method achieves 18.33% energy gains on average across 7 NNs on 4 different datasets for a maximum accuracy drop of only 1%.
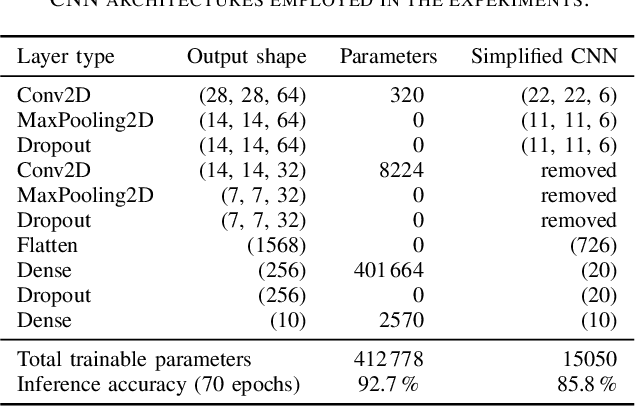
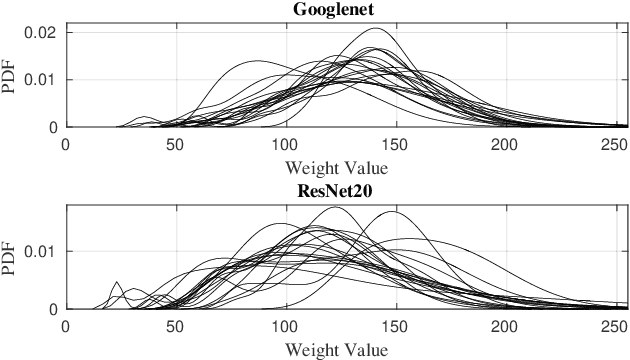
Reliability-Aware Quantization for Anti-Aging NPUs
Mar 08, 2021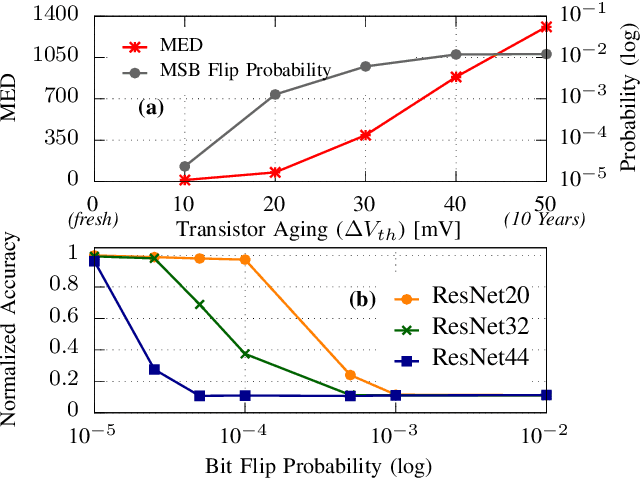
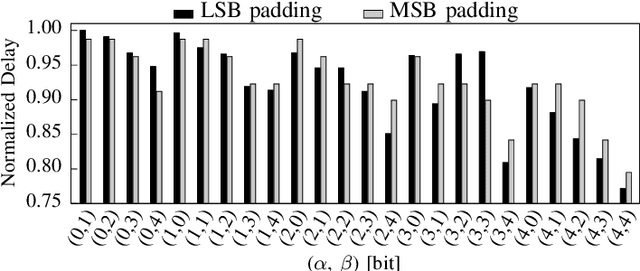
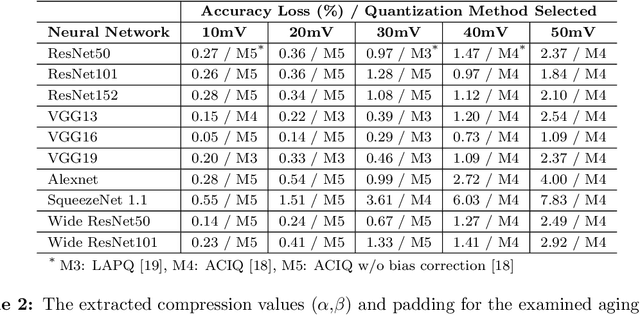
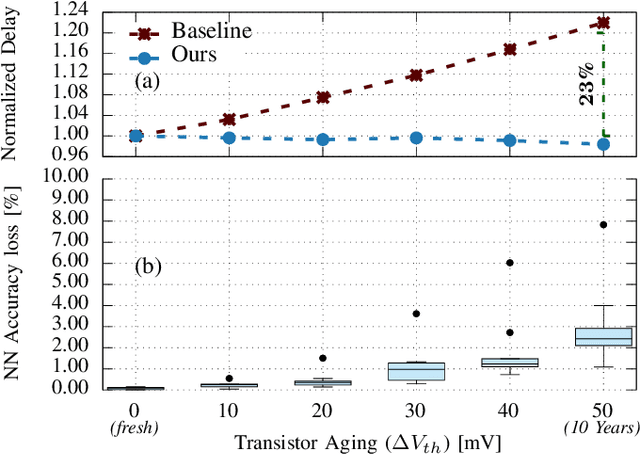
Transistor aging is one of the major concerns that challenges designers in advanced technologies. It profoundly degrades the reliability of circuits during its lifetime as it slows down transistors resulting in errors due to timing violations unless large guardbands are included, which leads to considerable performance losses. When it comes to Neural Processing Units (NPUs), where increasing the inference speed is the primary goal, such performance losses cannot be tolerated. In this work, we are the first to propose a reliability-aware quantization to eliminate aging effects in NPUs while completely removing guardbands. Our technique delivers a graceful inference accuracy degradation over time while compensating for the aging-induced delay increase of the NPU. Our evaluation, over ten state-of-the-art neural network architectures trained on the ImageNet dataset, demonstrates that for an entire lifetime of 10 years, the average accuracy loss is merely 3%. In the meantime, our technique achieves 23% higher performance due to the elimination of the aging guardband.
Control Variate Approximation for DNN Accelerators
Feb 18, 2021
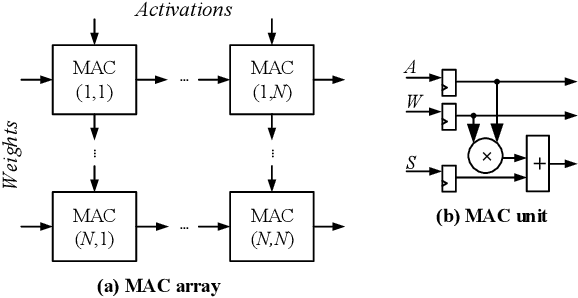
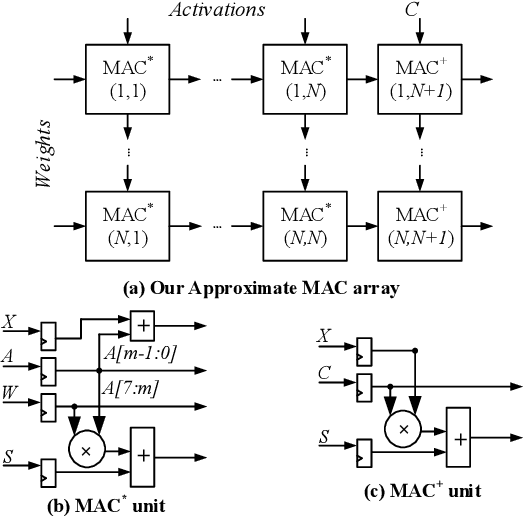
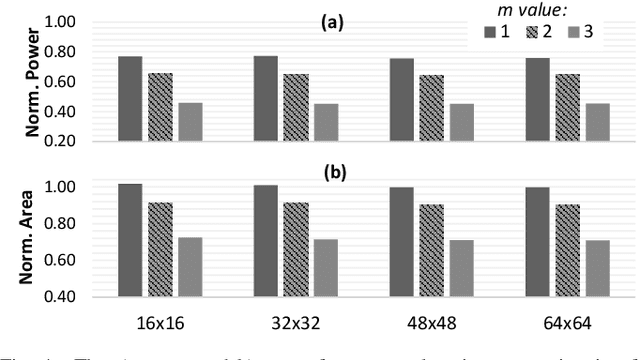
In this work, we introduce a control variate approximation technique for low error approximate Deep Neural Network (DNN) accelerators. The control variate technique is used in Monte Carlo methods to achieve variance reduction. Our approach significantly decreases the induced error due to approximate multiplications in DNN inference, without requiring time-exhaustive retraining compared to state-of-the-art. Leveraging our control variate method, we use highly approximated multipliers to generate power-optimized DNN accelerators. Our experimental evaluation on six DNNs, for Cifar-10 and Cifar-100 datasets, demonstrates that, compared to the accurate design, our control variate approximation achieves same performance and 24% power reduction for a merely 0.16% accuracy loss.
Hardware Trojan Detection Using Controlled Circuit Aging
Apr 21, 2020



This paper reports a novel approach that uses transistor aging in an integrated circuit (IC) to detect hardware Trojans. When a transistor is aged, it results in delays along several paths of the IC. This increase in delay results in timing violations that reveal as timing errors at the output of the IC during its operation. We present experiments using aging-aware standard cell libraries to illustrate the usefulness of the technique in detecting hardware Trojans. Combining IC aging with over-clocking produces a pattern of bit errors at the IC output by the induced timing violations. We use machine learning to learn the bit error distribution at the output of a clean IC. We differentiate the divergence in the pattern of bit errors because of a Trojan in the IC from this baseline distribution. We simulate the golden IC and show robustness to IC-to-IC manufacturing variations. The approach is effective and can detect a Trojan even if we place it far off the critical paths. Results on benchmarks from the Trust-hub show a detection accuracy of $\geq$99%.