 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Highly Approximated Multipliers in DNN Inference
Dec 21, 2024



In this work, we present a control variate approximation technique that enables the exploitation of highly approximate multipliers in Deep Neural Network (DNN) accelerators. Our approach does not require retraining and significantly decreases the induced error due to approximate multiplications, improving the overall inference accuracy. As a result, our approach enables satisfying tight accuracy loss constraints while boosting the power savings. Our experimental evaluation, across six different DNNs and several approximate multipliers, demonstrates the versatility of our approach and shows that compared to the accurate design, our control variate approximation achieves the same performance, 45% power reduction, and less than 1% average accuracy loss. Compared to the corresponding approximate designs without using our technique, our approach improves the accuracy by 1.9x on average.
Energy-efficient DNN Inference on Approximate Accelerators Through Formal Property Exploration
Jul 25, 2022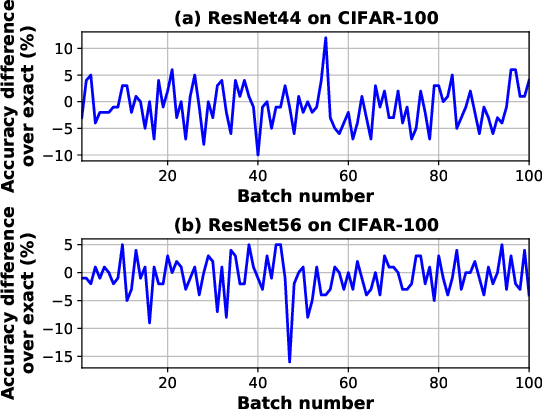
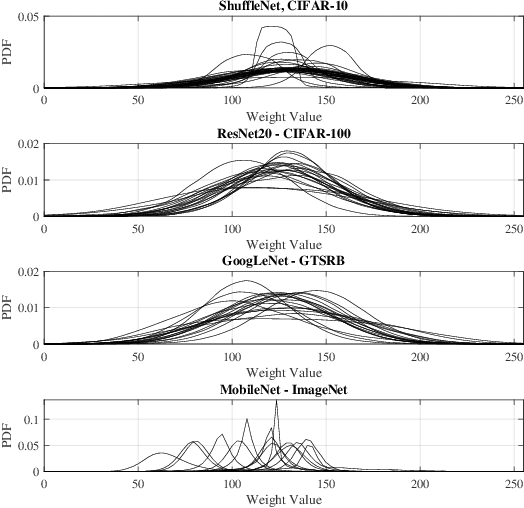
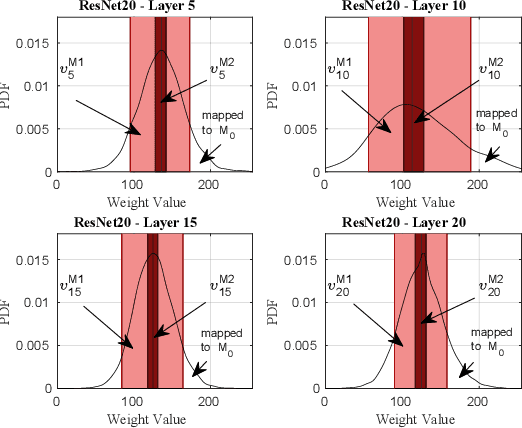
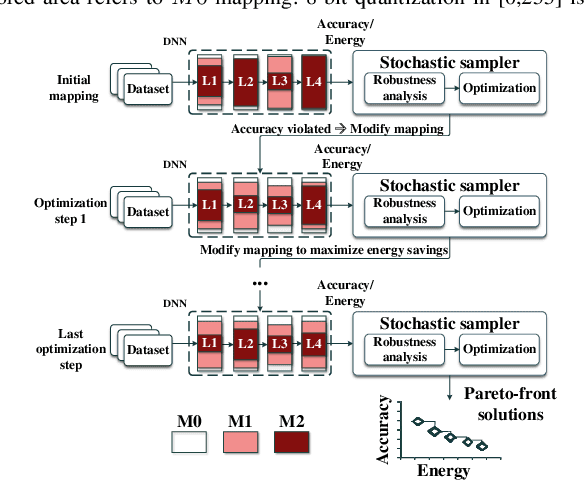
Deep Neural Networks (DNNs) are being heavily utilized in modern applications and are putting energy-constraint devices to the test. To bypass high energy consumption issues, approximate computing has been employed in DNN accelerators to balance out the accuracy-energy reduction trade-off. However, the approximation-induced accuracy loss can be very high and drastically degrade the performance of the DNN. Therefore, there is a need for a fine-grain mechanism that would assign specific DNN operations to approximation in order to maintain acceptable DNN accuracy, while also achieving low energy consumption. In this paper, we present an automated framework for weight-to-approximation mapping enabling formal property exploration for approximate DNN accelerators. At the MAC unit level, our experimental evaluation surpassed already energy-efficient mappings by more than $\times2$ in terms of energy gains, while also supporting significantly more fine-grain control over the introduced approximation.
Positive/Negative Approximate Multipliers for DNN Accelerators
Jul 20, 2021


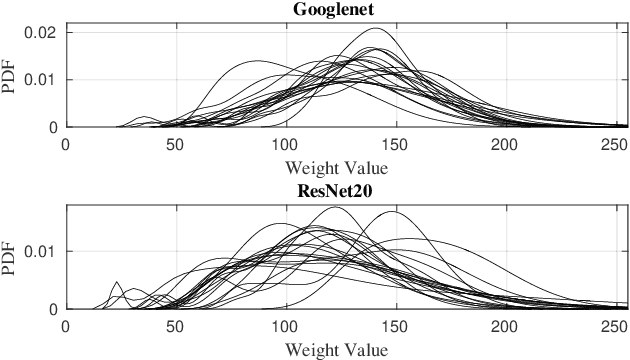
Recent Deep Neural Networks (DNNs) managed to deliver superhuman accuracy levels on many AI tasks. Several applications rely more and more on DNNs to deliver sophisticated services and DNN accelerators are becoming integral components of modern systems-on-chips. DNNs perform millions of arithmetic operations per inference and DNN accelerators integrate thousands of multiply-accumulate units leading to increased energy requirements. Approximate computing principles are employed to significantly lower the energy consumption of DNN accelerators at the cost of some accuracy loss. Nevertheless, recent research demonstrated that complex DNNs are increasingly sensitive to approximation. Hence, the obtained energy savings are often limited when targeting tight accuracy constraints. In this work, we present a dynamically configurable approximate multiplier that supports three operation modes, i.e., exact, positive error, and negative error. In addition, we propose a filter-oriented approximation method to map the weights to the appropriate modes of the approximate multiplier. Our mapping algorithm balances the positive with the negative errors due to the approximate multiplications, aiming at maximizing the energy reduction while minimizing the overall convolution error. We evaluate our approach on multiple DNNs and datasets against state-of-the-art approaches, where our method achieves 18.33% energy gains on average across 7 NNs on 4 different datasets for a maximum accuracy drop of only 1%.
Reliability-Aware Quantization for Anti-Aging NPUs
Mar 08, 2021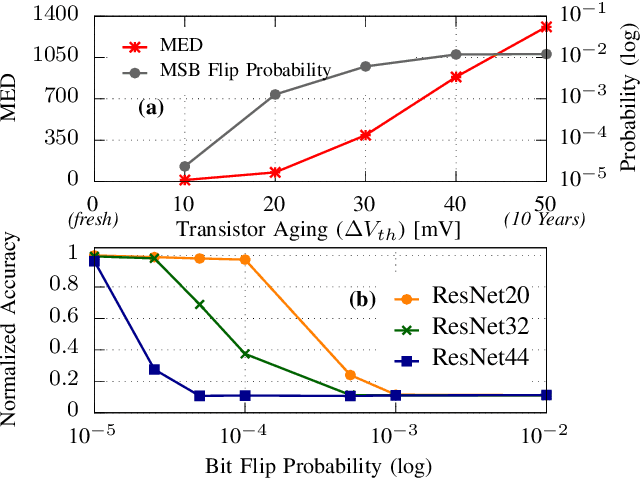
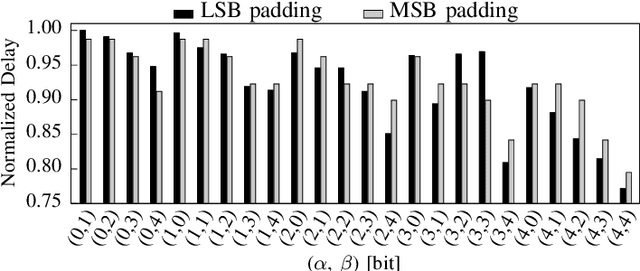
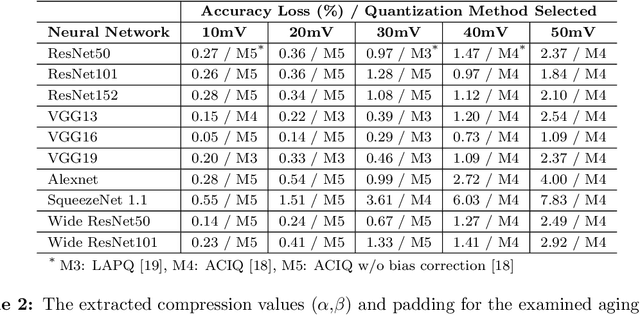
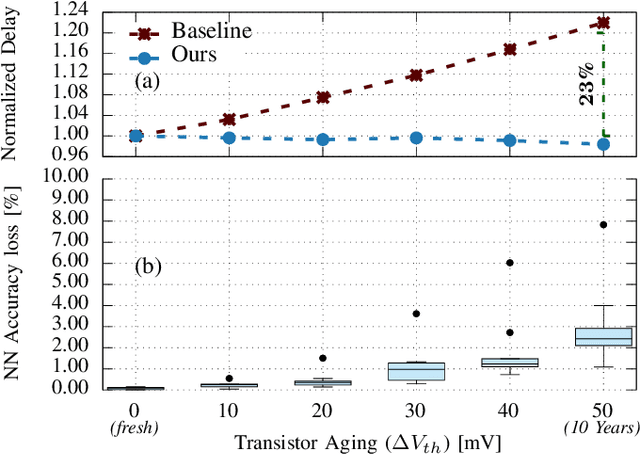
Transistor aging is one of the major concerns that challenges designers in advanced technologies. It profoundly degrades the reliability of circuits during its lifetime as it slows down transistors resulting in errors due to timing violations unless large guardbands are included, which leads to considerable performance losses. When it comes to Neural Processing Units (NPUs), where increasing the inference speed is the primary goal, such performance losses cannot be tolerated. In this work, we are the first to propose a reliability-aware quantization to eliminate aging effects in NPUs while completely removing guardbands. Our technique delivers a graceful inference accuracy degradation over time while compensating for the aging-induced delay increase of the NPU. Our evaluation, over ten state-of-the-art neural network architectures trained on the ImageNet dataset, demonstrates that for an entire lifetime of 10 years, the average accuracy loss is merely 3%. In the meantime, our technique achieves 23% higher performance due to the elimination of the aging guardband.
Control Variate Approximation for DNN Accelerators
Feb 18, 2021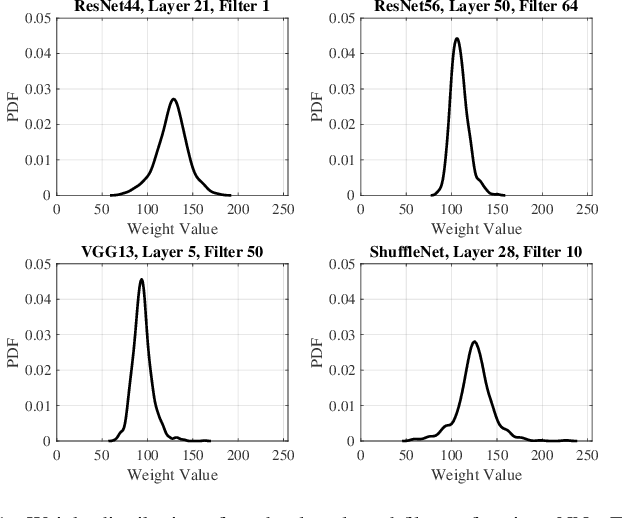
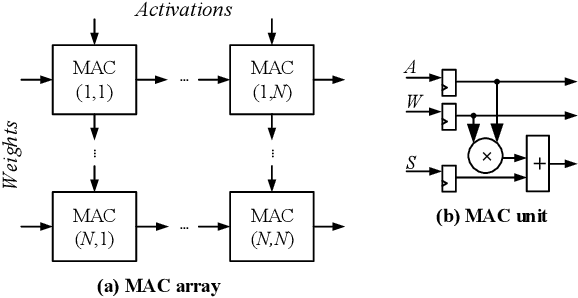
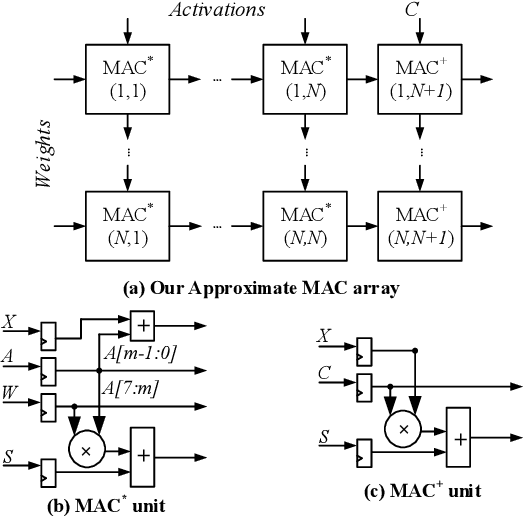
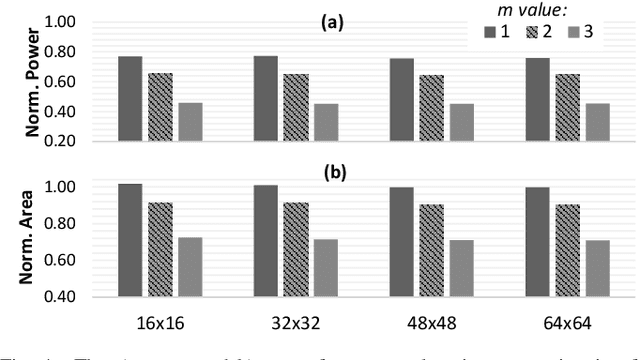
In this work, we introduce a control variate approximation technique for low error approximate Deep Neural Network (DNN) accelerators. The control variate technique is used in Monte Carlo methods to achieve variance reduction. Our approach significantly decreases the induced error due to approximate multiplications in DNN inference, without requiring time-exhaustive retraining compared to state-of-the-art. Leveraging our control variate method, we use highly approximated multipliers to generate power-optimized DNN accelerators. Our experimental evaluation on six DNNs, for Cifar-10 and Cifar-100 datasets, demonstrates that, compared to the accurate design, our control variate approximation achieves same performance and 24% power reduction for a merely 0.16% accuracy loss.